※本記事はOracleの下記Meetup「Oracle Big Data Jam Session」で実施予定の内容です。
※本ハンズオンの内容は事前に下記セットアップが完了していることを前提にしていますのでご参加いただける方々は必ず下記ガイドの手順を実行ください。
※本記事の内容は以下の動画でも説明しておりますのでよろしければご参照ください。
本記事の対象者
- これから機械学習を利用した開発をしていきたい方
- 機械学習のトレンド技術を知りたい方
- なるべく初歩的な内容から学習したい方
はじめに
前回のハンズオンでは、分類問題と回帰問題を通して、機械学習の基本的なワークフローと、そのワークフローに沿ったコード運びを学びました。ワークフローの各ステップでは必要に応じて様々な処理を実行することが理解できたかと思います。
データの前処理のフェーズでは欠損値の補完、カテゴリ変数の変換、相関関係の強い説明変数の確認など、いくつかのコードの実行を通して、雰囲気はご理解いただけたのではないでしょうか。
実際の分析の現場では、その他様々な定型処理や、ドメインナレッジから判断される処理を行い、統計分析にかけるデータセットを作りますので、実は、これまでにご紹介した処理はごくごく一部のパターンになります。
このように、機械学習の各ワークフローでは、大変な時間、工数、ノウハウをかけて行う処理が多々ありますので、せめて定型的な処理だけでも、ライブラリが自動的に判断して処理してくれると非常に便利ですよね。AutoMLとは、まさにそのようなニーズから生まれたコンセプトで、AI市場において、最も研究が盛んな技術分野と言ってもいいほど、日々、AutoMLの新しいライブラリがリリースされエンハンスされています。
そして昨今では、様々な統計処理のアイデアや学習手法を詰め込んだライブラリがOSSとして多数リリースされています。もはや、それらは単に抽象度の高い関数が詰め込まれたライブラリという枠を完全に超え、初学者でも機械学習の高度なノウハウを活用できるものになっています。
AutoMLは何を自動化してくれる?
AutoMLとは、Automated Machine Learningの略称です。「Automated」という名を冠しているということは、処理を自動化してくれるということです。ITにおいてAutomatedというキーワードは非常に魅力的なマジックワードですよね。特に機械学習や統計処理と聞くと難解な処理フローを思い浮かべがちですから、この分野では、その魅力は更に大きなものに感じます。そこで、本ハンズオンセミナーでは古典機械学習ライブラリの大御所であるscikit-learn系列のAutoMLライブラリAutoSklearnをベースに、その自動化のしくみを理解し、体験します。

まず、上図のような、機械学習の一般的なワークフローでいうと、赤色の部分は全てAutoMLの対象です。AutoSklearnに限らず、現在人気のあるその他のAutoMLライブラリもだいたい同じような感じです。なんだ、ほとんど全部自動でやってれるんだなと思われるかもしれませんが、残念ながら少し違います。ほとんどのフェーズがAutoMLの対象にはなりますが、各フェーズの中では様々な処理を行う必要があり、AutoMLで自動化できる処理はその一部ということになります。各フェーズの下にあるバーの割合が手動でプログラムを書かなければいけ部分(灰色)と自動化されている部分(赤色)の割合です。
誠に恐縮ながら、これは筆者の独断と偏見によるものだということをあらかじめご了承ください。ここまで自動化されているとは感じない方もいらっしゃると思います。
↓↓↓↓↓↓↓ あなたの記事の内容
こう見ると、「データの前処理」と「特徴量の前処理」の自動化の割合が極端に低いことがわかります。つまり、現在のAutoMLは魔法のツールではありませんし、この自動化に頼ればすべてOKなんてこともありません。ただ、これだけの自動化でも、一昔前と比較すると絶大なコード量の削減であることは間違いありません。したがって、どのフェーズでどのような処理を自動化してくれるのか、何を手動でやらなければいけないのかをちゃんと把握して利用すれば、非常に有用なツールなのです。
因みに、このワークフローには運用のフェーズが入っておりません。機械学習システムの運用は通常のシステムとは少し異なった面があり、それに対応するためのMLOpsのツールもたくさんリリースされています。kubeflow、airflow、mlflowなどが有名ですが、mlflowに関しては以前に実施した下記セッションで扱いましたのでご興味のある方は参照されてください。
具体的にはどんな処理が自動化できる?
ここから、AutoSklearnが自動化してくれる具体的な処理内容を各フェーズ毎に確認してゆきたいと思います。
データの前処理の自動化
機械学習にかけるデータは、一般的にデータレイクやRDB、その他NoSQL系のデータストアに収集されているデータを使います。ですが、多くの場合、この生データはそのままでは何も役に立たないデータです。
単なる数値、単語、文章の羅列であるこれらの生データを、分析シナリオに合わせて意味のある数値、つまり「特徴量」に変換することで、初めて統計アルゴリズムの関数に入力することができるようになります。
そのために最初にとりかかる処理が「データの前処理」です。データの前処理は、全部で何種類あって、各処理の仕方はこうこう、、、というような仕様めいた決まりはありませんが、ある程度の典型的な処理があり、AutoSklearnではそのうちの5つのタイプの処理を自動的に実行してくれます。
1) One-hot Encoding
機械学習で使われる統計アルゴリズムは言わば関数の集合体のようなものです。関数に入力できるデータは「量的データ」、つまり「数値」です。したがって、「質的データ」は「数値」に変換する必要があり、この変換処理のことをエンコーディングと呼んでいます。そして、エンコーディングには様々な方法があるのですが、その中でもよくつかわれる手法がワンホットエンコーディングです。
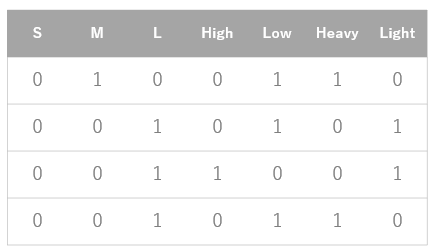
例えば、あるデータの中に飲み物のサイズがS, M, L表記であったとします。当然S, M, Lという単語のままでは関数に入力できませんのでこれをワンホットエンコーディングで数値に変換すると下図のように、該当クラスに数値の1でビットを立てるようなイメージになります。
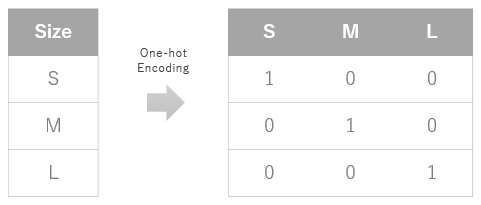
この処理を行うと、もとは一列だった特徴量が複数列に増えてしまいますのでデータサイズも大きくなりますが、これは必要不可欠な処理です。たいていのデータセットでは必ずと言っていいほど行うことになります。
scikit-learnではsklearn.preprocessingクラス配下に多数のエンコーディング関数があり、上述した one-hot encodingはsklearn.preprocessing.OneHotEncoderを使って実装します。AutoSklearnではこれが自動化されます。
2) 欠損値の補完
機械学習にかけるデータはいろんな収取のされ方をします。IoTのセンサーや、アンケートの集計結果などのデータでは欠損値ある場合が多くなります。不調だったり、故障したりしているセンサーは値を送信しませんし、アンケートでは年収、電話番号、体重などのプライベートな情報は空のまま提出される傾向があったりと、実データには欠損がつきものです。
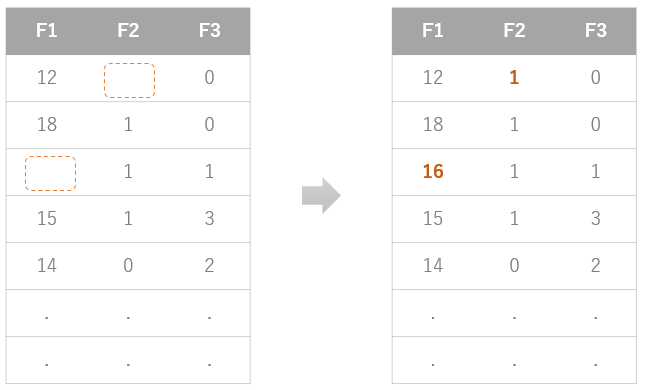
AutoSklearnでは大量のデータから、欠損を見つけ、そこに値を入力するという処理が自動化されています。どのような値で欠損値を補完するか?については、その特徴量の「平均値」、「中央値」、「頻出の値」で機械的に補完されます。
欠損値の補完はデータの欠損メカニズムを把握して適切な処理をしないと結果に偏りが出るおそれがあります。なので、このAutoSklearnの補完方法は「平均値」、「中央値」、「頻出の値」で補完しても問題ないことが分かっている場合に利用するということになり、その他のパターンでは欠損値を補完するコードを書く必要があります。
Scikit-learnで手動で行う場合は下記クラスを使って実装しますが、AutoSklearnでは自動化されます。
- sklearn.preprocessing.Imputer
3) 不均衡なデータセットへの対応
機械学習では、偏ったデータを学習処理にかけることは絶対に禁物です。例えば、ネコとトラを分類する問題にネコのサンプル数1000、トラのサンプル数100で学習してもモデルの精度は期待できないでしょう。トラのサンプル数がネコのものと比較して少なすぎるからです。この場合、とりえる主要な手法は3つあります。
-
アンダーサンプリング
多数派(ネコ1000件)のサンプル数を削除し、少数派(トラ100件)に合わせる手法です。多数派のデータ削除の過程で、重要なサンプルが欠損しバイアスが発生する可能性があります。その場合、バイアスを除去するような追加の処理が必要となります。 -
オーバーサンプリング
少数派(トラ100件)のサンプル数を複製して多数派(ネコ1000件)のサンプル数に合わせます。無秩序にサンプルを複製してもデータセットに新しいバリエーションを持たせることができませんので、その対処法としてSMOTE (Synthetic Minority Oversampling Technique)という手法が使われます。SMOTEとは、ランダムサンプリングのデータと、k近傍法のアルゴリズムで求められたデータにより、合成データを作成する方法です。 -
クラスの重み付け
少数派クラスのサンプルに重み付けをして、少数派データの学習感度を高めるようにします。具体的には、目的関数の誤差に対してペナルティを与え、少数派のデータの学習を重視した学習処理を行います。機械学習では正解値と予測値の誤差が小さくなるまで学習を続けなければいけません。したがって、算出された誤差にペナルティを与える(実際よりも誤差が大きく設定される)ということは、より厳しい環境で学習をするということになりますので、それだけ精度があがることが期待できます。
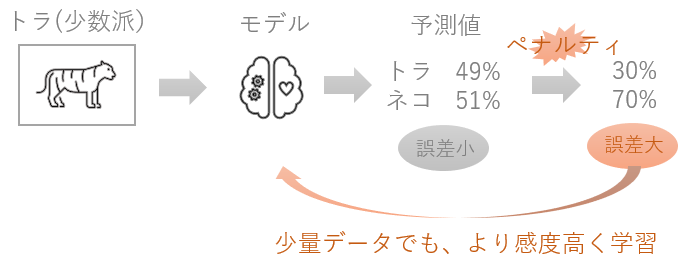
上図の例で説明すると、少数データしかないトラを49%の確率でトラ、51%の確率でネコだと誤分類してしまったとします。49%という値は精度としては悪いですが、それでもあと2%高ければ51%の確率でトラと予測し、正解できていたということになります。ですが、ここでペナルティがあたえられ、49%から30%まで下げられてしまいます。ペナルティが与えられてしまったので頑張って学習しなければモデルの精度はあがりません。このようにして、「少数派のデータを学習するときに間違えないようにする」というモチベーションを大きくします。それと同時に、「多数派のデータを学習するときに間違えないようにする」というモチベーションを小さくするということもします。これが重み調整のイメージです。
Scikit-learnで手動で行う場合は、該当アルゴリズムの引数 class_weight で上述の3タイプのうちどれかを指定しますが、AutoSklearnではクラスの重み付けのみが自動化されます。
4) スケーリング
機械学習にかけるデータの各特徴量は単位が異なったり、分布の範囲が異なることが多々あります。それをそのまま学習にかけると、関数の中での計算ステップ数が多くなってしまったり、モデルの精度が悪くなったりということが起こります。そのため、データの前処理で、特徴量間のスケールを揃える処理を行います。元のデータの分布の特徴は変えずに、分布する範囲を変えるというイメージです。例えば、体重と身長のデータセットがあるとします。両者は単位も違えば分布の範囲も当然異なります。このようなデータを何の前処理もせずそのまま機械学習にかけてしまうと上述したような問題が発生するためスケーリングを行って分布の範囲を揃えるということをします。
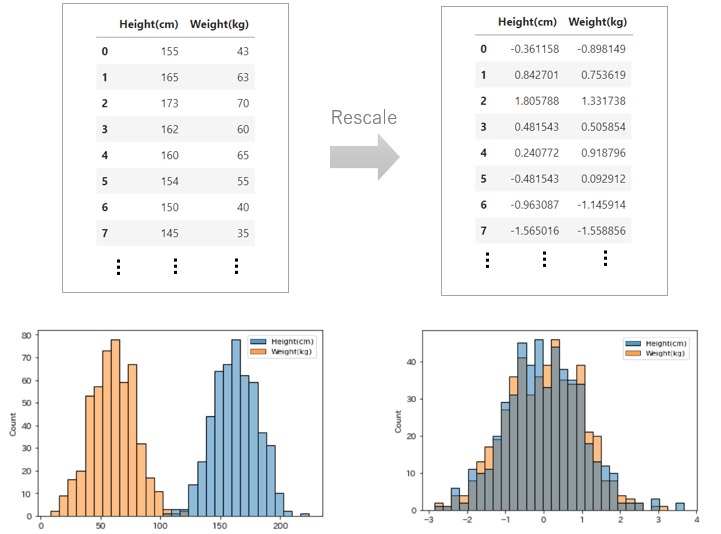
例えば、上図の上段左のように、人の体重と、身長のデータがあったとします。体重の単位はkgですし、身長はcmと両者は異なります。このようなデータを大量に集めると、たいていは標準分布に従いますが、体重と身長では、分布の範囲は上図の下段左のように大きく異なるでしょう。このような場合に、分布の範囲を揃えるための処理としてスケーリングを行います。この処理を行うと、上図の上段右のように、体重と身長の値の分布が似たような範囲に収まっていることがわかります。元のデータと比較すると、分布の範囲は変更されていますが、分布の特徴はもちろん変わらず標準分布のままです。上図の下段右のチャートで確認するとわかりやすいですね。
このスケーリングは様々な手法があり、そのデータの分布に応じて使い分けることをします。一般的にはNormalize(正規化)、Standardize(標準化)が非常によく使われ、AutoSklearnではNormalize、Standardize、abstract_rescaling、robust scaler、min_max_scalerといった計算方法が自動判別されされ処理されます。
Scikit-learnで手動で行う場合は下記クラス配下の関数を使って実装しますが、AutoSklearnでは自動化されます。
- sklearn.preprocessing
5) バリアンスの閾値設定による不要な特徴量の削除
機械学習は、複数特徴量間の分布の規則性を統計アルゴリズムが学習することによってはじめて成り立ちます。しかし、大量に収集したデータの中には、他の特徴量とは何の関係もなく分布したり、ターゲットにも何も影響しない特徴量を含む場合が多くあります。そのような特徴量はそれほど価値を提供せずむしろ不要な複雑さを招くため、学習データから削除する必要があります。その代表格が「定数(および定数に近い分布をとる特徴量)」です。他の特徴量がいろいろな値に分布している中、その影響を全く受けずに、また影響を全く与えずに、ただ一定の値をとり続ける定数を学習する意味はありません。
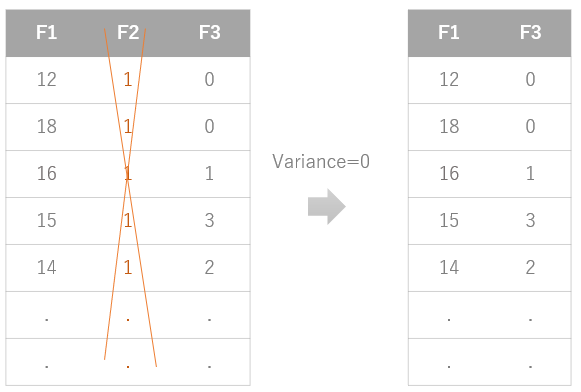
同じ値をとり続ける変数は目検でもすぐに見つけられそうですが、時として数千の特徴量を扱う場合は目検というわけにはいきません。また、ごくごく微少な値で変化する定数に近い特徴量をどう見つければいいでしょうか。その手法として特徴量の「バリアンス」を計算する方法があります。バリアンスとは「分散」や「ばらつき」という意味です。つまりバリアンスがゼロということは「ばらつき」がゼロということになるので、いわゆる定数ということになります。AutoSklearnではこのように、バリアンスに閾値を設けて、定数および定数に近い特徴量を自動的に削除することができます。
Scikit-learnで手動で行う場合は下記関数を使って実装しますが、AutoSklearnでは自動化されます。
- sklearn.feature_selection.VarianceThreshold
以上、AutoSklearnで自動的に処理してくれる「データの前処理」の説明でした。当然、これらは数ある手法の中のほんの一部です。実際には現場の担当者の知識と経験により、力業で乗り切っているというのが現状だと思われます。
特徴量の前処理の自動化
「データの前処理」が完了すると、始めは歪だった生データがずいぶんデータセットらしくなってきます。こうしてCSVなどの表形式にまとまったデータが出来上がると、すぐに機械学習にかけたくなりますが、やみくもにそのようなことをしてもいい結果は生まれません。
そもそも分析シナリオに必要な特徴量が揃っているのか?足りなければ、元の特徴量から新たに作り出すことができそうか?追加でデータを取得する必要はないのか?分析のシナリオを変更をしなければならないのではないか?などの試行錯誤を経て、最終的に機械学習にかけるデータセットが決まってきます。
データサイエンティストと呼ばれている方々は自身の経験と知識から得られたノウハウでこの特徴量の設計を行います。知識量、作業量ともに大変な工数です。そのナレッジのうち、定型的に処理できるいくつかの手法をAutoMLでは自動化します。
このパートでは難解に感じる計算式や統計手法の名称が多々でてきますが、一歩ひいて、全体を俯瞰して見ると、実は非常にシンプルなことをやっているということがわかります。
機械学習の本質は「必要最低限かつ有効な特徴量のみを学習する」という言葉につきます。したがって、大量に集めたデータから不要な特徴量は削除し、必要な(有効な)特徴量は残す、もしくは元データから新たに作り出すということをしています。
もっとありていに言ってしまうと、特徴量の前処理とは、「表形式のデータをコネコネといじくりまわして、列を追加したり削除したりする」だけです。そのいじくりまわすための様々な処理には、難解な名称がつけられていて、その処理内容を理解するには実際に、統計処理の知識が必要になるので難解に感じるという構図です。ですので、ここでは、まずざっくりと「ようはこんな感じの処理をしています」というイメージを理解するというところを目的として下記を読み進めていただければと思います。
行列分解(Matrix decomposition)
例えば、下図左のような年齢、体重、身長、健康診断評価の特徴量がまとまったデータがあったとします。このデータからある人が健康的であるかどうかを推論するモデルを作るとすると、最終的にどのようなデータセットで学習を始めればいいでしょうか?
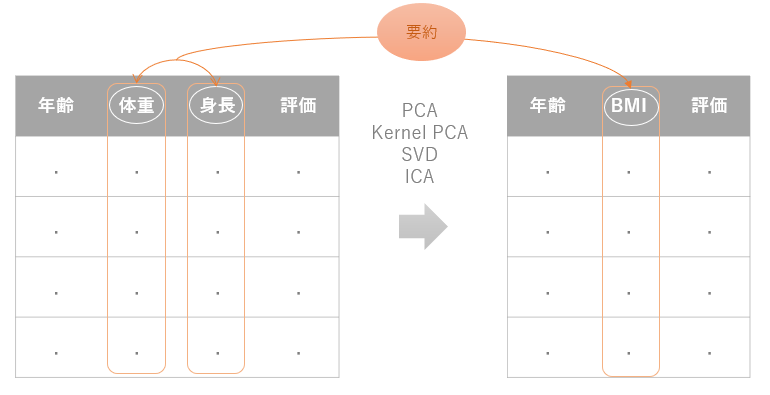
もちろん、このままのデータを学習にかけてもよさそうですが、ここで機械学習の本質に戻りましょう。「必要最低限かつ有効な特徴量のみを学習する」ということでした。
この例でいうと、体重と身長という特徴量からBMI(ボディマス指数)という肥満度を表す特徴量を作ることができます。これにより、体重、身長という二つの特徴量がBMIという一つの特徴量に要約されています。しかも健康度を表す指標としてはBMIのほうが有効とも言えますよね。
上述した内容はあくまでも要約のイメージです。実際に要約の処理に使われる手法は、BMIを計算するような具体的な公式ではなく統計的なアプローチで要約する特徴量を作り出します。それが行列分解をベースとしたPCA、カーネルPCA、Truncated SVD、ICAと呼ばれる手法です。これらは次元削減法と呼ばれる手法で、文字通り、特徴量の次元(数)の削減に効果をもたらします。
Scikit-learnで手動で行う場合は各手法に対応した下記クラスを使って実装しますが、AutoSklearnではこれらが自動化されます。
- sklearn.decomposition.PCA
- sklearn.decomposition.KernelPCA
- sklearn.decomposition.TruncatedSVD
- sklearn.decomposition.FastICA
単変量特徴量選択(Univariate feature selection)
単変量特徴量選択では、各特徴量とターゲットとの間に顕著な関連性があるかどうかを評価し、高い関連性を持った特徴量は残し、低いものは削除するという手法です。
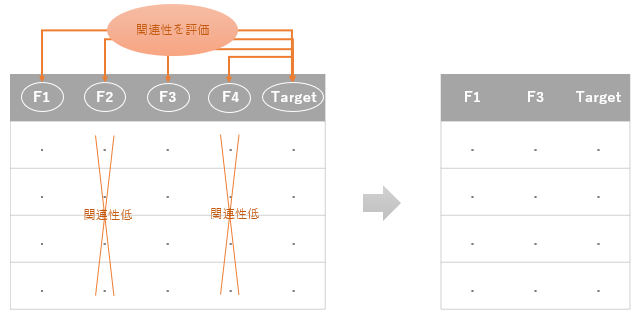
他の方法は複数の特徴量を同時に評価するものが多い中、この方法は単変量に対する処理、つまり、単一の特徴量とターゲットの関連性を順次評価していき、最終的に全特徴量を評価することになります。他の特徴量とセットでないと意味を持たないような特徴量も切り捨てられます。
そして、その評価の手法が、カイ二乗検定、相互情報量、ANOVA F値と呼ばれる手法などがあります。
Scikit-learnで手動で行う場合は各手法に対応した下記クラスを使って処理しますが、AutoSklearnではこれらが自動化されます。
- sklearn.feature_selection.mutual_info_regression
- sklearn.feature_selection.f_regression
- sklearn.feature_selection.chi2
- sklearn.feature_selection.f_classif
- sklearn.feature_selection.mutual_info_classif
分類ベースの特徴量選択
こちらの手法は、特徴量の選択に機械学習の分類モデルを適用し、複数ある特徴量を類似しているカテゴリに分類することで、特徴量の次元削減を行います。
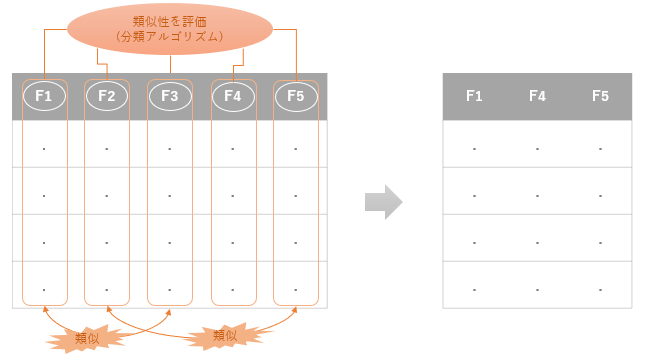
この類似しているカテゴリを探索する手法として機械学習の分類アルゴリズムではおなじみのサポートベクターマシンを使います。
Scikit-learnで手動で行う場合は下記クラスを使って実装しますが、AutoSklearnでは自動化されます。
- sklearn.svm.LinearSVC
特徴量クラスタリング(FeatureAgglomeration)
こちらの手法も、特徴量の選択に機械学習を応用したものです。上述した手法は分類モデルを適用したものですが、こちらはクラスタリングのモデルを適用し、類似度の高い特徴量同士をグルーピングして全体の特徴量の次元を削減します。
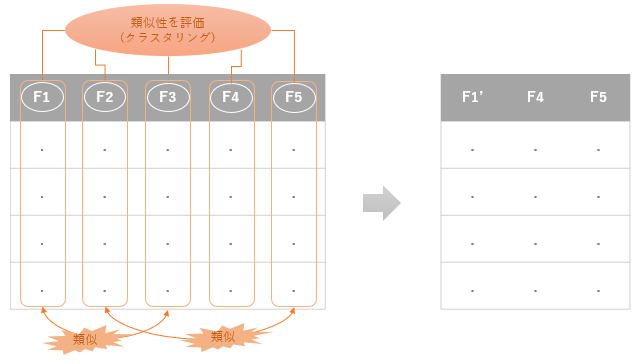
この「類似度」をどう評価するかというと、階層的クラスタリングと呼ばれるクラスター分析のモデルを適用します。
Scikit-learnのライブラリでは下記クラスを使って実装しますが、AutoSklearnでは自動化されます。
- sklearn.cluster.FeatureAgglomeration
統計処理では、複数のデータの分布(この場合、複数の特徴量)の類似性を評価するために「距離」を計測するという手法がよく登場します。この「距離」というのは一般的にイメージする、「A地点からB地点まで何km?」というものと同じようなものだと思って大丈夫です。ただし、距離を測る対象がA地点とかB地点という「一意」なものではなく、複数のデータからなる「分布」が対象になります。このような分布の距離の単位として、ユークリッド距離、マンハッタン距離、コサイン距離など、その他様々な距離計測単方法があります。そして、計算した距離が近いか遠いかを判定する手法としてウォード法、平均法、完全リンク法と呼ばれる手法があります。これらの手法によって、最終的に距離の近いデータ(つまり類似度の高い特徴量)をグルーピングするということをします。
多項式特徴量拡張(Polynomial feature expansion)
多項式とは「数と変数をもとにして、和と積によって作られる式」のことを意味します。例えば、僕たちが中学生の授業で習った下記のような式は、 x を変数とする多項式ということになります。
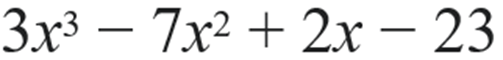
そして多項式特徴量拡張とは、その名の通り、多項式を使って特徴量を拡張する(新たに作り出す)ということです。
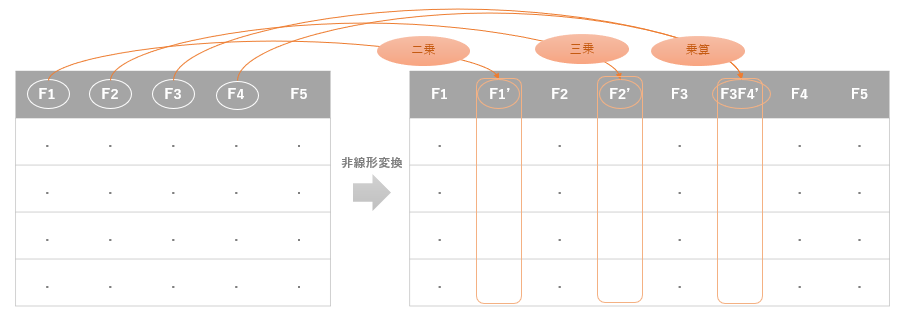
具体的には、下図のように、もとの特徴量を二乗したり、三乗したり、複数の特徴量を乗算したりした特徴量をあたらに作り出すます。
勝手にそんなことしていいの?こんなことして意味あるの?と思われるかもしれませんがこれは線形回帰などで昔からよく見られる手法です。重要なのは、なぜそのようなことをするのですか?ということですよね。
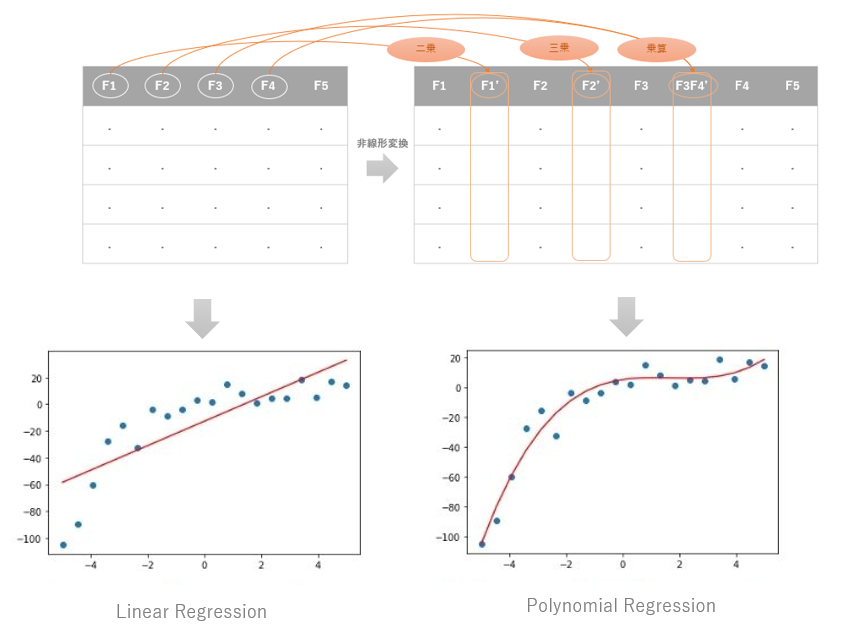
例えば、上図下段左のような、なんとなく非線形っぽい特徴量の分布を線形のアルゴリズムで学習すると、できあがったモデル(赤線)の精度は明らかに低そうに見えます。もともとの分布が非線形っぽいのでこれはどうしようもありません。
じゃあしょうがないので線形ではなく、非線形のアルゴリズムを使いますか、というこアプローチでもいいのですが、線形のアルゴリズムは非線形より解釈しやすく、計算量も少ないので、線形でうまくフィットする方法があるのであればそれにこしたことはありません。そこで、アルゴリズムのほうではなく、特徴量のほうを非線形変換すればいいのでは?という発想です。その非線形変換の手法として多項式を利用するのが多項式特徴量拡張です。実際に、この手法で特徴量を拡張し学習させると、上図下段右のようにうまくフィットする可能性があることが実証されています。
そして、多項式と類似した手法で交互作用項というものがあります。これは、複数の特徴量同士を乗算した特徴量を作るというものです。ただし、多項式、交互作用項ともに、あまり乗数を大きくしたり、特徴量を増やしすぎたりすると、オーバーフィットするので注意が必要です。多項式の場合は通常は二乗、三乗までというのが一般的です。
多項式回帰モデルは結果をチャート化すると非線形のように見えますが、あくまでも線形モデルであり、これを非線形モデルとは呼びません。
Scikit-learnのライブラリでは下記クラスを使って実装しますが、AutoSklearnでは自動化されます。
- sklearn.preprocessing.PolynomialFeatures
密行列変換(疎行列から密行列への変換(Sparse expression))
ワンホットエンコーディングを行うと、下図のようにたくさんのゼロを含む行列ができあがり、むやみに特徴量が増えていることがわかります。
大量のゼロを含むデータのことをスパースデータや、疎行列(「Sparse」は日本語で「疎」を意味します。)と呼びます。この種の疎なデータは密なデータと比較し、データサイズが大きくなりますので、計算リソースや学習時間のコストも大きくなります。また何より、この意味を持たない特徴量があるおかげでオーバーフィッティングが発生しやすく、モデルの精度に影響を及ぼす可能性が大きいため対処が必要です。
スパースデータを含む特徴量の処理には様々な方法がありますが、基本的には「疎(Sparse)から密(Dense)に変換する」というものです。
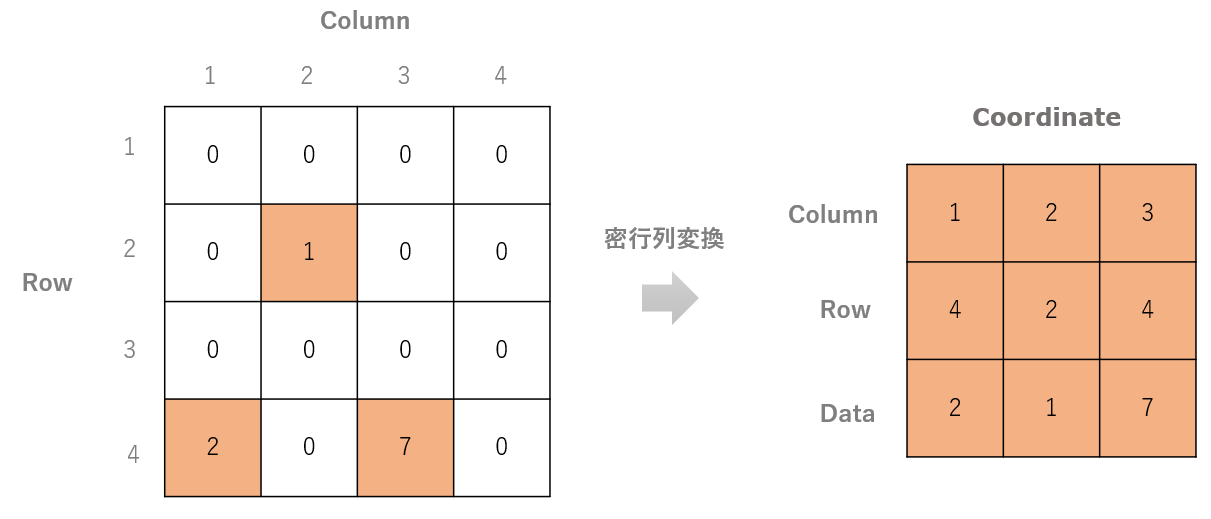
上図のような疎行列があった場合、すべてのゼロの要素に関する情報を格納することは非効率的です。ですので、ゼロとゼロ以外の要素を密行列で表す手法が必要になります。問題は各要素の位置情報をどのように格納して、いかに高速に必要な要素にアクセスできるかが重要になり、その実装には様々な方法があります。
その中でも一番わかりやすのは、要素の値とその座標位置を配列として保持するCOO(Coordinate)という手法です。
その他、座標データ情報をキー・バリューのペアとして格納したり、NumPyのインデックス作成やスライス構文を使用してデータを設定するなど様々な手法があります。
以上が特徴量の前処理の自動化についての概説でした。こんな感じで、あの手この手で有効そうな特徴量を増やしたり、不要そうな特徴量を削除したりということをしています。
アルゴリズムの学習の自動化
機械学習の分類問題で利用されるアルゴリズムには様々なものがあります。決定木、ナイーブベイズ、k近傍法、サポートベクターマシン、ランダムフォレスト、勾配ブースティングなどなど様々なものがあり、当然、各アルゴリズムでコーディングは異なります。つまり、ランダムフォレストでコードディングして精度がでなければ、別のアルゴリズムを試すという気の遠くなるような作業を繰り返すことになりそうですが、AutoMLが発達した現在はそのようなことをするのは非常に非効率です。現在、世の中に出回っている人気のAutoMLライブラリは、ここまで説明した前処理だけではなく、各アルゴリズムによる学習も自動化します。つまり、前処理が完成したデータセットを入力すると、あらゆるアルゴリズムを自動的に総当たりで学習し、モデルの評価までしてくれます。
具体的には、下記1行のコード(AutoSklearnClassifier)で、これまで上述した、「データの前処理、「特徴量の前処理」、「15の分類系のアルゴリズム」、「110のハイパーパラメータ」の組み合わせで自動的に学習させます。
automl_model = AutoSklearnClassifier()
自動的に学習されるアルゴリズムの一覧は下記の通りで主要な分類のアルゴリズムがリストされていることがわかります。
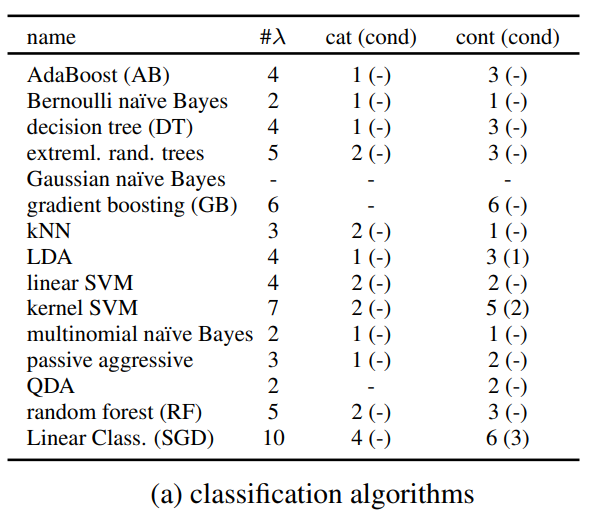
出典: Efficient and Robust Automated Machine Learning
因みに、本記事ではあまり説明をしていませんが、新しいバージョンのAutoSklearnでは、回帰問題にも対応しており、事実上、下記一行で学習を実行します。
automl_model_regression = AutoSklearnRegressor()
ハイパーパラメータのチューニングの自動化
そして、各アルゴリズムは数個から十数個のチューニング可能なハイパーパラメータを持っています。AutoMLがない時代は、これらのパラメータも手動でチューニングをする必要があったため、そのパターン数を考えるとコーディング量と試行錯誤の工数は現在とは比較にならないほど膨大なものです。
ハイパーパラメータの探索を支援するライブラリは多数あります。一番有名なものはGridSearchCVでしょう。GridSearchCVは、使用するアルゴリズムのハイパーパラメータの全ての組み合わせで学習処理を実行してくれます。そして、交差検定でモデルのスコアリングまでしてくれますのでベストなパラメータの組み合わせを探索することができます。コード量も大幅に削減できる非常に便利なライブラリで広く利用されています。ですが、すべての組み合わせを総当たりするというのは、計算リソース、処理時間ともに非常に大掛かりなものになります。そこで、AutoSklearnではこの問題にベイズ最適化とよばれる手法で対処しています。
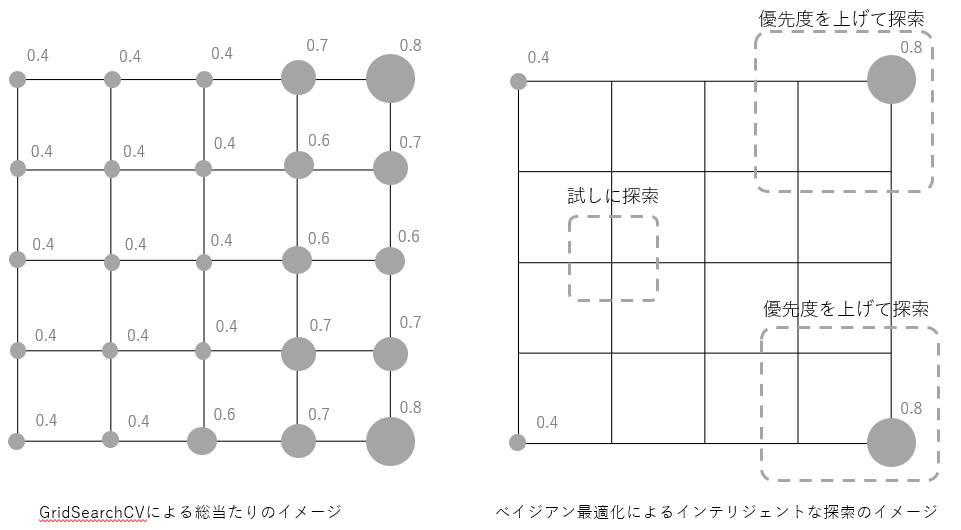
仮に、2個のハイパーパラメータがあり、各ハイパーパラメータが5つの値をとるとすると25パターンの探索空間となります。GridSearchCVではこの25パターンを総当たりしますので上図左のようなイメージです。グレーの丸の大きさが大きいほど精度が高いと考えてください。
それに対して、ベイズ最適化では、「まず四隅を試してみよう」、その結果、「右上と右下の結果がいいようだから、その周辺を優先度を上げて探索してみよう」、「左真ん中あたりは予想がつかないから一パターンだけ試してみよう」というようなインテリジェンスをもって探索をするというイメージです。
この二つの手法の違いはなんでしょうか?GridSearchCVではスコアの結果がよかろうが、悪かろうが、とにかく全パターンを何も考えずに処理します。それに対してベイズ最適化では、前回の計算結果から、スコアが高くなりそうなエリアを推測しながら探索を行います。このようなインテリジェンスにより、ベイズ最適化を利用するとGridSearcCVの総当たりよりも早いタイミングでハイパーパラメータのベストな組み合わせを見つけられるケースがあることが実証されています。
さて、ここまで来て、なんとなく想像できると思うのですが、一体どれだけのパターンの探索をすることになるんだ?と思いませんか?
実は上述したのハイパーパラメータの探索空間はハイパーパラメータの組み合わせだけでは閉じません。どのようなデータ前処理をおこなったか、またどのような特徴量前処理をおこなったのかにも影響を受けます。
AutoSklearnの
- データ前処理パターンは4種類
- 特徴量の前処理パターンは14種類
- そしてとりえるアルゴリズムは15種類
- そのアルゴリズムが持つハイパーパラメータの総数は110個、
となり、これらすべての組み合わせの中からベストなパターンを一つ見つけ出して、やっと学習完了です。とてつもなく膨大な空間を探索することになり、いくらベイズ最適化をしているといっても限界があります。(※ちなみに、最新のAutoSklearnのバージョンは自動化の項目がさらにエンハンスされていますので、よりパターン数はより多くなります。)
そこで、AutoSklearnではメタラーニングと呼ばれる学習手法を利用して、この膨大な探索空間を小さくする、ようは探索のパターン数を減らす試みをしています。
メタラーニングの自動化
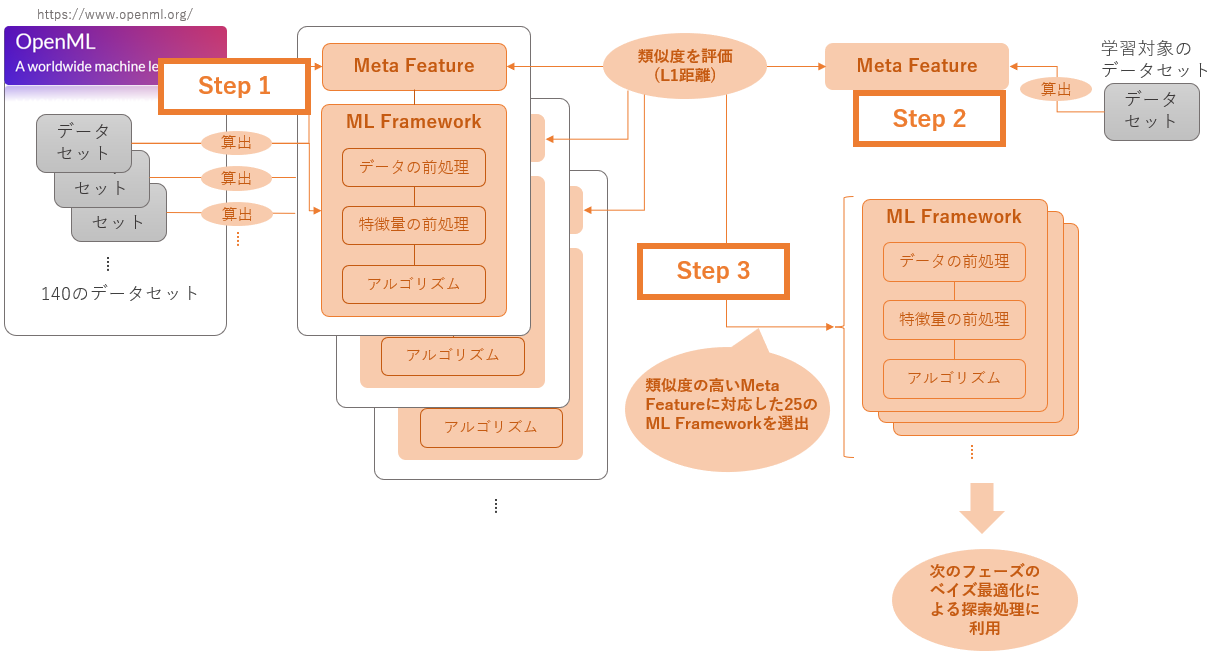
AutoSklearnでのメタラーニングの利用方法は非常に興味深いものです。その仕組みは、OpenMLの活用から始まります。OpenMLとは機械学習における世界規模のオープンプラットフォームです。そこでは、あらゆるタイプのデータセットが共有されています。AutoSklearnでは、OpenMLに登録されているデータセットをメタラーニングに活用しています。その大まかなステップは次のようなものです。
-
Step 1
まず初めに、OpenMLに登録されている140のデータセットから「Meta Feature」と「ML framework」をあらかじめ算出します。「Meta Feature」とはそのデータセットを要約したカルテのような情報です。また、「ML framework」とはそのデータセットに対して、ベイズ最適化によって探索された「データの前処理、特徴量の前処理、アルゴリズムの最適な組み合わせのセット」です。 -
Step 2
次に、学習にかけたいデータを入力すると、そのデータからも上述した、Meta Featureを算出し、あらかじめ算出してあるOpenMLに登録されているデータセットのMeta Featureとの類似度を計算します。(この類似度の計算にはマンハッタン距離が使われています。) -
Step 3
そして、140のデータセットから類似度の高い25のデータセットが選択され、そのデータセットに対応するML frameworkが次のフェーズのベイズ最適化による探索(学習対象のデータセットでの探索)の候補となります。
つまり、この一連の処理は、「OpenMLに登録済みの140のデータセットの中から、機械学習にかけたいデータと類似しているデータセットを見つける」ことにフォーカスしたアプローチだといえます。OpenMLに登録済みのデータセットは予め、最適なML framework(データの前処理、特徴量の前処理、アルゴリズムの組み合わせ)が判明しています。したがって、学習にかけたいデータが登録済みのデータセットに類似しているのであれば、最適なML frameworkも類似している可能性が高いだろうという仮説をベースにしたアプローチです。
このようなアプローチで、次のベイズ最適化のフェーズで計算しなければいけない組み合わせの候補を、25種類のデータセットに付随するML frameworkだけに絞り、探索空間を大幅に小さくしているということになります。
ちなみに、この仕組みの中の重要な要素であるMeta Feature(データセットの類似度の評価基準)は要約統計量、次元圧縮に関連する量やエントロピーなど38種類のメタ特徴を算出したものだということが下記論文に明記されています。
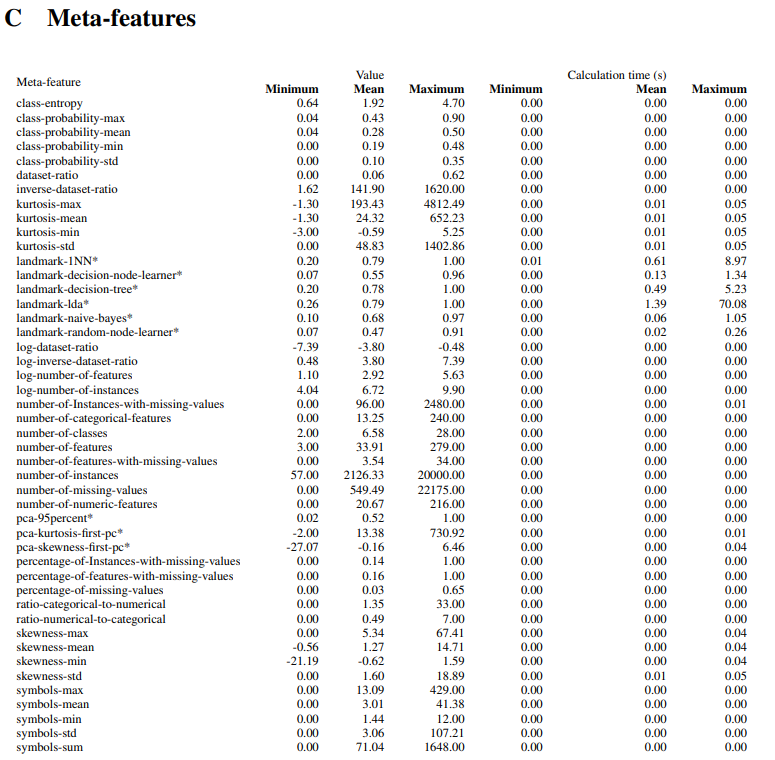
出展:Supplementary Material for Efficient and Robust Automated Machine Learning
Auto Sklearnでは、このようなメタラーニングを活用した仕組みと上述したベイズ最適化によるML frameworkの探索により、精度の高い予測モデルを効率よく構築するわけですが、この後のフェーズでも予測精度を向上させるための仕組みが取り入れられています。それがアンサンブル学習と呼ばれる非常に有名な手法となります。
アンサンブル学習の自動化
通常、一つのモデルで入力されたデータの予測を行うところを、複数のモデルの予測結果で平均をとったり、多数決をしたりし、最終的な予測結果をだすようなモデルを作る学習方法をアンサンブル学習と呼んでいます。ようは「三人寄れば文殊の知恵」的なもので、一人で考えるより、三人で考えて答えをだすほうが精度は高いはずということです。
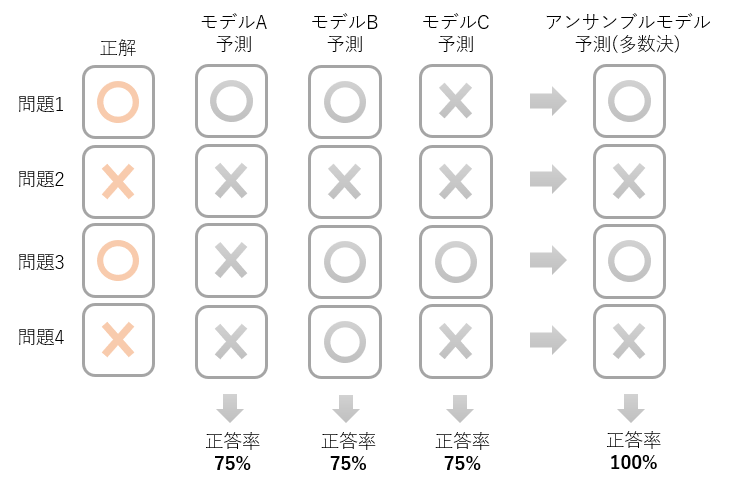
例えば、4つの問題に対する推測を行った場合、一つのモデルでは4問中3問正解で正答率75%が限界だったとしても、3つのモデルをアンサンブルし、多数決をとった予測では正答率が100%になる可能性があります。アンサンブル学習では未学習に対する予測能力が向上し、モデルの汎化性能があがることが期待できます。
上図は分類問題の例ですが、アンサンブル学習は回帰のアルゴリズムでも可能です。
AutoSklearnの処理フローまとめ
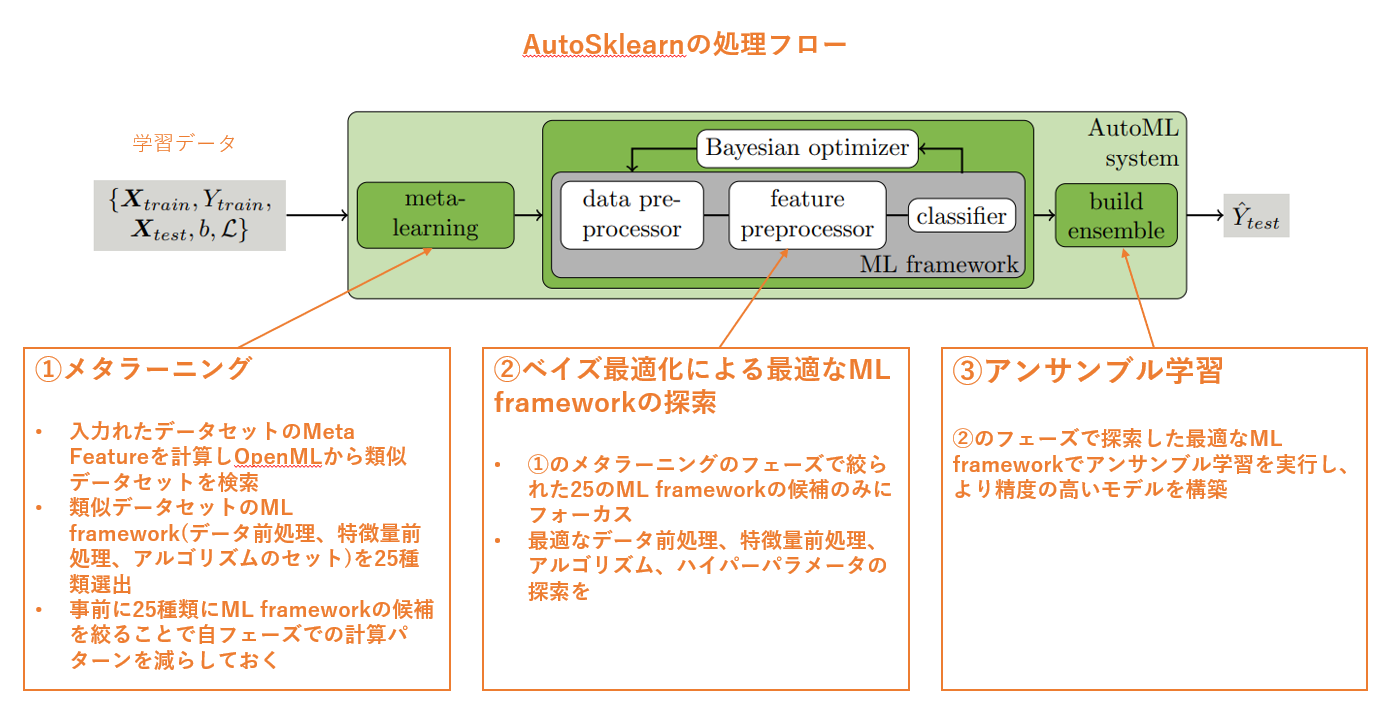
最後に、ここまで説明してきた内容を、AutoSklearn の論文にある図でまとめるとこんな感じでしょうか。
サンプルコード
回帰問題
下記に、AutoSklearnの回帰問題のサンプルコートを掲載します。データセットはおなじみの「ボストンの住宅価格データ」になります。分析シナリオは下記の記事に説明があり、AutoMLを使っていないコードも掲載していますので、AutoSklearnのコードと比較してみるとどれほど自動化されているかがよくわかります。ちなみにこの記事のコードで使っている回帰アルゴリズムはたった一つです。
そして、AutoSklearnの回帰問題のサンプルコードが以下です。
# ライブラリのインストール
!pip install auto-sklearn
!pip install PipelineProfiler
# データセットの読込み
from sklearn.datasets import load_boston
boston = load_boston()
# 説明変数のデータフレームを作成、確認
import pandas as pd
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df
# 目的変数の追加、確認
df["MEDV"] = boston.target
df
# 学習データと評価データを作成、確認
from sklearn.model_selection import train_test_split
X_train, x_test, Y_train, y_test = train_test_split(
df.iloc[:, 0 : df.shape[1] - 1],
df.iloc[:, df.shape[1] - 1],
test_size=0.2,
random_state=42
)
X_train.head()
# アルゴリズムの定義
import autosklearn.regression
automl_model_regression = autosklearn.regression.AutoSklearnRegressor(
time_left_for_this_task=180,
seed=42
)
# AutoMLによる学習実行
automl_model_regression.fit(X_train, Y_train)
# 予測処理を実行するためテストデータから一行抜いて予測データを作成
x_pred = x_test.iloc[0:1]
x_pred
# 予測実行
automl_model_regression.predict(x_pred)
# 正解データを確認し、予測値との乖離を見てみる
y_pred = y_test.iloc[0:1]
y_pred
# AutoSklearnで自動化された処理を確認
import PipelineProfiler
profiler_data = PipelineProfiler.import_autosklearn(automl_model_regression)
PipelineProfiler.plot_pipeline_matrix(profiler_data)
分類問題
下記に、AutoSklearnの分類問題のサンプルコートを掲載します。データセットはおなじみの「ワインの成分データ」になります。分析シナリオは下記の記事に説明があり、AutoMLを使っていないコードも掲載していますので、AutoSklearnのコードと比較してみるとどれほど自動化されているかがよくわかります。ちなみにこの記事のコードで使っている分類アルゴリズムはたった一つです。
そして、AutoSklearnの分類問題のサンプルコードが以下です。
#ライブラリのインストール
!pip install auto-sklearn
!pip install PipelineProfiler
#データのロード
from sklearn.datasets import load_wine
data_wine = load_wine()
# 説明変数のデータフレームを作成、確認
import pandas as pd
X = pd.DataFrame(data_wine["data"],columns=data_wine["feature_names"])
X.head()
# 目的変数のデータフレームを作成、確認
import pandas as pd
Y = pd.DataFrame(data_wine["target"],columns=["target"])
Y.head()
# 学習要データと、評価用データに分割
from sklearn.model_selection import train_test_split
X_train, x_test, Y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
# 学習モデルを定義
from autosklearn.classification import AutoSklearnClassifier
cls = AutoSklearnClassifier(time_left_for_this_task=180, seed=42)
# AutoMLによるモデルの学習を実行
automl_model_classification.fit(X_train, Y_train)
# PipelineProfilerによるML Frameworkの可視化
import PipelineProfiler
profiler_data = PipelineProfiler.import_autosklearn(cls)
PipelineProfiler.plot_pipeline_matrix(profiler_data)
さいごに
本記事では、「ざっくり理解する」というところを目的として作成しました。難しい統計用語や数式を使った説明を可能な限り省いたため、多少乱暴なまとめ方、説明のしかたになっている部分もあると思いますが、なんとなくでもAutoMLのイメージが理解されていれば幸いに思います。
より詳細を理解されたい場合は、先人の方々が作成されたもっと有用な記事がたくさんありますのでそちらを参照いただけるとよいかと思います。また、AutoSklearnの自動化は、scikit-learnの関数ベースで構築されており、パラメータの値なども公開されていますので、ブラックボックスにはなっていません。なのでscikit-learnで実際に処理を書いて挙動を確認することでより理解を深めることをお勧めいたします。
最後に、本記事を書くにあたり、たくさんの有用なドキュメントを参照させていただきましたので、ここにリストして、謝辞とさせていただきたいと思います。
-
Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms
-
Supplementary Material for Efficient and Robust Automated Machine Learning
-
Feature selection techniques for classification and Python tips for their application
-
Everything You Need to Know About Feature Selection In Machine Learning