はじめに
自分が研究室の学部生だったときには大学院の進学が決まっていたので、今後後輩が新しく研究室に入ってくるときに機械学習・ディープラーニングについての知識を共有できるように、ちょくちょく作成していた音声分類の特徴量エンジニアリングやモデリングについてを記事にまとめてみようと思いました。
今回使用するコードは以下にまとめてあります。
https://github.com/kshina76/audio-classification
使用するデータセット
研究室でよく使っていたデータセットがあるのですが、公開していいのかよくわからなかったので、日本声優統計学会のデータセットを使うことにしました。
なので、今回のデータセットに合わせるため実際に作ったモデルを一部改変して作りなおしました。
日本声優統計学会
https://voice-statistics.github.io/
環境
python3.7.3
Anaconda3
keras2.2.4
tensorflow1.13.1
方針
音声の波形をそのまま学習することもできるのですが、大量の学習データが必要になってしまうことや、非力なPCだととてつもないほどの時間がかかってしまうため、今回は処理を施した特徴量を使うことにしました。
よく使われる特徴量
ここでは、音声処理でよく使われる特徴量について説明していきます。
MFCC
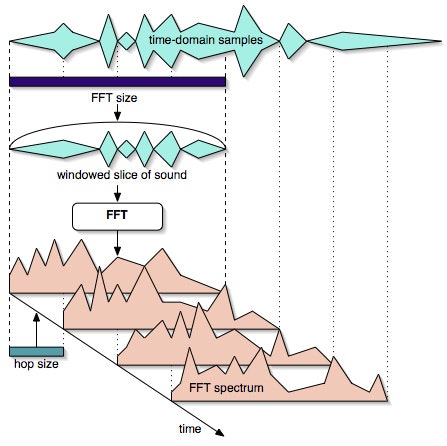
1.まず短時間フーリエ変換(stft)を行います
step1. 音声波形をstft_sizeの長さで切り取りフレームとする
step2. フレームに窓関数をかける
step3. フレームをフーリエ変換(fft)をして1フレームは完成
step4. フレームをhop_length分ずらして、step1に戻り繰り返す。
2.スペクトログラムを求める
step1. 1で求めたstftの行列の絶対値を取る事で振幅を算出
step2. 2乗することでパワー(振幅のパワー)を求めたものがスペクトログラム
※スペクトログラム単体だとエネルギーを求めるため2乗しないが、メルスペクトログラムを求めるときにはパワーを使うため、2乗している。
3.メルスペクトログラムを求める
step1. メルフィルタバンクを作る
step2. スペクトログラムとメルフィルタバンクでdot積をとる事で完成
※メルフィルタバンクとは、周波数領域において三角形状の窓関数が人間の聴覚特性に合わせて対数的に並んでいる窓関数の集合みたいなもの。
4.mfcc
step1. メルスペクトログラムをデシベル単位に変換することで対数をとる
step2. 離散コサイン変換(dct)をして晴れてmfccの完成です。
まとめると、以下のようなステップになる。
以下のステップでmfccは算出できる
1.メルスペクトログラムを算出
2.1をデシベルに変換
3.2を離散コサイン変換
その他の特徴量
音声分類器を作る過程で、あまり使ったことが無い特徴量を使ったので概要だけ紹介しておきます。
1.クロマグラム
ある音声に含まれている12半音の強さをそれぞれ可視化したもの
2.スペクトルコントラスト
そのままの名前でスペクトルのコントラスト
3.tonnetz
メジャーコードとマイナーコードがついになるように並べたもの
データの前処理
音声分類に限らず機械学習や深層学習では、特徴量エンジニアリングが8のモデリングが2といわれるほど、前処理や特徴量の作成が重要です。ここでは、基本的な前処理を施して、どのような特徴量を作るかを説明していきます。
無音区間の除去
まず、このデータセットの特徴として後半の半分くらいは無音だったので、無音の部分を切り取る処理をします。thresholdは閾値のことで20を下回ったら無音と判定してその部分を切り取る処理をしています。
audio, _ = librosa.effects.trim(audio, self.threshold)
サンプル長の調整
音声ごとにサンプル長が異なるので、モデルに入力する前にすべての音声のサンプル長を一致させる必要があります。そこで、ここではサンプル長についての処理を施していきます。
sample_lengthは切り取る音声の長さです。実際の音声がこのsample_lengthより短かったらゼロパディングをしてあげます。
もし、sample_lengthより長い音声だった場合はランダムでスタート位置を指定してあげて、そこからsample_length分の音声をトリミングしてきます。そのトリミングしてきた音声を一サンプルとします。
if len(audio) <= self.sample_length:
# padding
pad = self.sample_length - len(audio)
audio = np.concatenate((audio, np.zeros(pad, dtype=np.float32)))
else:
# trimming
start = random.randint(0, len(audio) - self.sample_length - 1)
audio = audio[start:start + self.sample_length]
今回作ったモデル
複数のモデルを作ったり、複数の特徴量を試したりしたので時系列順に記述していこうと思います。
MLP
多層パーセプトロンは、ニューラルネットワークの一分類である。MLPは少なくとも3つのノードの層からなる。入力ノードを除けば、個々のノードは非線形活性化関数を使用するニューロンである。MLPは学習のために誤差逆伝播法(バックプロパゲーション)と呼ばれる教師あり学習手法を利用する。その多層構造と非線形活性化関数が、MLPと線形パーセプトロンを区別している。MLPは線形分離可能ではないデータを識別できる。
(wikipediaより)
ver1
使用した特徴量は、
・mfccの低次20次元
※MLPに入力するには、1次元ベクトルにしなければいけないので、mfcc列方向で平均値をとる事で1次元ベクトルに変換した。
作成したモデルは以下の通り
class MLP():
def build_model(self):
inputs = Input(shape=(20,))
x = Dense(256, activation='relu')(inputs)
x = Dense(256, activation='relu')(x)
x = Dense(3, activation='softmax')(x)
model = Model(input=inputs, output=x)
optimizer = Adam()
model.compile(loss="categorical_crossentropy",
optimizer=optimizer, metrics=['accuracy'])
model.summary()
return model
今回は、3人の話者を分類する3分類問題として解いた。
結果は以下の通り
loss: 10.1997 - acc: 0.3051
ランダムよりひどい結果になってしまった。おそらくmfccの20次元しかとってこなかったため、ピッチの情報などが含まれていなかったのだと思われる。
次のモデルではそこらへんを改良していこうと思う。
ver2
使用した特徴量は、
・mfccの高次も含めた40次元
こちらもMLPに入力するために変換した。
作成したモデルはinputの形状だけだが、一応載せておく
class MLP():
def build_model(self):
inputs = Input(shape=(40,))
x = Dense(256, activation='relu')(inputs)
x = Dense(256, activation='relu')(x)
x = Dense(3, activation='softmax')(x)
model = Model(input=inputs, output=x)
optimizer = Adam()
model.compile(loss="categorical_crossentropy",
optimizer=optimizer, metrics=['accuracy'])
model.summary()
return model
結果は、以下の通り
loss: 5.6667 - acc: 0.5868
40次元まで含めることで正解率が上がったが、3分類問題にしてはまだまだ正解率が低いので、違う方針を考えてみたりモデルのチューニングを行ってみる。
ver3
使用した特徴量は、
・mfcc
・クロマグラフ
・メルスペクトログラム
・スペクトラルコントラスト
・tonnetz
以上の特徴量をそれぞれ平均値をとって、193要素の1次元ベクトルにして1の特徴量に結合したものを入力とした。
使用したモデルは以下の通り。ユニットの数を変えたり活性化関数を変えてみたりした。
class MLP():
def build_model(self):
inputs = Input(shape=(193,))
x = Dense(280, activation='tanh')(inputs)
x = Dense(300, activation='relu')(x)
x = Dense(3, activation='softmax')(x)
model = Model(input=inputs, output=x)
optimizer = Adam()
model.compile(loss="categorical_crossentropy",
optimizer=optimizer, metrics=['accuracy'])
model.summary()
return model
※いきなりユニットの数や活性化関数の種類を変更しているが、そこに行きつくまでに色々試して、ある程度のとこまで行ったものを載せています。
決して、いきなりこの結論に至ったわけではないです。
結果は以下の通り
loss: 0.5325 - acc: 0.8036
ようやく80%の正解率にきた。まだ、lossは下がっている途中なのでまだ上がると思う。(PCの調子が悪かったので、途中で学習を終了させた、、、orz)
CNN(畳み込みニューラルネットワーク)
機械学習において、畳み込みニューラルネットワークは、順伝播型人工ディープニューラルネットワークの一種である。画像や動画認識に広く使われているモデルである。
(wikipediaより)
ver4
ここらへんでほかのモデルを試したくなってきたので、CNNを試してみることにした。
使用した特徴量は、
・mfcc
・クロマグラフ
・メルスペクトログラム
・スペクトラルコントラスト
・tonnetz
class CNN():
def build_model(self):
inputs = Input(shape=(193, 1))
x = Conv1D(64, 3, activation='relu')(inputs)
x = Conv1D(64, 3, activation='relu')(x)
x = MaxPooling1D(3)(x)
x = Conv1D(128, 3, activation='relu')(x)
x = Conv1D(128, 3, activation='relu')(x)
x = GlobalAveragePooling1D()(x)
x = Dropout(0.5)(x)
x = Dense(3, activation='softmax')(x)
model = Model(input=inputs, output=x)
optimizer = Adam()
model.compile(loss="categorical_crossentropy",
optimizer=optimizer, metrics=['accuracy'])
model.summary()
return model
結果は以下の通り
loss: 0.5096 - acc: 0.7917
MLPより少し悪い結果となってしまった。
CNNは前後関係とかがある時系列データのほうがもしかしたら効くかもしれない。
ジェネレータ
前処理に使用したコードやジェネレータの定義は以下の通りになっています。モデルによって少し違う部分があるので、詳しくはgithubに置いてあります。
class BatchGenerator(Sequence):
def __init__(self, data_path, labels, batch_size, sample_rate, sample_length, threshold):
self.batch_size = batch_size
self.data_path = data_path
self.labels = labels
self.sample_rate = sample_rate
self.sample_length = sample_length
self.threshold = threshold
self.length = len(data_path)
self.batches_per_epoch = math.ceil(self.length / batch_size)
def preprocess(self, audio):
audio, _ = librosa.effects.trim(audio, self.threshold)
# すべての音声フェイルを指定した同じサイズに変換
if self.threshold is not None:
if len(audio) <= self.sample_length:
# padding
pad = self.sample_length - len(audio)
audio = np.concatenate((audio, np.zeros(pad, dtype=np.float32)))
else:
# trimming
start = random.randint(0, len(audio) - self.sample_length - 1)
audio = audio[start:start + self.sample_length]
stft = np.abs(librosa.stft(audio))
mfccs = np.mean(librosa.feature.mfcc(y=audio, sr=self.sample_rate, n_mfcc=40),axis=1)
chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=self.sample_rate),axis=1)
mel = np.mean(librosa.feature.melspectrogram(audio, sr=self.sample_rate),axis=1)
contrast = np.mean(librosa.feature.spectral_contrast(S=stft, sr=self.sample_rate),axis=1)
tonnetz = np.mean(librosa.feature.tonnetz(y=librosa.effects.harmonic(audio), sr=self.sample_rate),axis=1)
feature = np.hstack([mfccs, chroma, mel, contrast, tonnetz])
return feature
def __getitem__(self, idx):
batch_from = self.batch_size * idx
batch_to = batch_from + self.batch_size
if batch_to > self.length:
batch_to = self.length
x_batch = [] # feature
y_batch = [] # target
for i in range(batch_from, batch_to):
audio, _ = librosa.load(self.data_path[i], sr=self.sample_rate)
mfccs = self.preprocess(audio)
x_batch.append(mfccs)
y_batch.append(self.labels[i])
x_batch = np.asarray(x_batch)
y_batch = np.asarray(y_batch)
return x_batch, y_batch
def __len__(self):
return self.batches_per_epoch
def on_epoch_end(self):
pass
まとめ
今回は、音声分類の解説とコードを書いてみました。あまり使ったことのない特徴量を使ってみたり、特徴量の選別やモデルの最適化をこまごまと繰り返しながら作成してみました。
他のデータセットを試してみたり、気になるモデルやいい結果が出たモデルは、どんどん載せていこうと思います。
ここからは、データ分析をしていて感じたことですが、
データ分析は特徴量のエンジニアリングやモデルの最適化など、泥臭い作業だと思われがちですが、僕的にはプログラムを組んでいて試行錯誤している感じがたまらなく楽しいです。
何回も作業を繰り返して、いい結果を出力するモデルを構築できたときには、とてつもないうれしいですし。
とくに近年において発達のはやい分野だと思いますので、スピード感もあります。
論文でGANなどはどんどん新しいモデルが発表されているので、新しいモデルの実装などにも取り組んでいけたらいいですね。
他にも為替予測、音声合成、画像分類などのコードも趣味で載せています。
https://github.com/kshina76