はじめに
青空文庫の情報を使って何かしてみたいと思った人は私だけではないはず。
実際、青空文庫Advent Calendar 2017でも全文検索や音読への応用に関する記事が投稿されていますし、その他にも実用化されているサービスがいくつもあります。青空文庫20周年記念シンポジウム「青空文庫の今とこれから」でも、紙書籍へ製本するサービスやコーパスとしての利用などの発表がありました。
一方で、青空文庫の情報を利用するのはあまり簡単ではありません。基本的にはwww.aozora.gr.jpで配布されているHTMLやCSVを解析する必要がありますが、青空文庫には日々作品が追加されていくので、それを繰り返し行う必要があります。このような状況を改善しようと作り始めたのがPubserverという青空文庫の情報を配布するためのサーバーシステムです。これを使うと、RESTfulなAPI呼び出しで作品や著者・訳者のメタ情報や作品のコンテンツ情報を取得できます。この投稿では、Pubserverのシステム構成とそれらがどのように動いているのかを簡単にご説明したいと思います。
なお、PubserverはCoffeeScriptという言語で書いていたのですが、現在それをJavaScript(ES2017)を使って書き直しを行なっています。それがPubserver2なのですが、APIも互換でシステムの構成的にはほぼ同じなので、ここではPubserverという名前で説明を進めたいと思います。
システムの構成
以下が簡単な構成図になります。
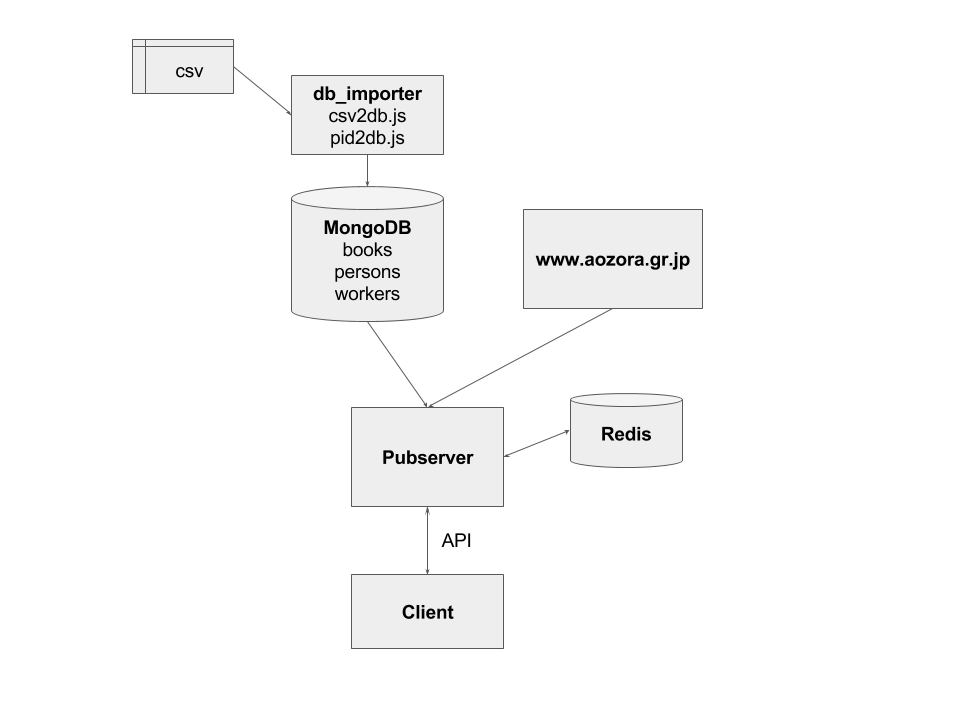
システムの中心にいるのがRESTfulなAPIを提供する(狭義の)Pubserverです。自分で書いたのは主にこの部分になります。PubserverはExpress.js、Pubserver2はKoa.jsという、それぞれNode.js上で動くWebフレームワークを使っています。クライアントからAPIリクエストを受け、バックエンドのDBや青空文庫のサイトにアクセスして情報を整えてクライアントに返すのが主な役割です。
MongoDBはMongoDB Inc.が提供するドキュメント志向データベースです。JSONのデータをそのまま格納し、容易に検索などを行うことが出来るため、作品や著者などのメタデータを格納するDBとして採用しています。このデータ構造の詳細は12/19の投稿をご覧ください。
また、Pubserverは作品のコンテンツ情報(テキスト形式、HTML形式)を提供する際に青空文庫サイト(www.aozora.gr.jp) からも情報取得します。取得したデータは圧縮してRedisというキーバリューストア型のデータベースにキャッシュ(一時保存)します。そして、一定時間内に同じアクセスがあった場合にはwww.aozora.gr.jpにアクセスせずにRedisからデータを取り出してクライアントに返します。
システムの動作
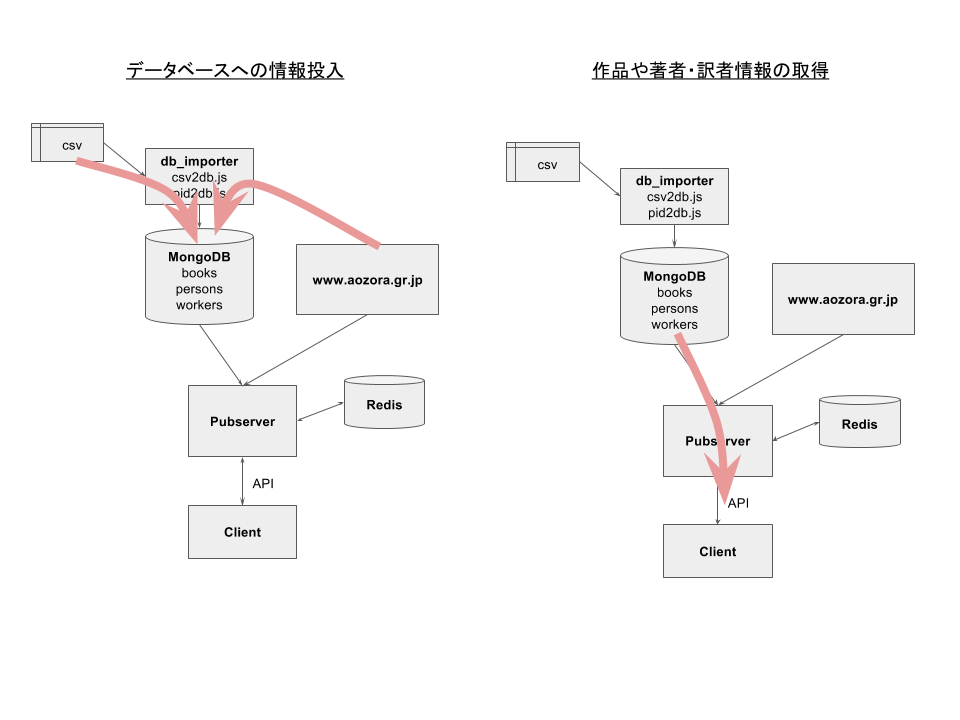
データベースへの情報投入
これは、「青空文庫のデータ構造について」で説明している様に、作品および著者・訳者の情報に関してはCSVファイルから、工作員の情報に関しては青空文庫サイトのHTMLページから読み込んで、JSONに整形しMongoDBのbooks, persons, workersというコレクションにそれぞれ登録されます。
作品、著者・訳者、工作員の情報取得
作品、著者・訳者、工作員の情報取得には以下のAPIを利用します。
| 取得データ | API |
|---|---|
| 作品のリスト | GET /api/v0.1/books |
| 個別の作品の情報 | GET /api/v0.1/books/{book_id} |
| 人物情報のリスト | GET /api/v0.1/persons |
| 個別の人物の情報 | GET /api/v0.1/persons/{person_id} |
| 工作員情報のリスト | GET /api/v0.1/workers |
| 個別の工作員の情報 | GET /api/v0.1/workers/{worker_id} |
リストの取得リクエストには条件をクエリパラメータで指定できます。例えば、太宰治の本のリストであれば、GET /api/v0.1/books?author=太宰治というリクエストになります。また、正規表現も使うことが出来て、例えば「猫」で始まるタイトルの作品を検索する場合はGET /api/v0.1/books?title=/^猫/となります。
これらのリクエストはPubserverでMongoDBに対するクエリーに変換されます。例えば上記の猫の例だと、db.books.find({title: {$regex: '^猫'}})とクエリになってMongoDBで検索されます。検索結果は、MongoDBが独自に付けている_idというフィールドだけ取り除いてクライアントにそのままJSONで返されます。
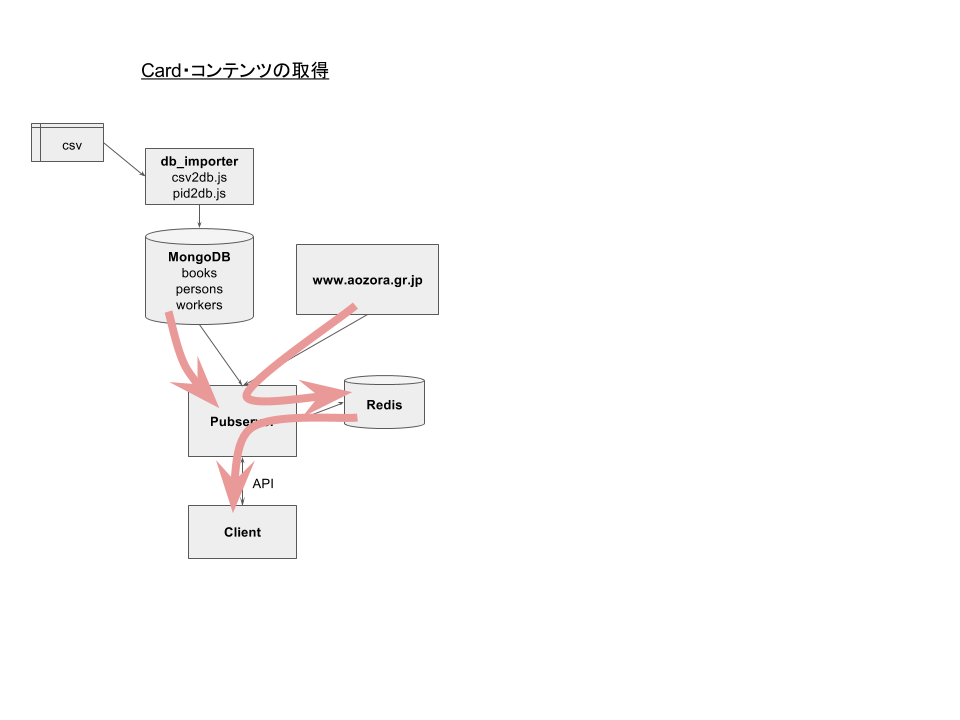
Card情報および作品コンテンツの取得
Card情報および作品コンテンツの取得には以下のAPIを利用します。
| 取得データ | API |
|---|---|
| 作品のカード | GET /api/v0.1/books/{book_id}/card |
| 作品の中身をテキストで | GET /api/v0.1/books/{book_id}/content?format=txt |
| 作品の中身をhtmlで | GET /api/v0.1/books/{book_id}/content?format=html |
これらのリクエストに対しては、まずbook_idでMongoDBから作品情報を入手し、そこに含まれているcard_url、text_url、html_urlフィールドのURLからデータをダウンロードします。それを一旦Redisに期限付き(現状60分)で登録した後、クライアントに返します。期限期間内に同じリクエストが来た時にはRedisからデータを取り出して返します。
最後に
青空文庫の情報を配布するためのAPIサーバーの構成とその動作について説明を行いました。上でも述べたように、現在JavaScriptでの再実装を行っています。そのリポジトリがこちらになります。IssueでもPRでも大歓迎ですので、ご活用下さい。