はじめに
先日OpenAIから公開されたローカル環境で利用できるLLMのgpt-oss-20Bが16GBのVRAM搭載コンピュータで実行できるということでM2 Pro MacBook Pro 16GBメモリで動かせるかを試してみました。ollamaではうまく動かず、LM Stuidoで数tok/secから20前後tok/secで動かせたのでその設定などをまとめました。
検証環境
- MacBook Pro : M2 Pro コア10(パフォーマンス:6、効率性:4)、メモリ16GB
- macOS:15.6
- LM Studio : 0.3.23(Build 3)
LM Studioの設定
Guardrails設定
gpt-oss-20Bを利用するには16GB VRAMが必要とのことだったので16GBメモリの私のMacBookでも利用できると思い、モデルをダウンロードしてロードしようとするとシステムが過負荷になることを防止するガードレール機能にロードできない。この設定をオフにすることでVRAMに対して大きなモデルをロードできる。
ガードレールの設定は⚙️(⌘+,)で設定を開き、Hardware(⌘+⇧+H)を開き、Guardrailsでモデル読み込みのガードレールをオフにします。
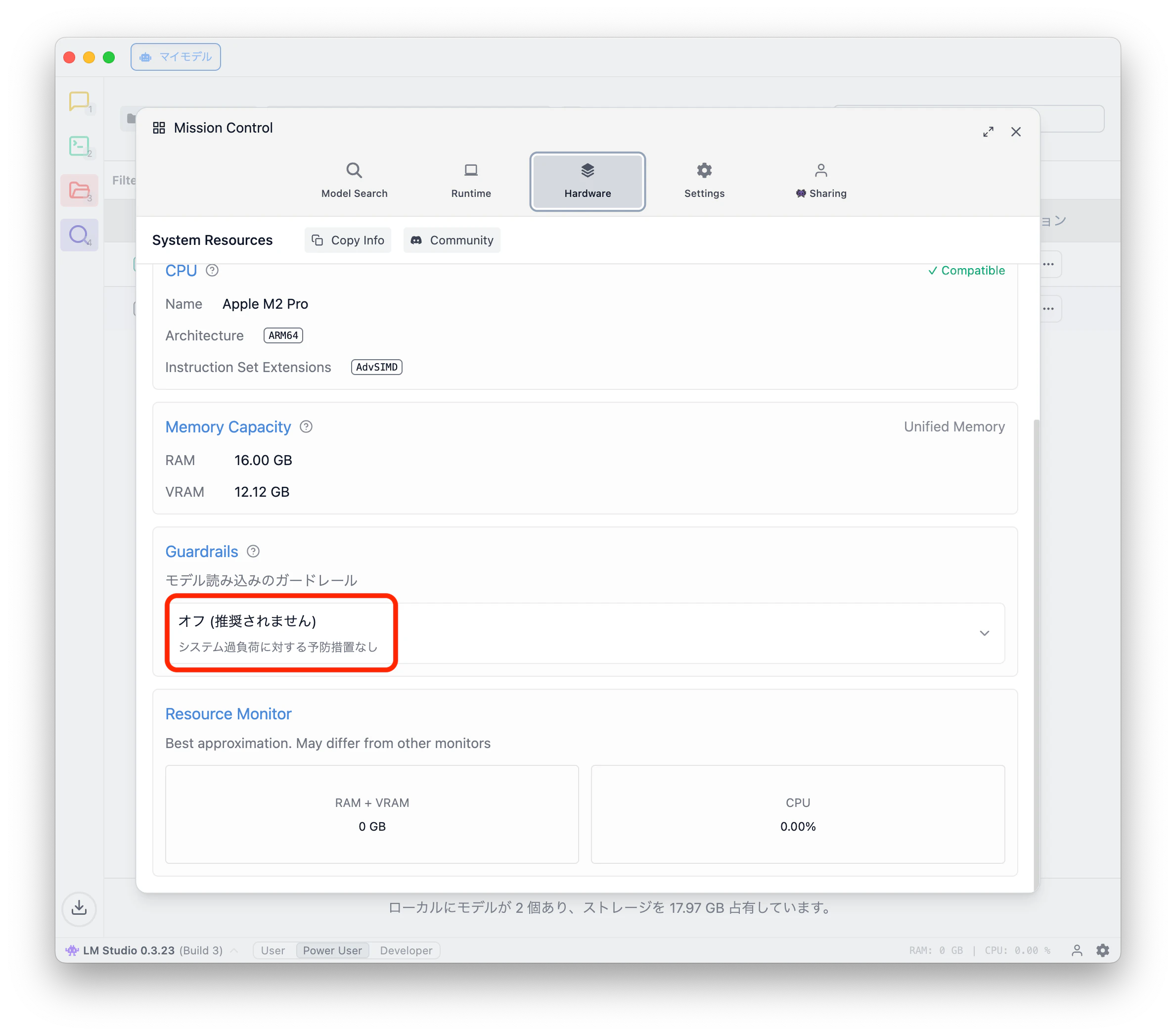
この設定でモデルをロードできるようになりますがメモリの大半を占めてしまい、システムの動作に影響します。これを回避するために下記の設定が必要です。
gpt-oss-20Bの設定
ガードレール設定をオフにしただけのデフォルトの設定では16GBしかないメモリの大半を使用し、システムが応答しなくなるような状態になってしまうのでLM Studio 0.3.23(Build 2)までではモデルをメモリに保持をオフにします。0.3.23(Build 3)からはモデルをメモリに保持はオンはままで、新たな追加された実験的(Experimental)なオプションのForce Model Expert Weight on to CPUをオンにします。
この設定ではGPUはほぼ使用せずにCPUで処理を行っています。
GPUオフロードは0〜4の範囲ではればメモリの使用量が抑えられます。この値を5にしても動作しますがメモリの使用量がぎりぎりです。
CPU Thread pool Sizeは5にしました。6にするとシステムが応答しないような状態になります。P-CPUが6なのでひとつ少ない5が最大のように想像されます。
モデルが大きいのでmmap()を試すをオンにし、ロード時間を短縮、パフォーマンスの向上をはかります。
0.3.23(Build 3)で変更した設定項目を以下の表にまとめました。これ以外の項目はデフォルトのままです。
| 設定項目 | 設定値 |
|---|---|
| GPUオフロード | 0〜4 |
| CPU Thread Pool size | 5 |
| Offload KV Cache to GPU Memory | オン |
| モデルをメモリに保持 | オン |
| mmap()を試す | オン |
| Force Model Expert Weights onto CPU | オン |
| Flash Attention | オン |

※メモリ使用量の大きなアプリケーションは閉じておいたほうがいいでしょう。
実行結果
上記の設定でメッセージを送信すると数tok/secから20前後tok/secの応答が得られました。
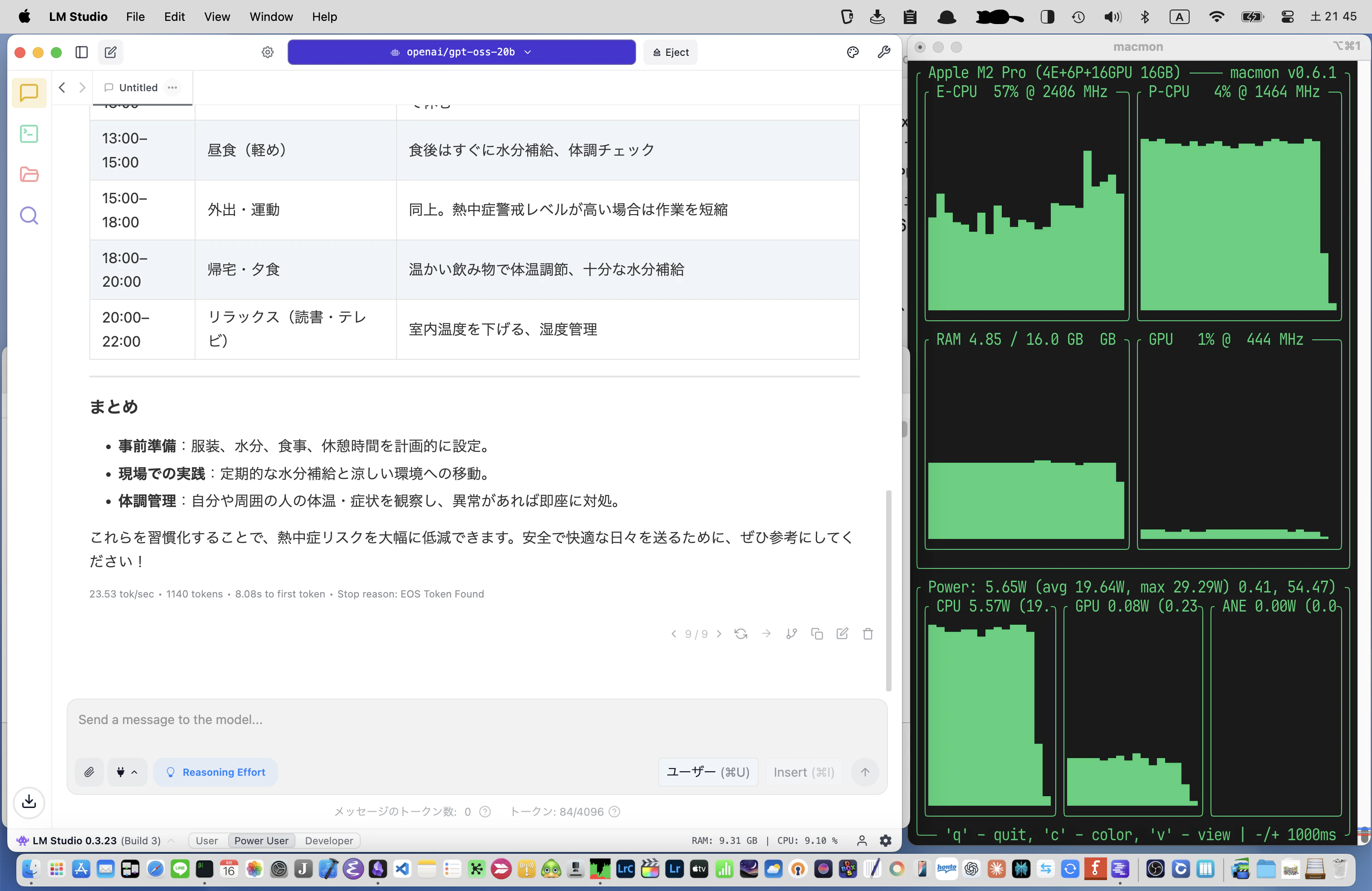
次の図は「 熱中症にならないためにすべきことをまとめてください」というメッセージへの応答例です。23.53tok/secという結果でした。
図の右側がmacmonの出力でCPUが80%程度使用され、GPUはほとんど使用されておらず、メモリの使用量が抑えれているのが分かります。
プログラム生成にはより時間がかかるようです。
最後に
最初、16GBメモリで動作する!とのことで大きな期待をしてしまいましたがMacで16GBメモリではGPU全開での動作はさすがに無理でしたがCPU中心での動作ですが何とか使えるかなという速度ですかね。
今更ですが購入時にメモリをけちるんじゃなかったと公開しました。次の買い替え時は気を付けよう。