はじめに
今更感があるかもしれないけど、flutter_gemmaを知ったのでスマホで自分でローカルLLM動かしたい!となったのでちょっと試した。
今回はとりあえず動かすことが目的なので、flutter_gemmaのQuick Startを眺めながらやってます。
対象の端末はAndroidのみ。
iPhoneでの確認はMacがないのでそもそもできません。
今回のコードはGitHubで確認できます。
導入
以下のコマンドでflutter_gemmaを追加する
> flutter pub add flutter_gemma
pubspec.yamlを確認し、dependenciesに追加されていることを確認する。
dependencies:
flutter_gemma: ^0.11.11
<プロジェクト名>\android\app\build.gradle.ktsのcompileSdkとndkVersionを必要に応じて変更
※これはビルドするとエラーメッセージが出てくるのでそれに従うのがいい
android {
...
compileSdk = 36
ndkVersion = "27.0.12077973"
...
defaultConfig {
...
minSdk = 24
import を追加
import 'package:flutter_gemma/flutter_gemma.dart';
モデルのインストール
モデルのインストールにはHugging Faceのアクセストークンが必要なようです。
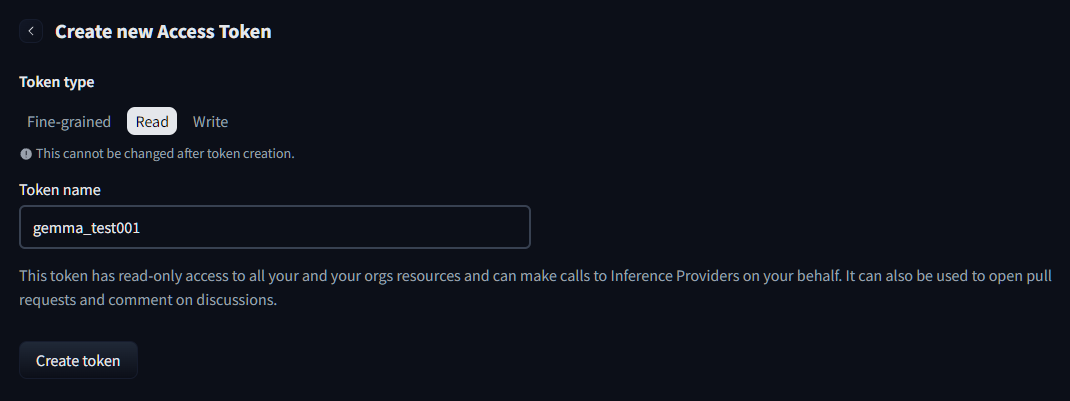
Hugging Faceにユーザー登録を行い、 https://huggingface.co/settings/tokens でアクセストークンを生成します。
Readを選択してCreate Tokenをクリック。
googleのgemma 3nを使用します。
まず、以下ページにアクセスします。
https://huggingface.co/google/gemma-3n-E2B-it-litert-lm
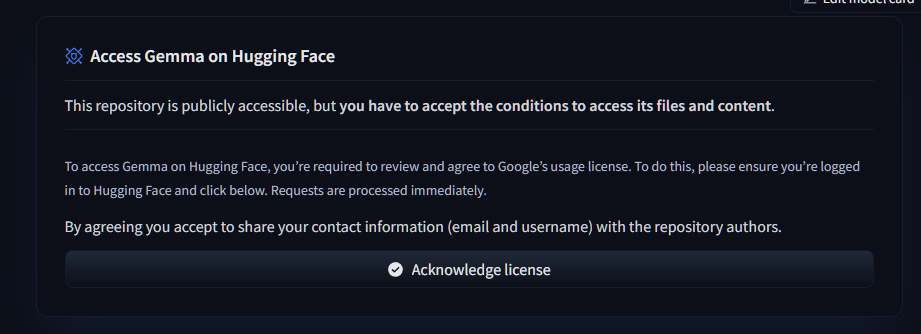
条件に同意する必要があります。
にhン後翻訳して内容を確認し、Acknowledge licenseをクリックします。
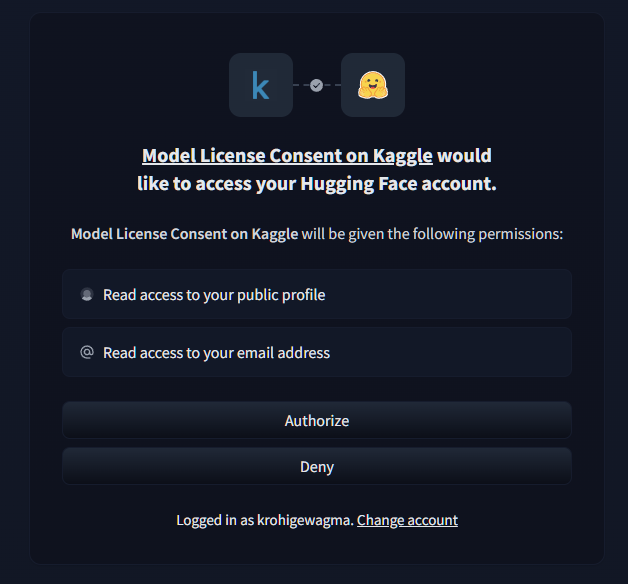
権限の確認が表示されるので、問題なければAuthorizeをクリックします。
Gemma Access Requestが表示されます。
内容を確認し、画面下部のチェックボックスにチェックを入れます。
一つはニュースを受け取るかどうかなのでお好みで。
チェックをしたら、Acceptをクリックします。

これでGemmaを利用できます。
File and versionsをクリックします。
gemma-3n-E4B-it-int4.litertlmのダウンロードURLを控えます。
ちなみに、
https://huggingface.co/google/gemma-3n-E2B-it-litert-lm/resolve/main/gemma-3n-E2B-it-int4-Web.litertlm?download=true
を
https://huggingface.co/google/gemma-3n-E2B-it-litert-lm/resolve/main/gemma-3n-E2B-it-int4-Web.litertlm
に変えて使います
ちなみに扱えるファイルの種類ですが、ドキュメントのModel File Typesに記載されています。
一覧を載せておきますが、詳細は公式ドキュメントを確認してください。
| 拡張子 | 概要 |
|---|---|
| .task | モバイル (Android/iOS) 向け |
| .litertlm | Web向け |
| .bin | 標準バイナリ形式 |
| .tflite | TensorFlow Lite 形式 |
こんな感じでコードを書いてみます。
void main() {
// Gemmaの初期化
WidgetsFlutterBinding.ensureInitialized();
FlutterGemma.initialize(
huggingFaceToken: hugFaceToken,
maxDownloadRetries: 10,
);
runApp(const MyApp());
}
・・・略・・・
/// モデルのインストール
///
/// @param WidgetRef ref
/// @return Future>void<
static Future<void> installModel(WidgetRef ref) async{
final logger = ref.watch(loggerProvider.notifier);
logger.addLog("start install model");
ref.read(installProgressProvider.notifier).state = 0;
await FlutterGemma.installModel(
modelType: ModelType.gemmaIt,
).fromNetwork(
'https://huggingface.co/google/gemma-3n-E2B-it-litert-lm/resolve/main/gemma-3n-E2B-it-int4.litertlm',
token: _hugFaceToken
).withProgress((progress) {
ref.read(installProgressProvider.notifier).state = progress / 100;
})
.install()
.then((value) {
ref.read(modelInstallationProvider.notifier).state = value;
logger.addLog("model : ${value.modelId}");
},onError:(error, stackTrace) {
logger.addLog("ERROR : $error");
})
.whenComplete(() {
var modelInstallation = ref.read(modelInstallationProvider.notifier).state;
logger.addLog("finish install model");
if(modelInstallation != null){
logger.addLog("OK");
}else{
logger.addLog("NG");
}
});
}
初期化処理
まず、初期化は必須
// Gemmaの初期化
WidgetsFlutterBinding.ensureInitialized();
FlutterGemma.initialize(
huggingFaceToken: hugFaceToken,
maxDownloadRetries: 10,
);
モデルのインストール処理
LinearProgressIndicatorを配置してそこに進捗を反映する感じです。
FlutterGemma.installModel(
modelType: ModelType.gemmaIt,
)
インストールするモデルのタイプを指定します。
ModelType Referenceを見ると以下を指定できるようです。
正しいモデルを指定する必要があります。
| Model Family | ModelType | Examples |
|---|---|---|
| Gemma (all variants) | ModelType.gemmaIt | Gemma 2B, Gemma 7B, Gemma-2 2B, Gemma-3 1B, Gemma 3 270M, Gemma 3 Nano E2B/E4B |
| DeepSeek | ModelType.deepSeek | DeepSeek R1, DeepSeek-R1-Distill-Qwen-1.5B |
| Qwen | ModelType.qwen | Qwen 2.5 1.5B Instruct |
| Llama | ModelType.llama | Llama 3.2 1B, TinyLlama 1.1B |
| Hammer | ModelType.hammer | Hammer 2.1 0.5B |
| Phi / Falcon / StableLM | ModelType.general | Phi-2, Phi-3, Phi-4, Falcon-RW-1B, StableLM-3B |
次にインストールするモデルのURLとアクセストークンを指定します。
※アクセストークンは初期化の時に指定しているので、設定しなくてもよいみたい。
).fromNetwork(
'https://huggingface.co/google/gemma-3n-E2B-it-litert-lm/resolve/main/gemma-3n-E2B-it-int4.litertlm',
token: _hugFaceToken
)
モデルのインストールの進捗具合はwithProgressで取得できます。
0~100で値がわたってくるので1/100しています。
).withProgress((progress) {
ref.read(installProgressProvider.notifier).state = progress / 100;
})
最後にインストールの呼び出しと、終了時の処理になります。
_addLog()メソッドは画面のテキストエリアにログを出す自作メソッドなので気にしないでください。
.install()
.then((value) {
ref.read(modelInstallationProvider.notifier).state = value;
logger.addLog("model : ${value.modelId}");
},onError:(error, stackTrace) {
logger.addLog("ERROR : $error");
})
.whenComplete(() {
var modelInstallation = ref.read(modelInstallationProvider.notifier).state;
logger.addLog("finish install model");
if(modelInstallation != null){
logger.addLog("OK");
}else{
logger.addLog("NG");
}
});
thenメソッドはインストールが完了した際の処理を記載します。
onErrorメソッドはエラーが発生した際の処理を記載します。
whenCompleteメソッドはInstall処理の成功、失敗にかかわらず処理が完了すると呼び出されます。
モデルのダウンロードを以下の機種で動かした際の挙動のメモです。
| 機種 | メモ |
|---|---|
| ROG Phone(初代) | すぐにダウンロードが始まった |
| POCO F6 Pro | なぜかダウンロードの開始までに時間がかかった |
| ARROWS We2 | すぐにダウンロードが始まった |
おなじみのHello Worldで試してみる
Gemmaの呼び出しは以下のように実行。
static Future<void> execute(WidgetRef ref, String prompt) async{
final logger = ref.watch(loggerProvider.notifier);
final formatter = DateFormat('yyyy-MM-dd HH:mm:ss.SSS');
var formatted = formatter.format(DateTime.now());
logger.addLog("Start $formatted");
final model = await FlutterGemma.getActiveModel(
maxTokens: 2048,
preferredBackend: PreferredBackend.gpu
);
final chat = await model.createChat();
await chat.addQueryChunk(Message.text(text: prompt, isUser: true));
final response = await chat.generateChatResponse();
if(response is TextResponse){
logger.addLog(response.token);
}else{
logger.addLog('?????');
}
formatted = formatter.format(DateTime.now());
logger.addLog("End $formatted");
}
まずはアクティブなモデルを取得
final model = await FlutterGemma.getActiveModel(
maxTokens: 2048,
preferredBackend: PreferredBackend.gpu
);
チャットを作成
final chat = await model.createChat();
問い合わせと結果を取得
await chat.addQueryChunk(Message.text(text: prompt, isUser: true));
final response = await chat.generateChatResponse();
if(response is TextResponse){
logger.addLog(response.token);
}else{
logger.addLog('?????');
}
実際の実行結果はこんな感じ
ROG Phone(初代)
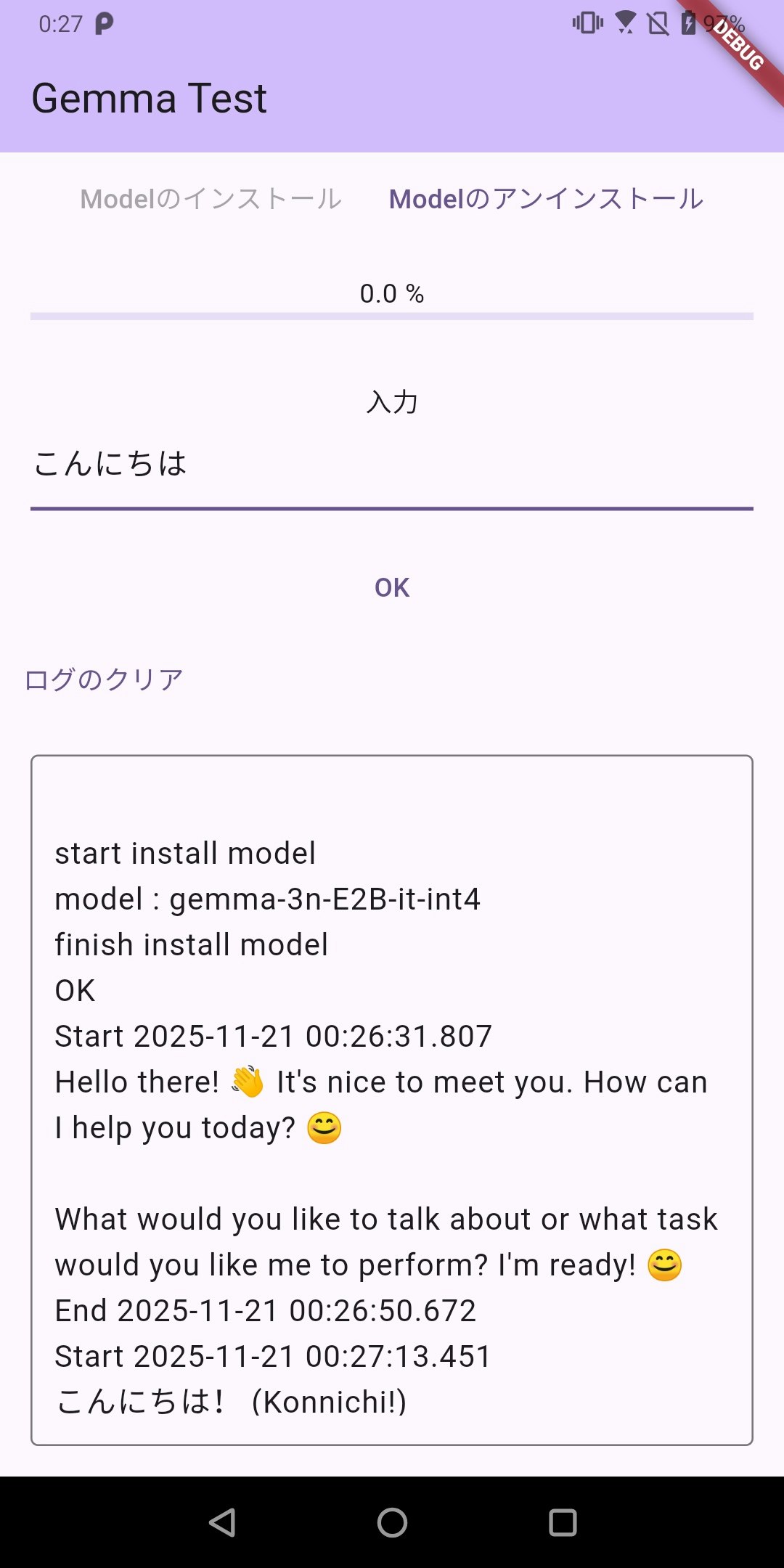
POCO F6 Pro
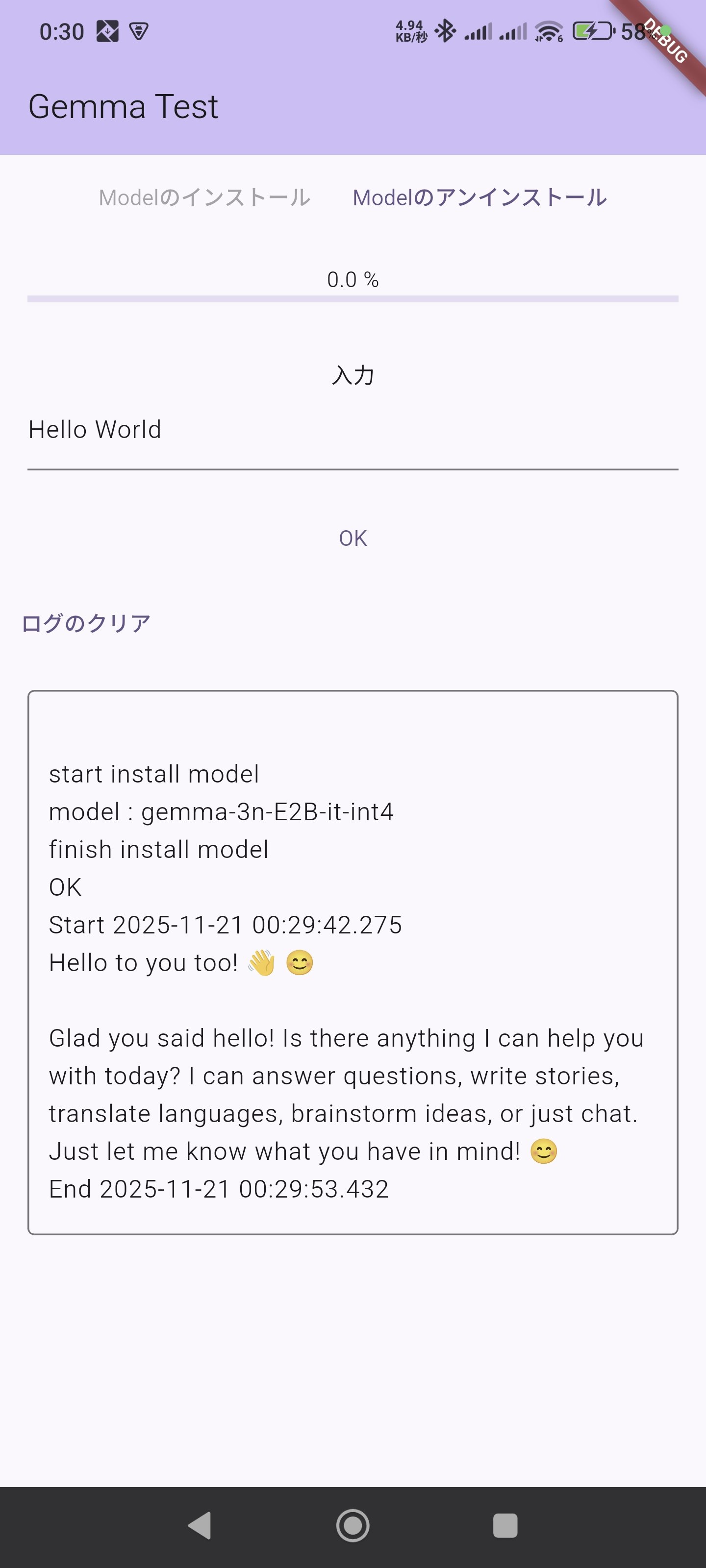
ROG Phoneなんてかなり古いのに意外と動くのがびっくり。
POCO F6 Proのほうが早いのは確かなんだけど、そこまで大きく差が出なかった。
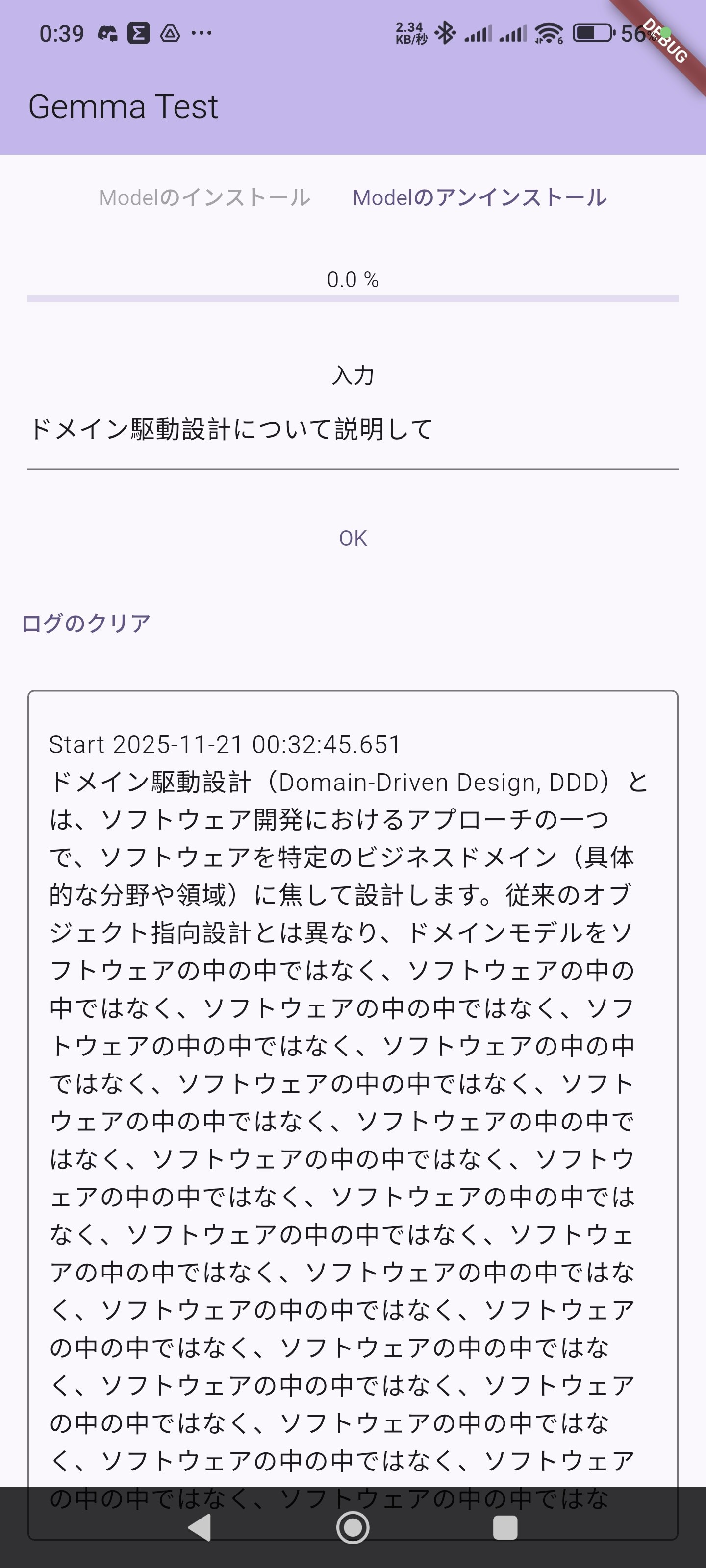
試しに「ドメイン駆動設計について説明して」と聞いたところ、実用的ではなかった・・・
| 機種 | 開始 | 終了 |
|---|---|---|
| ROG Phone(初代) | 2025-11-21 00:33:22.668 | 2025-11-21 00:35:58.809 |
| POCO F6 Pro | 2025-11-21 00:32:45.651 | 2025-11-21 00:36:04.824 |
| Arrows We2 | 測定不能 | アプリがおちたので |
Arrows We2はまぁ、メモリも少ないので当然だよね。
POCO F6 Proのほうは謎の回答になっていたw
ROG Phone(初代)のほうはまともだった
(以下のスクショはPOCOの方)
実行時の注意
トークンをconfig.jsonに記載する場合は、実行時に --dart-define-from-file=config.json を付けて実行してください。
忘れてて、トークン読んでなくてなんでだー!ってなったのでw
まとめ
スマホでローカルLLMはスペックがかなり良くないとちょっと辛そう。
遅さが許容できれば昔のゲーミングスマホでも遊べそうではある。
ただ。アプリへの組み込みはなかなか辛そう。
けど、組み込めたらオフラインで動かせるのでそれはそれでなにかよさそうな気がする。