はじめに
この記事は古川研究室 Workout calendar 3日目の記事です. 本記事は古川研究室の学生が学習の一環として書いたものです.もっちゃんに引き続き回帰関連の話が続きます.
今回はノンパラメトリックな回帰手法の例として, k近傍法と古川研究室で馴染深いNadaraya-Watson推定を取り扱います. また, 随時コードと実行結果を乗せて解説していきます.
回帰
回帰とは機械学習のタスクの一つです.
問題設定(今回はラベルの次元が1固定)
given: $D$次元ベクトルの観測データ $\mathbf{x} \in \mathbb R^D$とラベル $y \in \mathbb R$のペアの集合$\left\{ ( \mathbf{x}_n,y_n )\right\} _{n=1}^N $
estimate: $y \simeq f(\mathbf{x})$となるような写像 $f$
写像$f$を得ることによって, 新規観測データ$\mathbf{x}^\ast$のラベル$y^\ast$を求めることができます.
回帰の具体例
例えば, アイスクリーム屋のその日の売り上げが知りたいとします.
過去のデータとして日毎の売上と温度・湿度・日照量があり,
売り上げと天気情報の関係を知ることで, 当日の天気予報から当日のアイスクリームの売上の予測をします. これが回帰の使われ方です.
実装
今回は$D=1$としてデータ ${x}$を生成します.さらに,真の関数を $f = \sin(x)$として, それぞれのデータ$x_i$に対応するラベル $y_i$ を$y_i = f(x_i) + \epsilon$ として生成し,このペアの集合を入力とします. $\epsilon$ はノイズです.
人工データの生成のプログラムが以下になります.
import numpy as np # jypyterなら %matplotlib inline
import matplotlib.pyplot as plt
n = 20 #データ数
X_n = 1000 #任意のxの数(写像の解像度)
x = np.linspace(-np.pi,np.pi,n)+ np.random.randn(n)/4 #データ
y = np.sin(x) + np.random.randn(n)*0.1 # ラベル
x_star = np.linspace(-np.pi*1.5,np.pi*1.5,X_n) # 任意のx
y_star = np.sin(x_star) # 真の写像
これをプロットしたものは
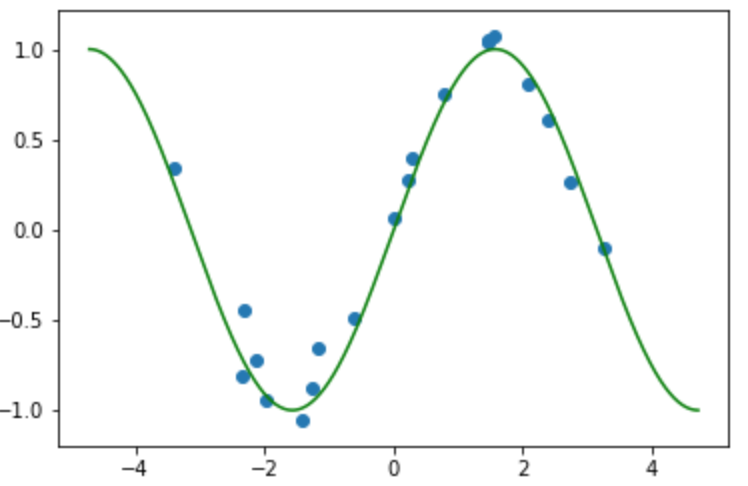
横軸はデータ$x$軸, 縦軸はラベル$y$軸の図です. 真の関数(緑線)にノイズが加わってラベルが生成されているのがわかります.
真の関数がわからない中で,データとラベル集合を使って写像を推定していきます.
回帰手法
写像$f$を求めるのに様々な手法があります.
例えば, 線形回帰では パラメータ$\mathbf w$を使って写像が$f_\mathbf{w}(\mathbf x_n) = (w_1x_{n1}+w_2x_{n2} +\dots +w_D x_{nD}) = \mathbf w^\mathrm{T} \mathbf{x}_n$として表現できると仮定し, 写像を推定する問題をパラメータ$\mathbf w$の推定問題に帰着させます. そして二乗誤差の総和を目的関数として定め, 目的関数の最適化を行いパラメータを推定します.
今回紹介するk近傍法, Nadaraya-Watson推定はパラメータを写像$f$をラベル$y$を使う形で直接推定します.
k近傍法
機械学習の初歩的な学習器で一般的にはクラス分類に使われる手法です.
任意のデータ$\mathbf{x}$に対するラベル$y$を、そのデータ近傍にある$k$個のデータのラベルから推定します. 一般には, $k$個の近傍のラベルの平均を $f(\mathbf{x})$ として, 次式で表します.
$f(\mathbf{x}) = \frac{1}{k}\tag{1} \sum_{i \in N_k(\mathbf{x})} y_i$
ここで, $N_k (\mathbf{x})$は$\mathbf{x}$からの二乗距離がもっとも小さい$k$個の点のインデックス集合を表します.
実装
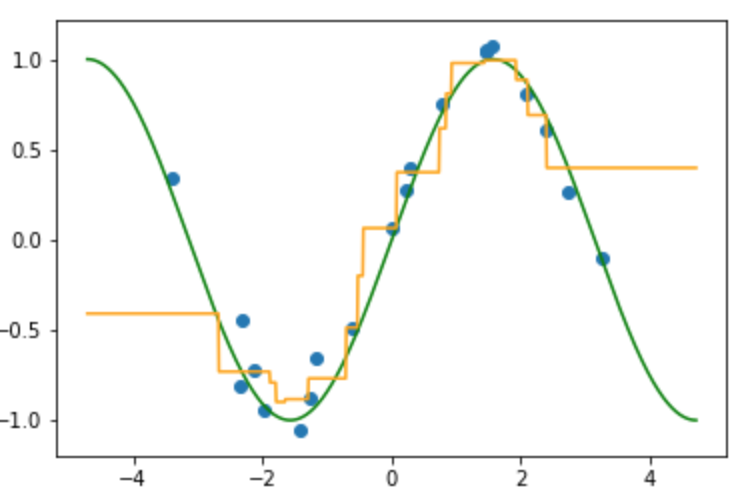
先ほどと同様に真の関数(緑線)にノイズが加わり入力(青点)が得られている状況から写像$f$(オレンジ線)を推定しています.
k = 4 # NumpyのBroad cast と fancy indexは神
Delta = x[:,None] - x_star[None,:] #データ点と任意のxを全ての差を計算
Dist = np.square(Delta) #距離として扱う
neighbor_index = np.argsort(Dist, axis=0)[:k,:] #小さい順にソートし, k個の近傍のindexを得る
Y = np.sum(t[neighbor_index],axis=0)/k #今回は平均をとる
近傍にとる数を変えながら順次プロットしたものが以下の画像になります.
(k=4のとき)
(k=10のとき)
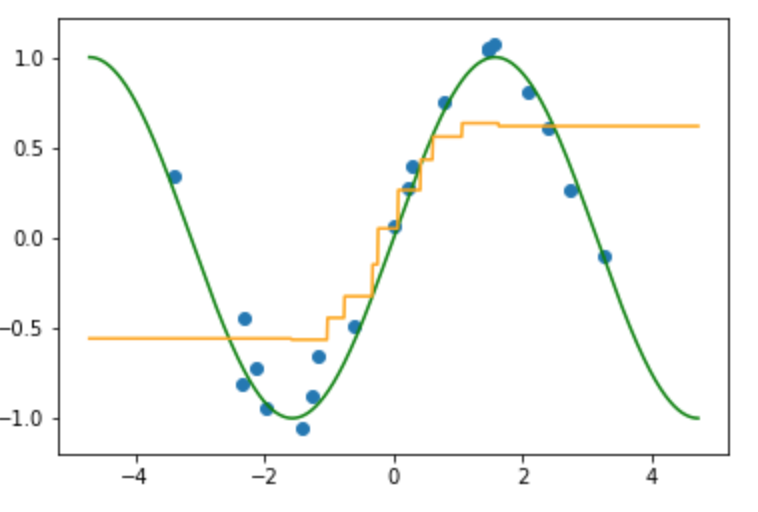
k の数を増やすと全体の平均に近づく. k=データ点のときは完全に平均になる.
(k=1のとき)
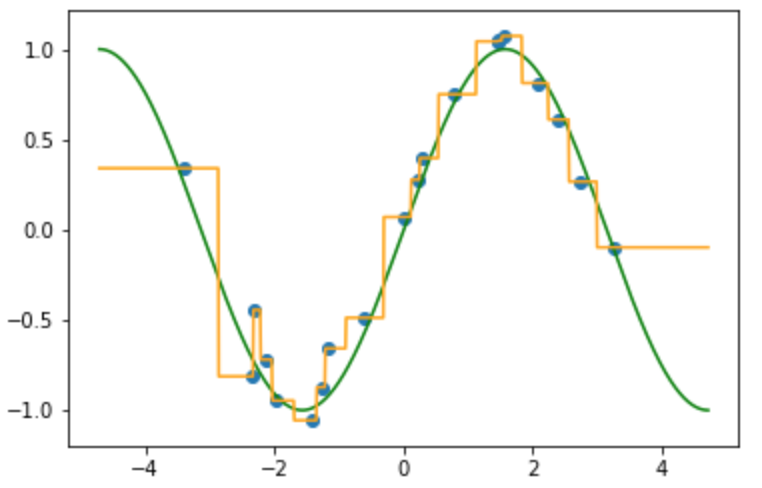
kの数1にすると, ちょうど近傍が変わる$x$は隣り合うデータの中点となる.
まとめ
$f(\mathbf{x})$は不連続になっていて自分の精神衛生的に気持ちよくないです.
写像を滑らかにするようにとるNadaraya-Watson推定は4日後に投稿予定です. また, そこではk近傍法との関連も述べます.
参考文献
Trevor Hastie・Robert Tibshirani・Jerome Friedman著, 杉山 将・井出 剛 ら監訳 「統計的学習の基礎」 $\S 6$ p.220~