TensorFlowに限った話ではありませんが、最近は多くの深層学習ライブラリで確率分布関係の実装が充実してきているようです。生成系のモデルを作るときに使えるらしいので、学んだことをメモしておきます。
Distributionクラス
TensorFlowのPython APIでは、確率分布はすべてDistributionクラスを基底とするクラスとして定義されています。僕の理解の範囲では、使うことがありそうなDistributionクラスの属性とメソッドはこのあたりです。詳細はtf.distributions.Distributionのドキュメントをご参照ください。
属性
| 名前 | 説明 |
|---|---|
| batch_shape | バッチの形、つまり個々のサンプルの並びの形 |
| event_shape | 個々のサンプルの形 |
| parameters | 各確率モデルが持つパラメータ |
メソッド
| 名前 | 説明 |
|---|---|
| prob | 確率変数が入力値と等しくなる確率(密度)を計算する |
| log_prob |
probの対数を取ったものを計算する |
| entropy | 確率分布のエントロピーを計算する |
| cross_entropy | 確率分布間の交差エントロピーを計算する |
| kl_divergence | 確率分布間のKL距離を計算する |
| mean | 確率変数が取る平均値を計算する |
| variance | 確率変数の各次元の分散を計算する |
| covariance | 確率変数の分散・共分散行列を計算する |
使用例
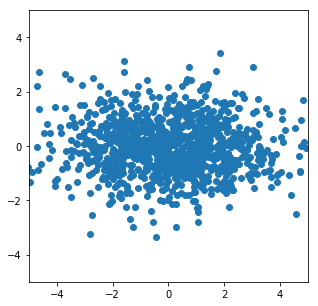
具体例として、独立した2次元の確率変数上の正規分布をMultivariateNormalDiagを使って定義し、そこからサンプリングを行いました。以下のコードは簡潔さのために、TensorFlowのEager Execution機能を利用しています。
import numpy as np
import tensorflow as tf
import tensorflow.contrib.distributions as tfd
import tensorflow.contrib.eager as tfe
import matplotlib.pyplot as plt
tfe.enable_eager_execution()
# モデル1を定義
# 平均: [0, 0]
# 分散・共分散行列:
# [[2, 0],
# [0, 1]]
# の正規分布
model1 = tfd.MultivariateNormalDiag(
loc = np.zeros(2, dtype=np.float32),
scale_diag = np.array([2,1], dtype=np.float32)
)
# モデル1から1000個の点をサンプリング
sampled = model1.sample(1000).numpy() # shape=(1000, 2)
# プロット
plt.figure(figsize=(5,5))
plt.scatter(x=sampled[:,0], y=sampled[:,1])
plt.xlim([-5.0, 5.0])
plt.ylim([-5.0, 5.0])
出力:
KL距離の計算
同じ種類の確率分布の間であれば、KL距離等の計算が簡単にできます。モデルをもうひとつ定義して計算してみます。
# モデル2を定義
# 平均: [3, 3]
# 分散・共分散行列:
# [[1, 0],
# [0, 1]]
# の正規分布
model2 = tfd.MultivariateNormalDiag(
loc = np.array([3,3], dtype=np.float32),
scale_diag = np.array([1,1], dtype=np.float32)
)
print(model1.kl_divergence(other=model2))
出力: tf.Tensor(9.806852, shape=(), dtype=float32)
これで、例えば変分自己符号化器(VAE)の損失関数の項が簡単に計算できたりします(gist)。
Independentクラスによるbatch_shapeとevent_shapeの指定
例として、10x28x28の大きさの確率変数をもった確率分布があったとします。この確率分布は、28x28のサイズの画像を10枚生成するためのモデルかも知れませんし、そうではなく本当に10x28x28の大きさの3次元配列を生成するためのモデルかもしれません。形式的な違いですが、この違いをDistributionクラスの属性であるbatch_shapeとevent_shapeを使って表すことができます。
例として、次のようにモデルを定義してみます。
model = tfd.Bernoulli(np.zeros((10,28,28), dtype=np.float32))
デフォルトではこのmodelのbatch_shapeとevent_shapeは次のようになっています。
| 変数 | 値 |
|---|---|
| model.batch_shape | [10,28,28] |
| model.event_shape | [ ] |
これは、ゼロ次元、すなわちスカラー値である確率変数を[10x28x28]個生成するモデルであることを表しています。これを[28x28]の大きさの確率変数を10個生成するモデルとして扱いたい場合には、Independentクラスを利用して変形させます。
model = tfd.Independent(model, reinterpreted_batch_ndims=2)
引数のreinterpreted_batch_ndimsで、元のbatch_shapeの後ろからいくつをevent_shapeに移すかを指定しています。これを指定しない場合は、(batch_shapeの次元)-1を指定したのと同じ扱いになるようです。バッチサイズは1次元であることがほとんどでしょうから、実際に指定する場面は稀でしょう。上の処理によって、modelの中身は次のようになりました。
| 変数 | 値 |
|---|---|
| model.batch_shape | [10] |
| model.event_shape | [28,28] |
意図した形になったことがわかります。
Mixtureクラスによる混合分布の作成
ガウス混合分布(GMM)等、複数の分布を重み付けして足し合わせたいことがあります。そのような時はMixtureクラスを利用します。先ほど定義したmodel1とmodel2を同じ重みで足しあわせてサンプリングしてみました。
# model1とmodel2を同じ重み0.5で足し合わせる
gm = tfd.Mixture(
cat=tfd.Categorical([.5, .5]),
components=[model1, model2])
# プロット
sampled = gm.sample(1000).numpy()
plt.figure(figsize=(5,5))
plt.scatter(x=sampled[:,0], y=sampled[:,1])
plt.xlim([-5.0, 5.0])
plt.ylim([-5.0, 5.0])
出力:
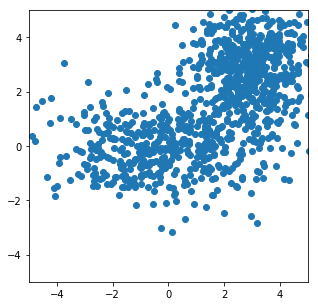
出力を見るに、混合分布からうまくサンプリングできているようです。注意が必要なのは、MultivariateNormalDiagやBernoulliといったピュアな確率分布で使えていたentropyやkl_divergenceといったメソッドが、Mixtureにした時点で使えなくなるという点です。latent spaceに複雑な分布を想定したモデルの実装等はまだ難しいかもしれません。
まとめ
TensorFlowにおける確率分布の基本的な使い方を調べました。