自前のデータセットを使って画像のクラス分類をしたいとき、学習済みモデルを使った転移学習が一番手軽かと思います。
中でもKerasは最もコード量が少なく済むし分かりやすいものです。
この記事は、機械学習のプロジェクトをまだ実装したことが無い、かつチュートリアルを読みたくない人のためのガイドです。
また、データセット収集、学習、推論実行 をそれぞれスクリプトに実装したので、新たなプロジェクトの土台に使えるかもしれません。
colabは使用せずに完全にローカルでやります
完全なコードはこちら
本来は次のチュートリアルとガイドをなぞることで、「画像の多クラス分類」を実装できるようになります。
- はじめてのニューラルネットワーク:分類問題の初歩
- モデルの保存と復元
- 転移学習とファインチューニング
- Keras Tuner の基礎
この記事で作るもの
webカメラを使ってリアルタイムで手のハンドサインを識別します。

カメラ映像の一部分に枠を描き、その一部分を学習/推論に使用します。
将来的には、[オブジェクト検出] → [検出部分で推論]... という流れにする想定しています。
その他の条件と仕様
- すべてWindowsのローカルで行う
- 学習推論ともに使用するのはGrayScale画像
- サイズは (240, 320)
- ハンドサインのクラス分けは7種類
- ok
- good
- bad
- scissors
- rock
- paper
- none (手が映っていない)
- 機能それぞれ別のスクリプトに実装
- 収集: collect.py
- 学習: training.py
- 推論: predict.py
- 学習したモデルはファイルに出力して使用
- 学習はKeras 推論はTensorFlowで行う
- Kerasは遅いので30fps出ない可能性がある
識別するもの↓
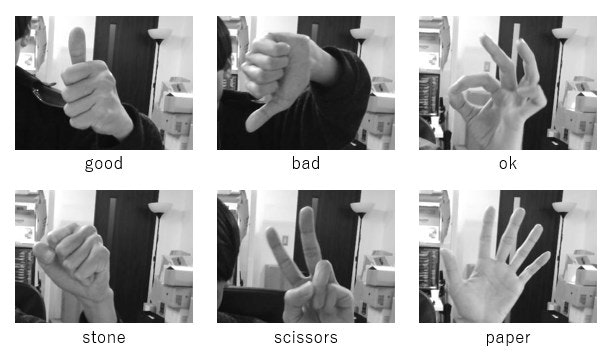
これに加えて手が映っていないnone
環境
推論はともかく、学習ではGPUを使いたい
ネイティブなWindwosでGPUをサポートするのがTensorFlow 2.9.0まで
従って環境は TensorFlow 2.9 + CUDA + cuDNN となる
推論ではCPUのみか、少なくともプアな環境を想定する。
データセットを集める collect.py
これを実行して、画像を集めてください。
カメラキャプチャが始まり、画面上に描かれたキーを押すと
、それに従って画像を./dataset/配下に保存していきます。
ESCで終了すると、画像を何枚保存したか出力します。

数分やって1803枚の画像が集まりました。
あんまりやると学習に時間がかかるのでとりあえずこの辺で止めましょう。
$ py .\collect.py
# ok 214 ./dataset/ok
# good 339 ./dataset/good
# bad 216 ./dataset/bad
# scissors 253 ./dataset/scissors
# rock 210 ./dataset/rock
# paper 493 ./dataset/paper
# none 78 ./dataset/none
# total: 1803
collectの解説
保存先
このあとの学習フェーズではimage_dataset_from_directoryで画像をDataSetとして読み込みます。
これはディレクトリ構造からラベル名を生成します。ラベル名をディレクトリ名にするのは一般的なことでもあるっぽい。
機械学習的には、データを training, validation, test と、後に三種類の目的別へ分けることになりますが、どうせランダムに分割するなら、KerasのDataSetオブジェクトにした後、コード上で分けた方が楽です。今回は1つのdatasetディレクトリへ集めることにしました。
まず、こんなディレクトリ構造を作る
dataset
├─bad
├─good
├─none
├─ok
├─paper
├─rock
└─scissors
# ラベル一覧
LABELS = [
"ok",
"good",
"bad",
"scissors",
"rock",
"paper",
"none",
]
# ラベルに対応する保存先の辞書 {ラベル名, 保存先ディレクトリ}
DIRS = {label: f"./dataset/{label}" for label in LABELS}
# 画像保存先ディレクトリを作る
for dir in DIRS.values():
os.makedirs(dir, exist_ok=True)
保存
あとはここにこんな感じで保存していく。
単純に保存してしまうとカメラのfps分取ってしまい同じような画像が集まりすぎるので、2/3は捨てつつ、ファイル名には時間とミリ秒まで入れる。
CAMERA_IDX = 0
# 保存する画像サイズ (height, width)
DATA_IMG_SIZE = (240, 320)
# DATA_IMG_SIZEを切り出す左上の座標 (top, left)
P = (40, 280)
# DATA_IMG_SIZE, P から座標を計算
top, left = P
bottom, right = tuple(x+y for (x, y) in zip(P, DATA_IMG_SIZE))
# カメラループ
cap = cv2.VideoCapture(CAMERA_IDX)
while True:
# キャプチャ
_, frame = cap.read()
# 鏡映しにする
frame = cv2.flip(frame, 1)
# 保存する部分 320x240 を切り出し
top, left = P
bottom, right = tuple(x+y for (x, y) in zip(P, DATA_IMG_SIZE))
# 描いたものが入らないようにコピーを控えておく
data = frame[top:bottom, left:right].copy()
# dataをGrayScaleにする
data = cv2.cvtColor(data, cv2.COLOR_BGR2GRAY)
# 切り出した部分にrectを描く
cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0))
cv2.imshow('camera', frame)
# キーボード入力
key = cv2.waitKey(2)
if key == 27: # ESCで終了
cv2.destroyAllWindows()
break
if not key:
continue
# ラベル名ディレクトリで保存
# 保存ファイル名が被らないようにdatetimeのmsまで使う
now = datetime.datetime.now().strftime('%m%d%H%M%S%f')
# NOTE キーを押しっぱなしにすると画像を保存しすぎてしまうので、適当に保存タイミングを減らす
if 0 != (int(now) % 3):
continue
elif key == ord('o'): # ok
filepath = f"{DIRS['ok']}/ok_{now}.png"
cv2.imwrite(filepath, data)
elif key == ord('g'): # good
filepath = f"{DIRS['good']}/good_{now}.png"
cv2.imwrite(filepath, data)
elif key == ord('s'): # scissors
filepath = f"{DIRS['scissors']}/scissors_{now}.png"
cv2.imwrite(filepath, data)
# ~~~~~~~~~~~~~~
モデルをビルドして学習する training.py
これを実行して、モデルをビルド、学習、保存します。
ファイル数が1449のとき、私のマシンでは1分くらいで終わります。
(Intel Core i7-10700, NVIDIA GeForce RTX 3070)
カメラが固定で、手も自分ひとりなら、evaluate結果もこれで申し分ない。
$ py ./training.py
# Found 1449 files belonging to 7 classes.
# => dataset.element_spec: (TensorSpec(shape=(None, 240, 320, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None,), dtype=tf.int32, name=None))
# => dataset.class_names(labels): ['bad', 'good', 'none', 'ok', 'paper', 'rock', 'scissors']
# => cardinality: 57
# => cardinalities: {'training': 38, 'validation': 15, 'test': 4}
# ~~~~~~~~~~~~~~~~~~~
# => model.evaluate(test_dataset)
# => * loss: 0.017505
# => * accuracy: 0.992188
# => savedmodel: mymodel
trainingの解説
1. datasetを読み込み
image_dataset_from_directoryを使用してラベル名のディレクトリ構造を持ったローカルの画像をDataSetとして読み込みます。
DATA_DIR = r"./dataset"
# ======== ローカルからDatasetを準備 ========
dataset: tf.data.Dataset = tf.keras.utils.image_dataset_from_directory(
DATA_DIR,
shuffle=True,
image_size=IMG_SIZE,
color_mode='grayscale',
)
labels = dataset.class_names
cardinality = tf.data.experimental.cardinality(dataset).numpy()
# datasetの情報を見ておく
print("=>", "dataset.element_spec:", dataset.element_spec)
print("=>", "dataset.class_names(labels):", labels)
print("=>", "cardinality:", cardinality)
ここで、念のため element_spec, class_names, cardinality を確認しています。
- dataset.element_spec: (TensorSpec(shape=(None, 240, 320, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None,), dtype=tf.int32, name=None))
- dataset.class_names(labels): ['bad', 'good', 'none', 'ok', 'paper', 'rock', 'scissors']
- cardinality: 57
特にclass_namesは重要で、ソートされたラベル名リストですが、これはSavedModelに保持されません。
predictで使用するので、メモっておきます。
cardinalityはbatchの数であり、batch-size はデフォルトで32です。
データファイル数は 1803 だったので、math.ceil(1803/32)->57 ということです。
2. datasetを train用, validation用, test用 に分ける
こんな感じで大体7:3:1 くらいに分けています。
見苦しい感じだけど TF2.9 ではsplit_datasetが無いのでtakeとskipでやるしかなさそう。
# train:validation:test を 7:3:1 くらいに分ける
# NOTE TFのバージョンが新しければ、split_datasetでスマートにできる
# https://www.tensorflow.org/api_docs/python/tf/keras/utils/split_dataset
vali_cardinality = 3*cardinality // 11
test_cardinality = 1*cardinality // 11
train_cardinality = cardinality - vali_cardinality - test_cardinality
vali_dataset = dataset.take(vali_cardinality)
__dataset = dataset.skip(vali_cardinality)
test_dataset = __dataset.take(test_cardinality)
__dataset = __dataset.skip(test_cardinality)
train_dataset = __dataset
3. モデルをbuild
MobileNetV2をベースとして、input,前処理,pooling,dense を加えて都合のいいものにします。
転移学習とファインチューニングのガイドではカラー画像の二値分類なのに対して、今回はGrayScaleの多クラス分類なので、随所違うところに注意してください。
NOTE Kerasで使用できる定義済み/学習済みモデルは結構種類がある
https://keras.io/api/applications/
この中で、MobileNetV1、MobileNetV2は圧倒的に推論処理時間が短い
V1の方が処理時間は短いが、今回の状況ではV2でも十分な速さであり、精度が高いのでこちらを使う
ちなみに次のハイパーパラメータと選択は大体で決め打ちしたが、これがベストという訳ではない。
KerasTunerを使用して最適値を求めることで、より精度が上がるはず。
- LEARNING_RATE
- EPOCHS
- FINE_TUNE_AT
- data_augmentation やる/やらない
- dropout やる/やらない
- dropoutのrate
- optimizerの種類
IMG_SIZE = (240, 320)
LEARNING_RATE = 0.00001
EPOCHS = 50
FINE_TUNE_AT = 100
# ======== Model作成 ========
# ベースモデルとして事前トレーニング済みモデル`MobileNetV2`を使う
mobileNetV2 = tf.keras.applications.MobileNetV2(
input_shape=IMG_SIZE + (3,),
include_top=False,
weights='imagenet')
# 指定の深さから上部を FineTuning するとして、それ以下をフリーズする
mobileNetV2.trainable = True
for layer in mobileNetV2.layers[:FINE_TUNE_AT]:
layer.trainable = False
# こうゆう形 => (None, 240, 320, 3) -> MobileNetV2 -> (None, 8, 10, 1280)
# 入力のTensor GrayScale
# NOTE `name`はつけておくと後でいいことがある
inputs = tf.keras.Input(name="input", shape=(IMG_SIZE+(1,)))
# ピクセル値正規化
x = tf.keras.applications.mobilenet_v2.preprocess_input(inputs)
# データ増強層 data_augmentation (学習時のみ有効になり、推論実行時にはなにもしないレイヤになる)
x = tf.keras.Sequential([
tf.keras.layers.RandomRotation(0.2),
])(x)
# grayscale_to_rgb
x = tf.image.grayscale_to_rgb(x)
# CNN層 取得した事前学習済みモデル
x = mobileNetV2(x)
# プーリング層
x = tf.keras.layers.GlobalAveragePooling2D()(x)
# ドロップアウト
x = tf.keras.layers.Dropout(0.03)(x)
# output 全結合層 ラベルの数でDenseする
# NOTE `name`はつけておくと後でいいことがある
outputs = tf.keras.layers.Dense(len(labels), "softmax", name="output")(x)
# model生成, コンパイル
model = tf.keras.Model(inputs, outputs)
model.compile(
optimizer=tf.keras.optimizers.RMSprop(learning_rate=LEARNING_RATE),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy(name='accuracy')]
)
# こうゆう形 => (None, 240, 320, 1) -> model -> (None, 7)
model.summary()して input, output のShapeを見ると
240*320のGrayScaleを入力として、7要素(クラス毎の確立)を出力することが分かります。
- input (InputLayer) [(None, 240, 320, 1)]
- output (Dense) (None, 7)
inputs、outputsには属性nameを付けたが、これはTensorFlowでpredictするときに少し助かることがある (後述)
3. fit
EarlyStoppingを使用することで過学習を防ぎやすくなりますが、patienceがデフォルトの0だと事故で速攻終わることがしばしばあるので3にしました。
history = model.fit(
train_dataset,
epochs=EPOCHS,
validation_data=vali_dataset,
callbacks=[
tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=3
),
]
)
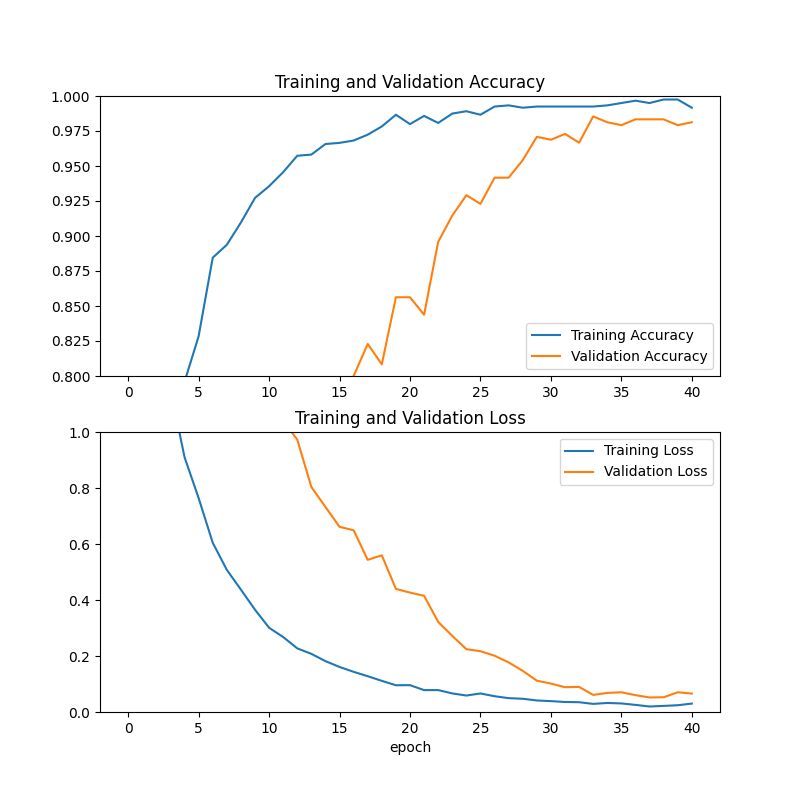
historyをplotすると、素直な形をしています。
少ないdatasetと適当なパラメータにしては結構良さそうです。
EarlyStoppingによってepochは40で止まったようです。
4. モデルを試す
model.evaluate(test_dataset)を実行すると数値が見えます。
loss, accuracy = model.evaluate(test_dataset)
print("=>", "model.evaluate(test_dataset)")
print("=>", f"* loss: {loss:.6f}")
print("=>", f"* accuracy: {accuracy:.6f}")
# => model.evaluate(test_dataset)
# => loss: 0.050037
# => accuracy: 0.992188
大体良いのは分かりますが、具体的に見たいのでこんな感じで出力してみました。
__image_batch, __label_batch = next(iter(test_dataset))
plt.figure(figsize=(10, 8)).suptitle("fine tuned model")
for i in range(16):
plt.subplot(4, 4, i + 1)
img = __image_batch[i]
idx = __label_batch[i]
plt.imshow(img)
input_img = np.expand_dims(img, axis=0)
ret = model(input_img)
ret = ret.numpy()[0]
max_val = np.amax(ret)
max_idx = np.argmax(ret)
plt.title(
f"{labels[idx]} {labels[max_idx]} {max_val:.2f}")
plt.axis("off")
plt.tight_layout()
plt.savefig("tryModel.png")
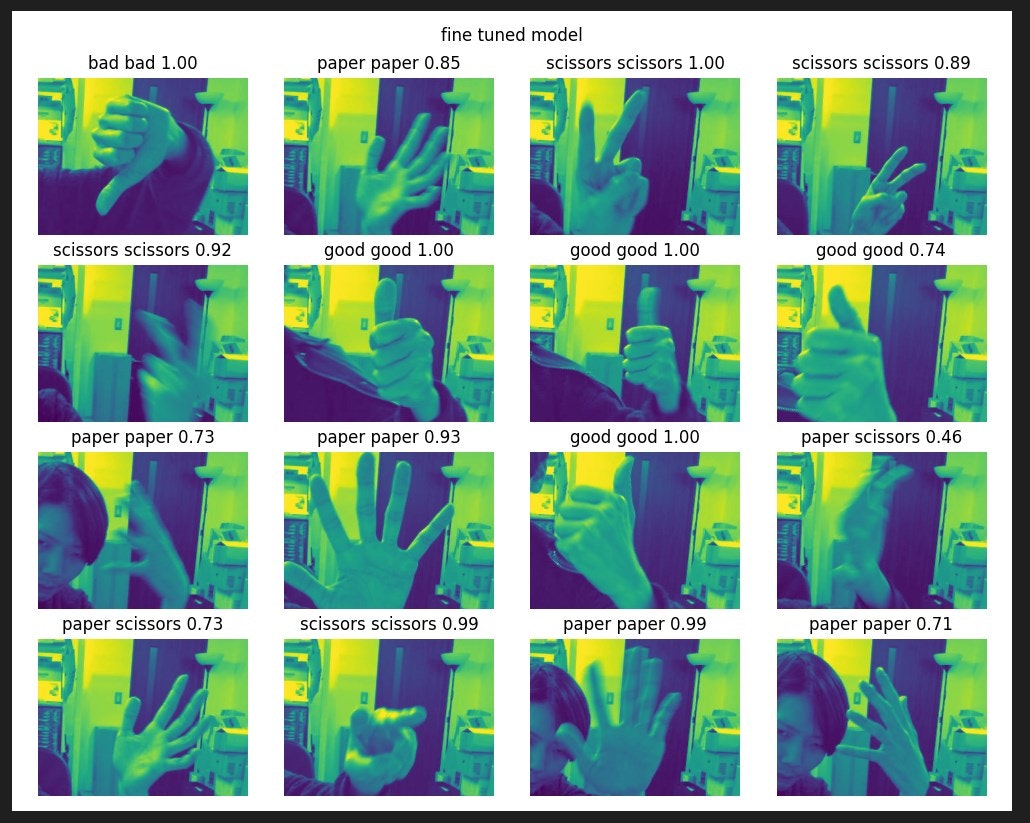
画像中のキャプションは正解_推論結果_推論の確立となります。
クッキリしたものはちゃんと正解し、怪しいものは確度が低かったり間違えたりすることが分かります。
5. モデルをSavedModelに保存する
学習したモデルを、TensorFlowで再利用可能なSavedModel形式にExportします。
存在した場合、上書きすることに注意。
TITLE = "mymodel"
model.save(filepath=TITLE, save_format="tf")
SavedModelをロードして推論する predict.py
これを実行するとカメラキャプチャが始まり、画面上に描かれた枠内のハンドサインを、trainingで保存したモデルを使って推論します。
$ py predict.py
多少ボロめなノートPCなどでも30fpsで動作します。

predictの解説
コードはほとんどcollect.pyと同じで、ファイル保存の機構の代わりにpredictしています。
SavedModelをTensorFlowで使用する場合の注意点は、ラベル情報を持たないことと、
input,outputのTensorの形状です。
trainingでbuildしたmymodelは、次の入出力を持つことが分かっています。
- input (InputLayer) [(None, 240, 320, 1)]
- output (Dense) (None, 7)
ロードしたmymodelからさらに詳しく見ると
>>> infer.structured_input_signature
((), {'input': TensorSpec(shape=(None, 240, 320, 1), dtype=tf.float32, name='input')})
>>> infer.structured_outputs
{'output': TensorSpec(shape=(None, 7), dtype=tf.float32, name='output')}
先頭のNoneはBatchで実行するためのindexなので、一枚画像で実行するときは[0]で読み飛ばして良さそうです。
問題は、どちらもTensorでありその形を意識しないと使えないということです。
1. SavedModel読み込み
loaded_model = tf.saved_model.load(saved_model)
infer = loaded_model.signatures[
tf.saved_model.DEFAULT_SERVING_SIGNATURE_DEF_KEY
]
2. 画像を入力する
推論するためには、画像を入力として有効な形にしないとなりません。
>>> infer.structured_input_signature
((), {'input': TensorSpec(shape=(None, 240, 320, 1), dtype=tf.float32, name='input')})
keyである'input'は、モデルをビルドしたときに
name指定したものであり、指定していないとランダムになっています
OpenCVでキャプチャしてGrayScaleにすると、shape: (height, width)のdtype: intになっています。
従って、reshapeとto_tensor, 辞書化が必要になります。
data = img.reshape(1, *DATA_IMG_SIZE, 1)
data = tf.convert_to_tensor(data, dtype=tf.float32)
feed = {"input": data}
res = infer(**feed)
3. 結果を解釈する
resを得ましたが、これもinfer.structured_outputsに従って解釈します。
>>> infer.structured_outputs
{'output': TensorSpec(shape=(None, 7), dtype=tf.float32, name='output')}
keyである'output'は、モデルをビルドしたときに
name指定したものであり、指定していないとランダムになっています
- key
outputの要素でTensorにアクセス - Tensorに
[0]で実データ(確立リスト)にアクセス - ソートされたラベル名リストとzipしてtupleにする
- [(`bad',その確率), ('good',その確率), ('none',その確率)...] のようになる
- 最も確率の高いものを得るには、このtupleを確立順でソートするか、max値でラベルを選択する
推論結果の実データはラベルを持たないが、ラベルリストのソートと同じindex順序です
LABELS = ['bad', 'good', 'none', 'ok', 'paper', 'rock', 'scissors'] # これはソートされた順序
res_list = res["output"][0].numpy()
res_pairs = zip(LABELS, res_list)
# 最も確率の高いもの
res_sorted_pairs = sorted(res_pair, key=lambda x: -x[1])
label, rate = res_sorted_pairs[0]
4. クラスでの実装
実装ではclassにしました。
NOTE マジックナンバーに感じるなら動的に確認することもできる
SAVED_MODEL_INPUT_KEYWORD,SAVED_MODEL_OUTPUT_KEYWORDは、traing時のTensor定義でname指定したもの
今回はハードコーディングしているが、training時にテキストファイルに出力してもいいし、predict時には次の属性を使って動的に決定することもできる
- infer.structured_input_signature
- infer.structured_outputs
# SavedModelディレクトリ名
SAVED_MODEL = "mymodel"
# ラベル一覧
SAVED_MODEL_LABELS = ['bad', 'good', 'none', 'ok', 'paper', 'rock', 'scissors']
# モデル設計時にname指定したinputとoutputの名前
SAVED_MODEL_INPUT_KEYWORD = "input"
SAVED_MODEL_OUTPUT_KEYWORD = "output"
class MyTFModel:
# ラベル一覧 SavedModelはラベル情報を持たず、クラス分け結果はsortした順番に保持します
LABELS = np.sort(SAVED_MODEL_LABELS)
def __init__(self, saved_model):
loaded_model = tf.saved_model.load(saved_model)
self.infer = loaded_model.signatures[
tf.saved_model.DEFAULT_SERVING_SIGNATURE_DEF_KEY
]
self.input_key = SAVED_MODEL_INPUT_KEYWORD
self.output_key = SAVED_MODEL_OUTPUT_KEYWORD
def predict(self, img: np.ndarray) -> list[tuple[str, float]]:
"""画像を MyTFModel.LABELS にクラス分類する
Args:
img (np.ndarray): shape (240, 320) であるGrayScale画像
Returns:
tuple[str, float]: (ラベル名, その確率) を要素に持つリスト
"""
# ## input.shapeに次元と形式を合わせる
data = img.reshape(1, *DATA_IMG_SIZE, 1)
data = tf.convert_to_tensor(data, dtype=tf.float32)
# ## predict
feed = {self.input_key: data}
res = self.infer(**feed)
# ## outputを解釈する
# 簡単なlistにする
res_list = res[self.output_key][0].numpy()
# ラベルと合わせてtupleのリストにする [(ラベル, 確立), (ラベル, 確立), ...]
res_pairs = zip(MyTFModel.LABELS, res_list)
return res_pairs
def predict_label(self, img: np.ndarray) -> str:
"""画像を MyTFModel.LABELS にクラス分類して"ラベル名"か"unkwon"を返す
Args:
img (np.ndarray): shape (240, 320) であるGrayScale画像
Returns:
str: 80%以上の確立を持つラベル名 / "unkwon"
"""
# 推論
res = self.predict(img)
# 確立の降順でソートする
res = sorted(res, key=lambda x: -x[1])
# もっとも確立の高い結果を返す
label, rate = res[0]
if 0.8 < rate:
return label
return "unknown"
5. 結果を平滑化する
推論間違いもあるし、そのフレーム自体は正しくても、30fpsで結果がブレると嫌なので
直近10フレーム(0.33ms)分の結果中の最頻値を使うことにした。
次のようにすると、直近10個分の結果を保持し続けて最頻値を得ることができる。
イケてる書き方![]()
que = []
loop:
que = que[1:10]+[res]
mode = statistics.mode(que)
これはいい記事
このあと
ここから精度を上げるには、とっつきやすさ順に次の事柄が考えられます [FIXME]
- ハイバーパラメータのチューニング
- 推論前の画処理(ノイズや無駄な部分の除去、マスク)
- モデルの再設計
追加したい機能としては [FIXME]
- 画像全体から手を検出して、そこ切り取って推論(オブジェクト検出)
- ユーザの意思があるときにのみの機能(サインが静止したときにトリガー)
- サインではなく時系列を見たジェスチャー
以上
合計500行いかないくらいのコードで、1から10まで機械学習ができました。
Kerasは簡単でいいですね。
難しいのはモデルの設計なので、学習済みモデルがあることにはとても感謝![]()
推論マシンをなにがしかへ組み込む場合も、たいていSavedModel経由でどうとでもなるので、Predictの項だけ考えれば良さそうです。