(本記事中のデモで、Jupyter Labを使って可視化した様子)
Python でデータ分析を始めたい方へ
本記事では、Python でデータ分析を行う際に非常に頼もしいツールである、Jupyter Notebook および Jupyter Lab (以下、まとめて Jupyter と呼びます)について紹介します。
Jupyter はデータサイエンスの世界では既に当たり前のように使われていますが、改めてその良さを実例を交えて整理してみました。
想定条件
以下の条件でデータ分析することを想定して記事を書いています。
- 画像・文章などの非構造データではなく、テーブルデータを分析したい
- 数 TB・数億レコードのデータではなく、数 GB・数万レコードのデータを分析したい
- 定型的な分析というより、探索的に色々と探っていく分析がしたい
本記事で書かないこと
以下の項目は本記事では触れません。もしこの記事を読んで使いたいと思ってくれた方は、他のサイトや書籍等をご参照いただけますと幸いです。
- Jupyter Notebook・Jupyter Lab の環境構築の方法
- たとえばここ
- Jupyter Notebook・Jupyter Lab の基本的な操作方法
- たとえばここ
- pandas で使えるデータ構造やメソッドの使い方
データ分析には時間がかかる
探索的にデータ分析には時間がかかります。これは、無数の試行錯誤が必要になるからだと考えています。従来の開発であれば試行錯誤といえばコードのバグを治すとか、アルゴリズムを修正することが多いと思います。ところがデータ分析となると、それよりもデータ起点での試行錯誤がとても多いです。データを様々な切り口から見たり、データの品質を検証したり、果てはビジネス部門の人からヒアリングしたデータ定義が違うのに気づいてコードを書き直したり、、、
ということで、探索的なデータ分析ではいかに試行錯誤を早く行えるかが重要になってきます。
また、探索的なデータ分析の結果は基本的にレポートにして上司やお客さんに報告することになると思います。分析結果の報告という性格上、レポート(パワーポイントなど)には表やグラフをたくさん貼っていくことになりますが、これが意外と大変で時間がかかる作業です。
なので、できれば表やグラフが素早く準備できることも重要だと考えています。
Jupyter のいいところ 2 つ
時間のかかることが探索的データ分析のツラミなのですが、Jupyter はそのツラミを緩和してくれるツールだと思います。例えば、以下のようなメリットを持っています。
-
試行錯誤の繰り返しが早い
- 1 行(1 セル)ごとに実行結果を得られる
- 一度使用した変数は Jupyter を起動中は保存される
-
実行結果が見やすい
- 表形式のデータが見やすい
- グラフがコードのすぐ下に出力される
箇条書きで書いてしまいましたが、実例をベースに紹介していきたいと思います。
賃貸マンションのデータでのデモ
SUUMO からゲットした東京都中央区の賃貸マンションのデータを使って、Jupyter のいいところをアピールしていきます。私は Jupyter Lab が好きなので、今回はこれを使っていきます。
データ探索の目的は、賃貸マンションの家賃の分布を可視化することとします。
まずは pandas のインポートとデータの読み込みを行います。もし日本語や Windows の文字が原因で文字コードエラーが起きる場合は、encoding='CP932'を引数で渡すとだいたい読み込めます。
# ライブラリの読み込み
import pandas as pd
# データの読み込み
apart = pd.read_csv('apartments_20210410_chuo_jp.csv')
データを読み込んだら、head()メソッドでデータを表示して確認します。**このhead()メソッドがとにかく優秀で、表形式のデータがとても簡単に、かつ見やすく確認できちゃいます。**報告資料への記載も、この表をスクショして使うことも個人的にはありだと思います。(もちろん報告する相手にもよります。外部のお客さん相手の場合はおとなしく CSV で出力してパワーポイントの表を使ったほうが良いと思います。)
# データを表示
apart.head()
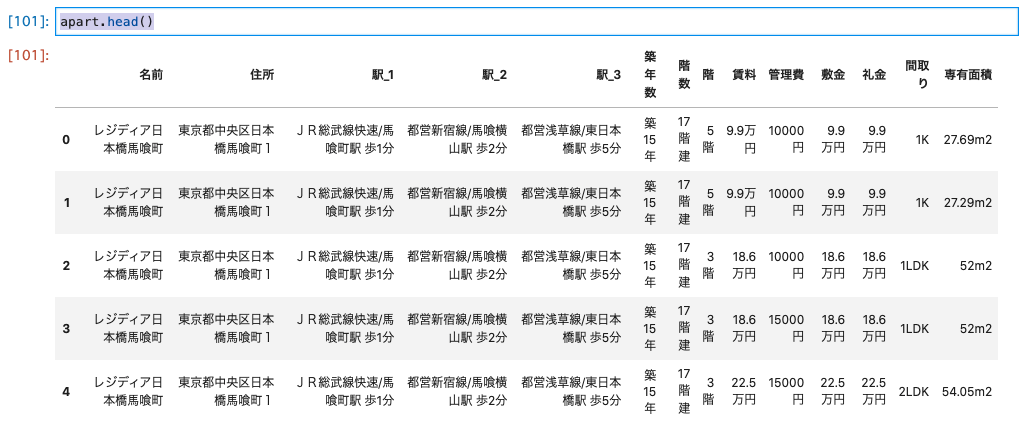
デフォルトだと 5 行出力されますが、数字を渡すことで出力行を変えられます。私の使い方では、データの列や値をざっくり見たい場合は 5 行(デフォルト)、後で確認するために表示しておく場合は 1 行、データ自体を確認したい場合は 100 行程度見たりしています。
今回の目的は賃料を可視化することです。賃料は「〜万円」のような形で入っているので、これを int 型の数値に直していきます。
ここでは、ラムダ式と map 関数を組み合わせて、賃料の列を一括で直す関数を作ります。このように、その場その場で処理を考えて実行して、を繰り返しできることも Jupyter の良いところです。(これは Jupyter というか対話環境の良いところですが、、)
# 円を消す
# 万があれば消して10000をかける
apart['賃料_円'] = list(map(lambda x: x.replace('円', ''), apart.賃料))
apart['賃料_円'] = list(map(lambda x: float(x.replace('万', ''))*10000 if '万' in x else x, apart.賃料_円))
apart['賃料_円'] = apart['賃料_円'].astype('int')
pandas には apply という関数があり、map と同様の処理ができますが、実行速度の点から map を使うことをおすすめします。ただし map では dataframe の 1 列分しか 1 度に処理できないので、1 行の中で複数の列の値を同時に処理する場合は apply を使っています。(参考)
ところで、賃貸マンションを借りるときはだいたい 2 年契約で借りますが、実際にかかるお金には賃料の他にも管理費や敷金があります。そこで、賃料より厳密にかかる費用を算出するため、2 年間でかかるお金を計算してみます。具体的には、賃料 2 年分(24 ヶ月分)に加えて、管理費 2 年分(24 ヶ月分)、敷金を足した金額を算出します。
# 円を消す
# 万があれば消して10000をかける
apart['管理費_円'] = list(map(lambda x: x.replace('円', ''), apart.管理費))
apart['管理費_円'] = list(map(lambda x: float(x.replace('万', ''))*10000 if '万' in x else x, apart.管理費_円))
apart['管理費_円'] = apart['管理費_円'].astype('int')
では先ほどと同様に、管理費を円に変換します。
と思いましたが、同じ関数を適用したらエラーが発生しました。どうやらハイフン「-」があったため数値型に変換できなかったようです。
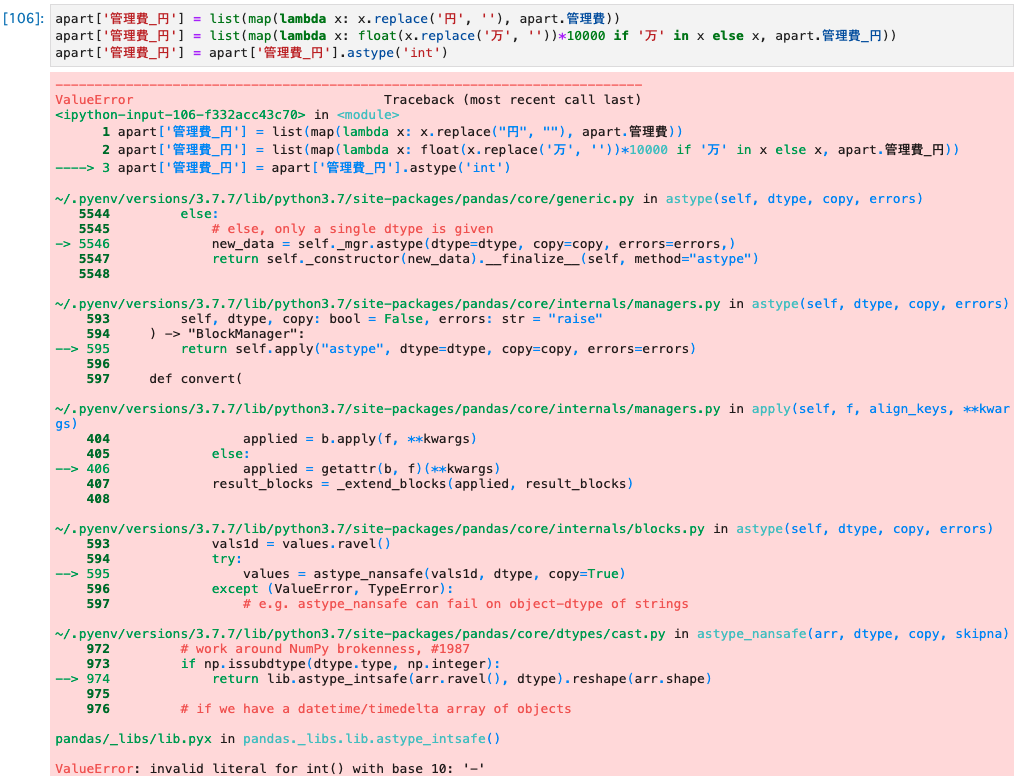
問題のあるデータを確認すると、管理費がゼロであることを示すためにハイフンが入っていることが分かります。

エラーが出ても Jupyter 自体は動いており、ここまで計算した変数やライブラリはそのままなので、このまま再度リトライすることができます。これも Jupyter の強みです。
ハイフンに対応した関数を作っていきますが、ラムダ式で書くにはちょっと複雑になりそうなので、普通のメソッドとして書いてみます。
def extract_jpy(x):
"""
- 円を消す
- ハイフンを0に置換する
- 万があれば消して10000をかける
- int型に変換する
"""
x = x.replace('円', '')
x = x.replace('-', '0')
if '万' in x:
x = x.replace('万', '')
x = float(x)*10000
return int(x)
apart['管理費_円'] = list(map(extract_jpy, apart.管理費))
管理費もうまく数値に変換できたようです。
つづいて敷金も同様に処理していきます。
apart['礼金_円'] = list(map(extract_jpy, apart.礼金))
ここでは管理費と同じ処理を行うので、セルをコピーして使いまわしています。Jupyter には便利なショートカットキーがあり、それらを組み合わせることで素早く操作ができます。特に、c:セルのコピー、x:セルのカット、v:セルのペースト、z:セル操作のやり直し、a:新規セルを上に追加、b:新規セルを下に追加は非常によく使います。また、ESC:セル操作モードへの移行、Enter:コード入力モードへの移行も使えば、作業が爆速になるのでおすすめです。
ここまでで作成した 3 つの列がうまく処理できているかを簡単に確認します。
apart.head()
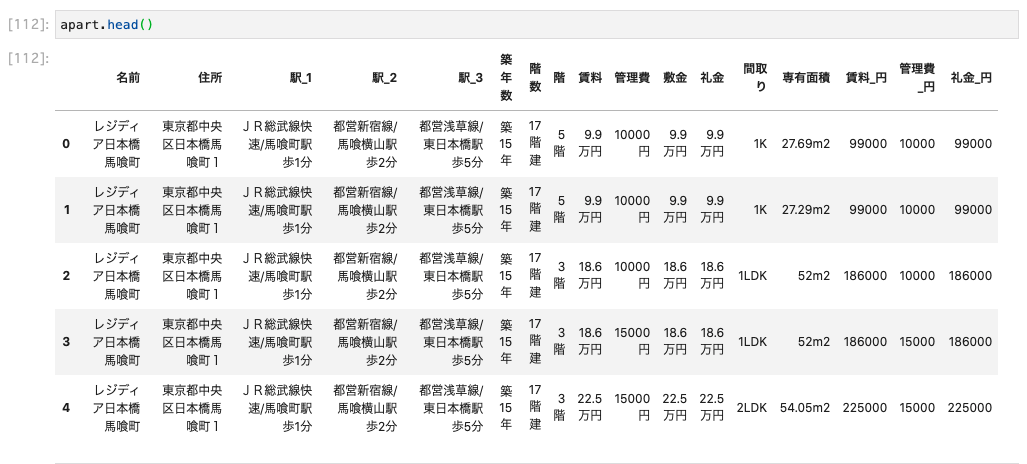
「賃料_円」「管理費_円」「礼金_円」それぞれがうまく数値で抽出できてそうですね。
それでは、2 年分の賃貸料を算出します。pandas の apply 関数を使って行ごとに計算していきます。
apart['賃貸料2年分'] = apart.apply(lambda x: (x.賃料_円 + x.管理費_円)*24 + x.礼金_円, axis=1)
apart.head()
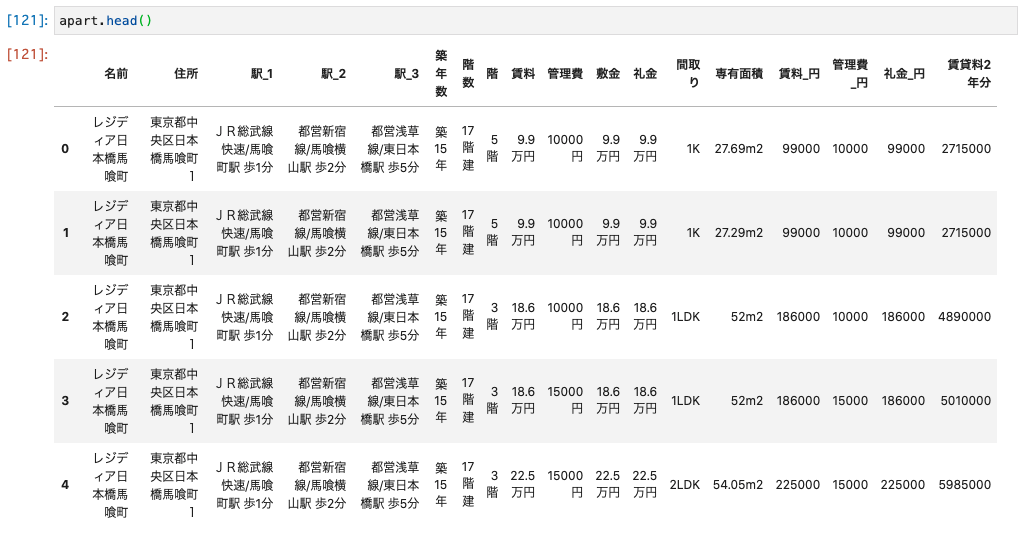
うまく 2 年でかかる賃貸料を計算できているようです。これで可視化すべきデータの準備は整いました。
ここからは可視化を行っていきます。今回は plotly を使います。plotly は使いやすさと見やすさの兼ね合いがよいので、筆者のお気に入りです。特に見た目は、そのままスクショしてパワポに貼っても問題ないレベルです。(seaborn/matplotlib と違って、デフォルトで日本語が文字化けしないのもありがたいです。)
# ライブラリの読み込み
import plotly.express as px
fig = px.histogram(apart, x="賃貸料2年分")
fig.show()
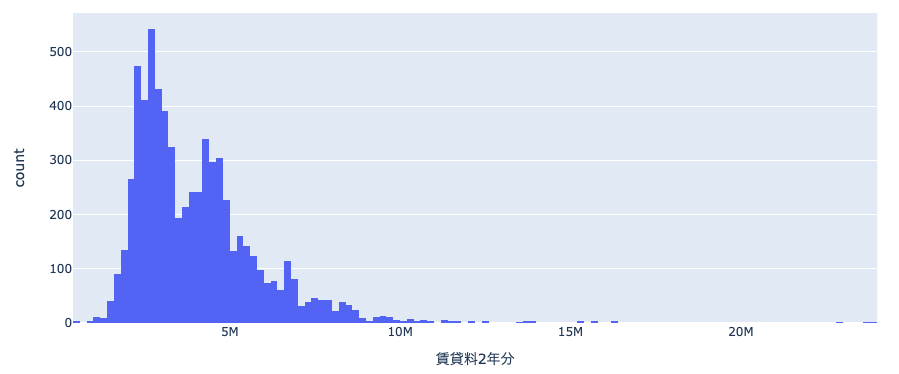
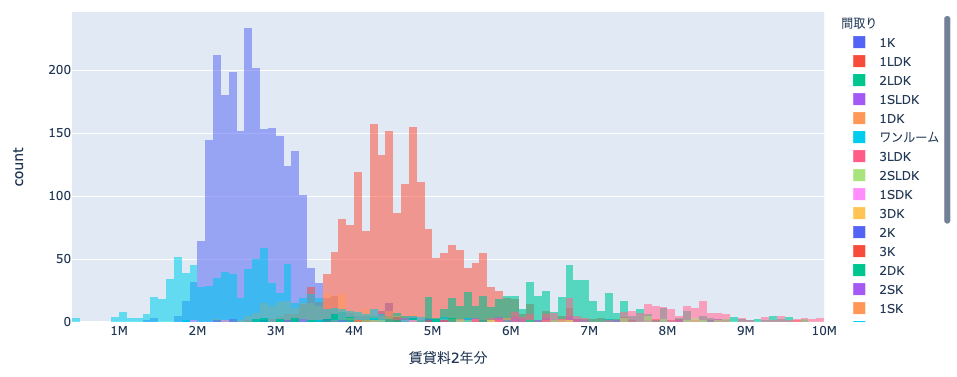
ヒストグラムを表示してみると、200k(=20 万円)から 23M(2300 万円)まで幅広く分布しているようです。20M のマンションはとても住めそうにないので、とりあえず大半のデータが含まれる 10M までをしきい値としてフィルタしてみます。
fig = px.histogram(apart.query('賃貸料2年分 <= 10000000'), x="2年賃貸料")
fig.show()
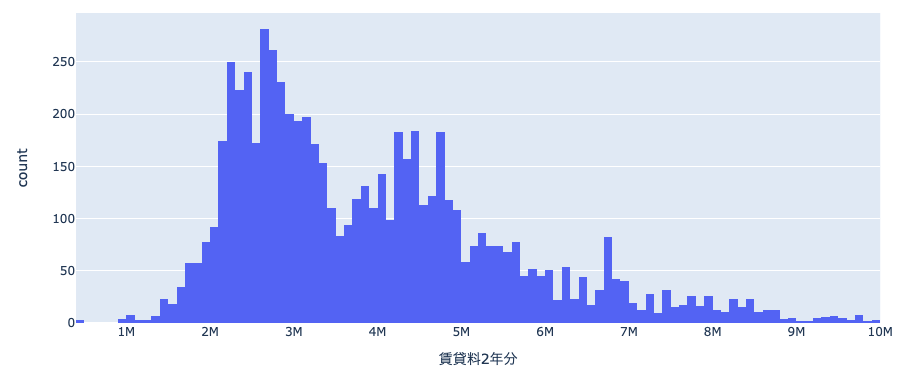
分布を眺めていると、山がいくつかあるのが分かります。部屋の間取りによって分布が異なるかもしれないので、試しに間取りで色分けして可視化してみます。
fig = px.histogram(apart.query('賃貸料2年分 <= 10000000'), x="2年賃貸料", color='間取り',barmode='overlay')
fig.show()
間取りの違いによって分布が異なるのがきれいに分かりました。ここから 1K と 1LDK の分布を比較してみようと思います。価格帯が 7M あたりまででほとんどのデータが入っているので、7M でフィルタします。
fig = px.histogram(apart.query('賃貸料2年分 <= 6000000 and (間取り == "1K" or 間取り == "1LDK")'), x="2年賃貸料", color='間取り',barmode='overlay')
fig.show()
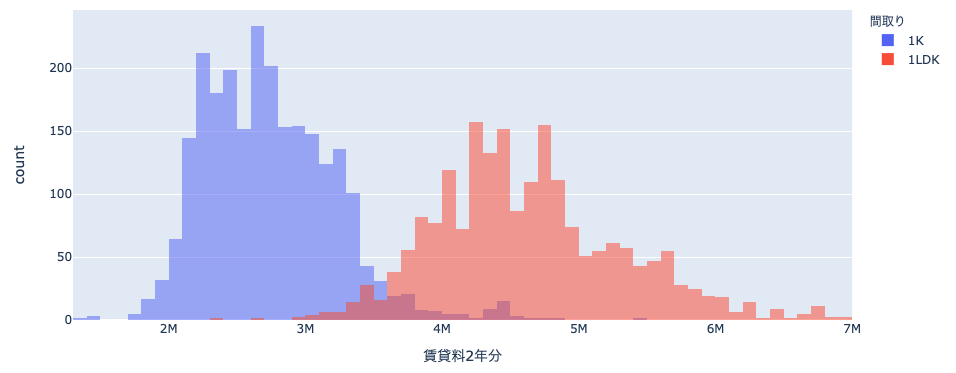
きれいに 2 つの山に分かれていることが可視化できました。このデモでの分析はここまでとしますが、価格の分布は部屋の間取り以外に何が寄与しているのか、3.5M あたりで分布が重なっているが、間取り以外に何が異なるのか、逆に同じところはどこか、などなど色々と探索しがいがありそうです。
こんな風に、初見のデータで、どんなデータが、どんなデータ型で、どんな形式で、どんな分布で入ってるかわからんという場合や、走りながら(データを見ながら)やるべきことが湧いてくるタイプの作業には Jupyter が効率的ではないかと思います。
Appendix:Jupyter の課題とその対策
最後に、Jupyter を使う上で気になることとその対策を箇条書きで記載します。技術的負債の増加は Jupyter というか機械学習を扱うシステム全体での問題でもあり、まだまだ工夫の余地はあるかと思います。
- 見た目
- JupyterLab の場合はデフォルトでダークテーマが選べる
- 補完
- 補完用のライブラリを使う(jupyterlab-lsp とか)
- 技術的負債の増加