はじめに
!!!!! モデルおよびコードの利用は自己責任でお願いします !!!!!
第2回となる本稿では、前回構築した Bonsai-8B の比較対象のローカル LLM 環境を構築します。
当初は構築済みの Ollama の予定でしたが、絶妙のタイミングで Foundry Local が GAされましたのでこちらを使ったローカル LLM 実行環境のセットアップについて整理します。
前提条件
今回の検証の前提条件は①とあまり変わりませんが、一応以下のような前提条件を設定しました。
- クラウド生成 AI サービスは利用不可
- 開発端末はローカル PC
- エディタは VSCode
- LLM ランタイムは Foundry Local
- モデルは Qwen2.5-corder:1.5b と Qwen2.5-corder:7b
セットアップ手順
前提環境
Foundry Local のセットアップに特段の前提環境はありません、この簡便さが Foundry Local の大きなメリットだと思います。
① Foundry Local インストール
まずは Foundry Local 本体をインストールします、特に詰まるポイントはなく winget が使える Windows 環境であれば非常にあっさり終わります。
Foundry Local は内部的に必要なランタイムや依存関係をまとめて面倒を見てくれるようで、Ollama などと比べても「事前準備をほとんど意識しなくてよい」のが特徴だと思います。
以下では、winget を使ってインストールし、CLI が正しく導入されていることを確認します。
# インストール
winget install Microsoft.FoundryLocal
# 確認
foundry --version
② モデルインストール & 起動
次にFoundry Local 上で利用するモデルをインストールします、ここが実質的に Foundry Local を触り始める最初のポイント です。
まず foundry model ls を実行するとインストール可能なモデルの一覧と、その Alias が表示され、ここで表示される Alias をそのまま使って foundry model run <Alias> を実行する、という流れになります。
内部的には、
-
model runは「インストール」と「起動」を同時に行う - 一度取得したモデルはキャッシュされ、次回以降は起動のみになる
という動作となっており、このあたりは Ollama とかなり近い体験です。
なおモデル起動中は Foundry Local がローカル LLM サーバーとして待ち受け状態になるため、この時点で API 経由の利用が可能になります。
# インストール可能なモデルの取得
foundry model ls
# モデルのインストール & 起動
foundry model run <Alias>
# 確認
foundry cache list
③ ポート番号固定化
Foundry Local は自動的に HTTP サービス を起動しますが、デフォルトのままだと起動のたびにポート番号が変わってしまいます。
ポート番号が変わってしまうと Continue など外部ツールから接続するたびにコンフィグを書き換える必要があり面倒ですので、ポート番号を明示的に固定化します。
以下のコマンドでポート番号を設定し、意図した値で待ち受けていることを確認します。
# ポート番号を設定
foundry service set --port 10003
# 確認
foundry service status
④ Continue に追加
最後に、Continue に設定を追加し Foundry Local を使えるようにします。
- アクティビティバー の Continue を開き [Local Config] > [Local Configの右の歯車] で config.yaml を開く
- config.yaml のモデルに Foundry Local を追加
name: Local Config
version: 1.0.0
schema: v1
models:
- name: qwen2.5-coder:1.5b (foundry)
provider: openai
model: qwen2.5-coder-1.5b-instruct-cuda-gpu:4
apiBase: http://127.0.0.1:10003/v1
apiKey: not-needed
useResponsesApi: false
roles:
- chat
- edit
- apply
requestOptions:
timeout: 180000
- name: qwen2.5-coder:7b (foundry)
provider: openai
model: qwen2.5-coder-7b-instruct-cuda-gpu:4
apiBase: http://127.0.0.1:10003/v1
apiKey: not-needed
useResponsesApi: false
roles:
- chat
- edit
- apply
requestOptions:
timeout: 180000
動作確認
Continue チャット
Continue のチャット画面からプロンプトを入力し、Foundry Local が応答することを確認しました。(Qwen2.5-corder:1.5b は自分のモデル名を素直に返してくれなかったのでわかりにくいですが)
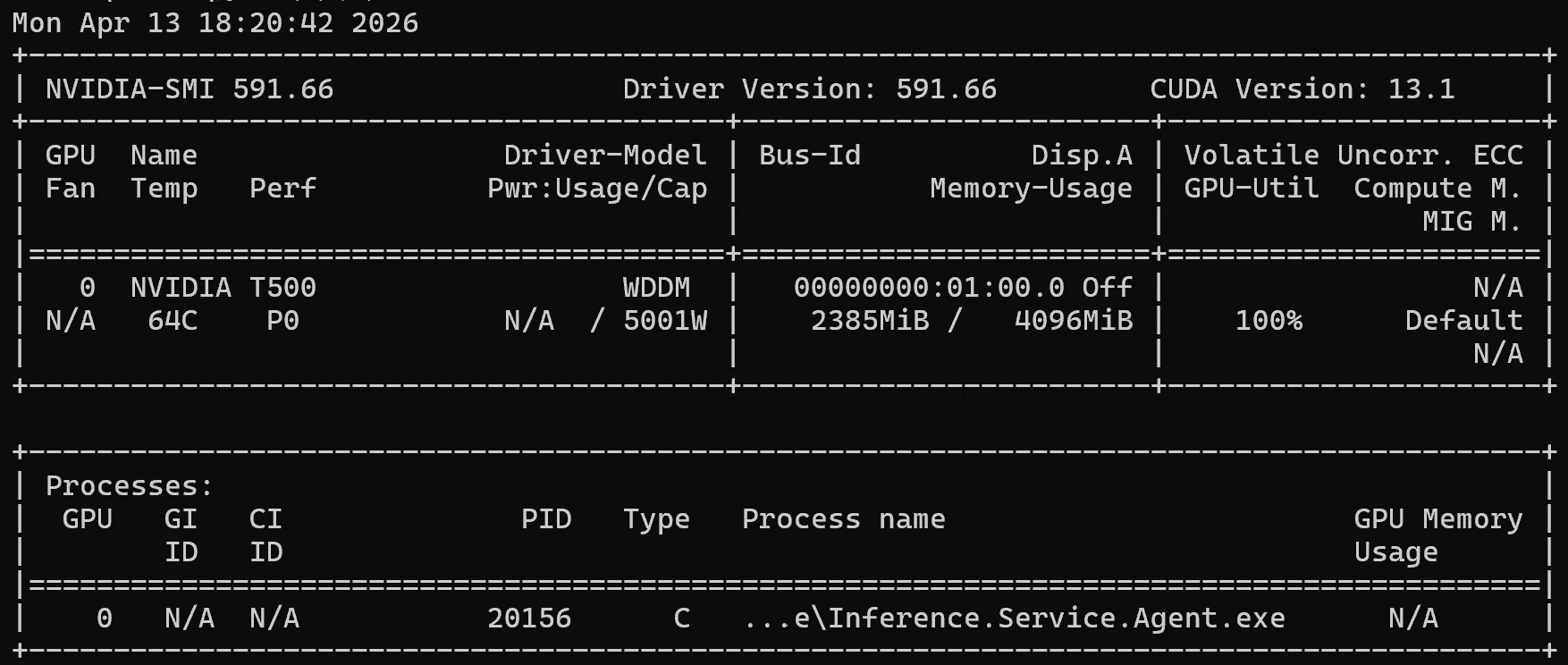
GPU 負荷
推論実行中に GPU 使用率が上がることも確認でき、GPU を使った推論が行われていることが分かります。
その他の操作
参考に Foundry Local のその他の操作のコマンドを記載しておきます。
■ モデルのアンロード
# チャットの終了
/exit
# 起動中のモデルの取得
foundry service ps
# モデルのアンロード
foundry model unload <model-id>
■ モデル削除
# キャッシュの表示
foundry cache list
# モデルキャッシュの削除
foundry cache remove <model-id>
■ サービス起動・停止
# サービス起動
foundry service start
# サービス停止
foundry service stop
補足
実はこちらも VSCode のチャットから Foundry Local を使う形で進めていたのですが、Foundry Local にインストール済みのモデルを VSCode に認識させることができず頓挫しています。
同じような事象がいくつか上がっているようですので、まだ解消されていない不具合を踏んでいるのかもしれません。
おわりに
本稿では、
- Foundry Local を使ったローカル LLM 環境のセットアップ
- Qwen2.5-coder を例にしたモデルのインストールと起動
- VSCode(Continue)からの動作確認
といった一連の流れを整理しました。
Foundry Local は、
- winget だけで導入できる手軽さ
- OpenAI 互換 API としてそのまま扱える構成
- Continue など既存ツールと素直に組み合わせられる点
と言った点が非常に扱いやすく、「とりあえずローカル LLM を触ってみたい」という用途にはかなり良い選択肢だと感じました。
さて次回は Bonsai-8B の実力を測るべく、他のモデルとの比較を軸に検証を行っていきたいと思います。
本稿を読んでいただきありがとうございました!