はじめに
!!!!! モデルおよびコードの利用は自己責任でお願いします !!!!!
クラウドの生成 AI を使いたいが、セキュリティポリシーやコストの都合で使えない──そんな環境に置かれている方も多いと思います。
近頃は、
- 外部の生成 AI サービスは原則利用不可
- それでも生成 AI サービスを使わざるを得ない状況が近い
といったお話を伺うことも増えてきました。
そこで今回は、ローカル LLM を使って VSCode から生成 AI コーディング支援を使える環境を構築した際の記録を整理してみます。
第1回となる本稿では、今話題の Bonsai-8B をローカル環境にセットアップし、VSCode(Continue)から動作確認するところまでを扱います。
同じような制約下で悩んでいる方のヒントになれば幸いです。
修正履歴
2026/5/5:Docerfile と コンテナー起動コマンドを CPU 対応に修正
前提条件
今回の検証は、以下のような前提で行いました。
- クラウド生成 AI サービスは利用不可
- 開発端末はローカル PC
- エディタは VSCode
- モデルは Bonsai-8B
細かい OS や GPU の差異はありますが、「ローカルで LLM を動かし、VSCode から叩く」という点が本質です。
セットアップ手順
前提環境
本稿では、コンテナーで GPU が認識できているところまでを前提環境としています。
ざっと手順を記載しますので、参考にご準備ください。
- Windows に最新の GPU ドライバーをインストール
- WSL をインストール
- Docker をインストール
- NVIDIA Container Toolkit をインストール
- コンテナーから GPU が認識されることを確認
① カスタム llama 同梱のコンテナーイメージビルド
Bonsai-8B は本稿執筆時点でまだ一般的な LLM ランタイムでは動作しないため、Bonsai 用にビルドされたカスタム llama-server 同梱のコンテナーイメージを作成します。
ポイントは以下の通りです。
- ビルドステージで Bonsai-demo を clone
-
setup.shを実行して CUDA 対応の llama-server をビルド - ランタイムイメージには必要最小限の成果物のみをコピー
Dockerfile の全体像は以下の通りです。
# =========================
# build stage
# =========================
FROM nvidia/cuda:12.8.1-cudnn-devel-ubuntu24.04 AS build
ARG BONSAI_REPO=https://github.com/PrismML-Eng/Bonsai-demo.git
ARG BONSAI_REF=main
RUN apt-get update && apt-get install -y --no-install-recommends \
git cmake build-essential ca-certificates \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /src
RUN git clone --depth 1 --branch "${BONSAI_REF}" "${BONSAI_REPO}" "Bonsai-demo"
WORKDIR /src/Bonsai-demo
# CUDA版ビルド(既存)
RUN chmod +x setup.sh && ./setup.sh
# CPU版バイナリを固定URLで取得
RUN mkdir -p bin/cpu && \
curl -L --fail \
"https://github.com/PrismML-Eng/llama.cpp/releases/download/prism-b8846-d104cf1/llama-prism-b8846-d104cf1-bin-ubuntu-x64.tar.gz" \
-o /tmp/llama-cpu.tar.gz && \
tar -xzf /tmp/llama-cpu.tar.gz -C bin/cpu --strip-components=1 && \
rm -f /tmp/llama-cpu.tar.gz
# =========================
# runtime stage
# =========================
FROM nvidia/cuda:12.8.1-cudnn-runtime-ubuntu24.04
RUN apt-get update && apt-get install -y --no-install-recommends \
libgomp1 ca-certificates \
&& rm -rf /var/lib/apt/lists/*
RUN useradd -m -u 10001 -s /usr/sbin/nologin appuser
# GPU / CPU 両方のバイナリと共有ライブラリを配置
COPY --from=build /src/Bonsai-demo/bin/cuda/ /opt/bonsai/cuda/
COPY --from=build /src/Bonsai-demo/bin/cpu/ /opt/bonsai/cpu/
# 起動スクリプト
RUN printf '%s\n' \
'#!/bin/sh' \
'set -eu' \
'' \
'if [ "${USE_GPU:-0}" = "1" ]; then' \
' echo "[INFO] Starting GPU version"' \
' export LD_LIBRARY_PATH="/opt/bonsai/cuda:${LD_LIBRARY_PATH:-}"' \
' exec /opt/bonsai/cuda/llama-server \' \
' -m "${MODEL_PATH:-/models/Bonsai-8B.gguf}" \' \
' --host 0.0.0.0 \' \
' --port "${PORT:-11435}" \' \
' -ngl "${GPU_LAYERS:-99}"' \
'else' \
' echo "[INFO] Starting CPU version"' \
' export LD_LIBRARY_PATH="/opt/bonsai/cpu:${LD_LIBRARY_PATH:-}"' \
' exec /opt/bonsai/cpu/llama-server \' \
' -m "${MODEL_PATH:-/models/Bonsai-8B.gguf}" \' \
' --host 0.0.0.0 \' \
' --port "${PORT:-11435}" \' \
' -ngl 0' \
'fi' \
> /entrypoint.sh
RUN chmod +x /entrypoint.sh
EXPOSE 10000
USER appuser
ENTRYPOINT ["/entrypoint.sh"]
Docker の CUDA イメージ一覧は以下を参照しています。
この時点で、
- Bonsai 専用にビルドされた llama-server
- OpenAI 互換 API を提供するサーバー
をコンテナーとして起動できる下地が整います。
② Bonsai-8B モデルのセットアップ
続いて、Bonsai-8B のモデルファイル(GGUF)を準備します。
# ソースをクローンしてセットアップ
git clone https://github.com/PrismML-Eng/Bonsai-demo.git
cd Bonsai-demo/
./setup.sh
# モデルファイルをマウント元のディレクトリにコピー
sudo cp ./models/gguf/8B/Bonsai-8B.gguf /mnt/models
このモデルファイルは、
- コンテナー起動時にボリュームマウント
-
MODEL_PATH環境変数で指定
という形で llama-server から参照されます。
③ コンテナー起動
モデルとイメージの準備ができたら、GPU を有効にした状態でコンテナーを起動します。
ポート番号は環境に合わせて変更してください。
# GPU
docker run -d --rm \
--name bonsai_gpu_run \
--gpus all \
-p 11435:11435 \
-e USE_GPU=1 \
-e PORT=11435 \
-e MODEL_PATH=/models/Bonsai-8B.gguf \
-v /mnt/models:/models \
bonsai-llama:latest
# CPU
docker run -d --rm \
--name bonsai_cpu_run \
-p 11435:11435 \
-e USE_GPU=0 \
-e PORT=11435 \
-e MODEL_PATH=/models/Bonsai-8B.gguf \
-v /mnt/models:/models \
bonsai-llama:latest
起動後、以下の API を使って動作確認を行います。
# ヘルスチェック
curl http://localhost:11435/health
# OpenAI 互換 Chat Completions API
curl http://localhost:11435/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Bonsai-8B",
"stream": false,
"messages": [
{"role": "user", "content": "こんにちは。自己紹介してください。"}
]
}'
この時点で、
- llama-server が起動していること
- OpenAI 互換 API として応答すること
が確認できました。
④ Continue のインストールと設定
最後に、VSCode からこのローカル LLM を使えるように設定します。
- VSCode に Continue 拡張機能をインストール
- Continue の Local Config(
config.yaml)を開く - Bonsai-8B をモデルとして追加
設定例は以下の通りです。
name: Local Config
version: 1.0.0
schema: v1
models:
- name: Bonsai-8B (docker)
provider: openai
model: Bonsai-8B.gguf
apiBase: http://localhost:11435/v1
apiKey: not-needed
roles:
- chat
- edit
- apply
requestOptions:
timeout: 180000
ここでは、Continue から見ると 「OpenAI 互換 API を提供するローカルモデル」として見える構成にしています。
動作確認
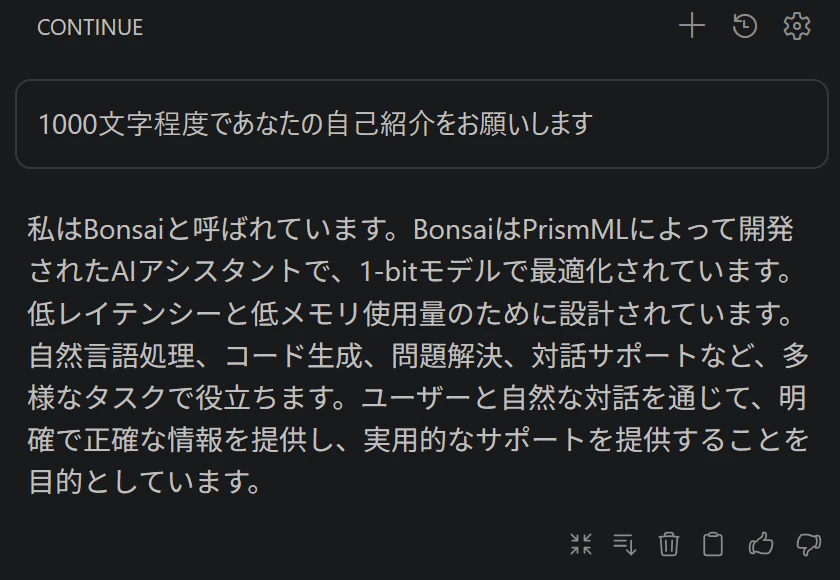
Continue チャット
Continue のチャット画面からプロンプトを入力し、ローカルの Bonsai-8B が応答することを確認しました。
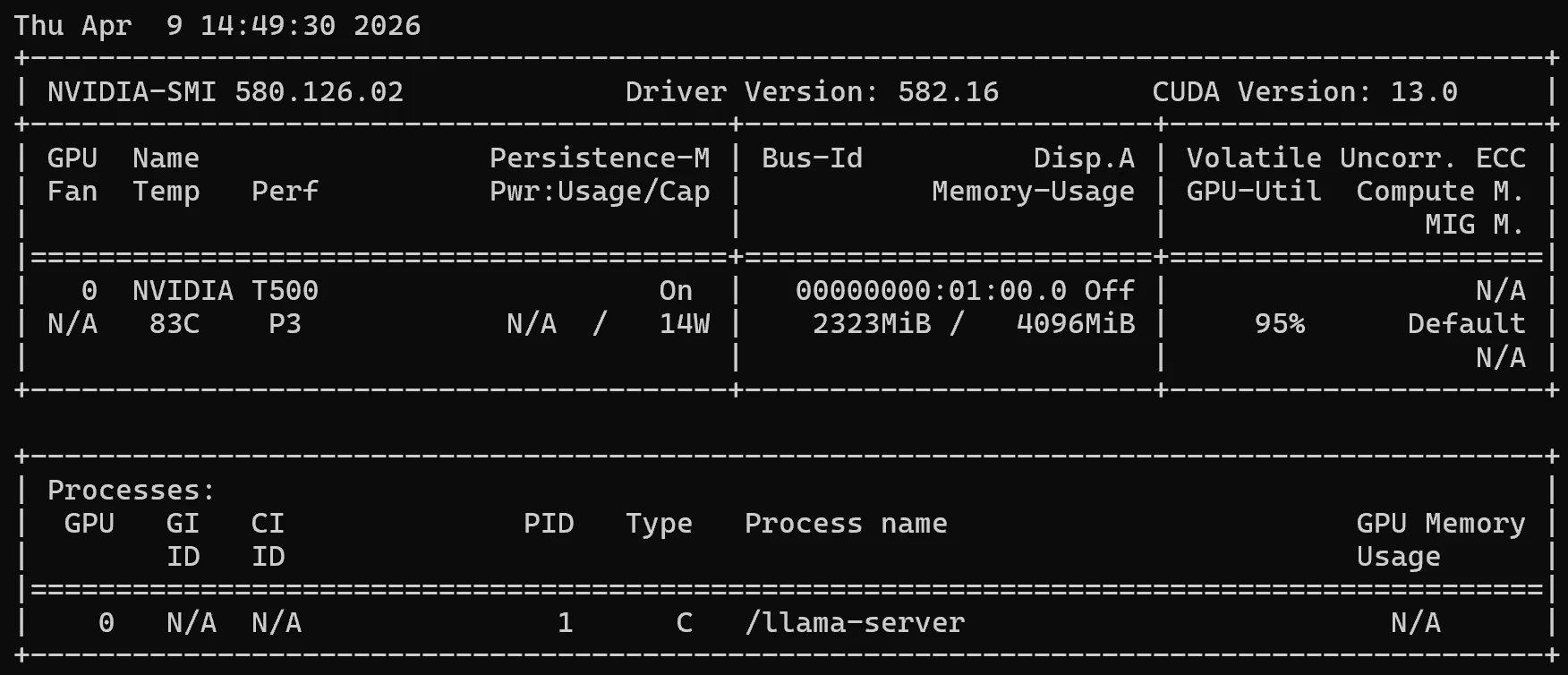
GPU 負荷
推論実行中に GPU 使用率が上がることも確認でき、GPU を使った推論が行われていることが分かります。
補足
本来は VSCode のチャットからローカル LLM を自然に呼び出したかったのですが、
- モデルは認識される
- しかし選択肢として表示されない
という挙動に遭遇しました。
Bonsai-8B は登場したばかりで、かつカスタム llama-server を使う構成であるため、現時点では不可避の制約の可能性がありそうです。
おわりに
本稿では、
- Bonsai-8B を使った Local LLM 環境のセットアップ
- VSCode(Continue)からの動作確認
の流れを、実際のセットアップ内容に基づいて整理しました。
今回は Bonsai-8B を使って、ローカル LLM を VSCode(Continue)から利用できるところまでを確認しました。
次回は、Bonsai-8B 以外のモデルを同様の構成で動かし、その実力はパフォーマンスを比較してみる予定です。
本稿を読んでいただきありがとうございました!