その2からの続き
前回その2で実際に動くチャットアプリを作成しました。ただこのままだと、普通のChatGPTやGemini等を使えば良いじゃんという話になってしまうので、もう少し手を加えていきたいなと思います。
※その1
https://qiita.com/kousasak/items/8604a6b082514f3299fe
※その2
https://qiita.com/kousasak/items/72c52edee509486e1707
1.前回作ったチャットアプリに回答させるLLMを選択できるようにする
前回は回答させるLLMはCohereのみでしたが、今回は他にも選べるようにしようと思います。
また併せて、おおよその課金の目安になるようなものも追加しようと思います。
2.変更点
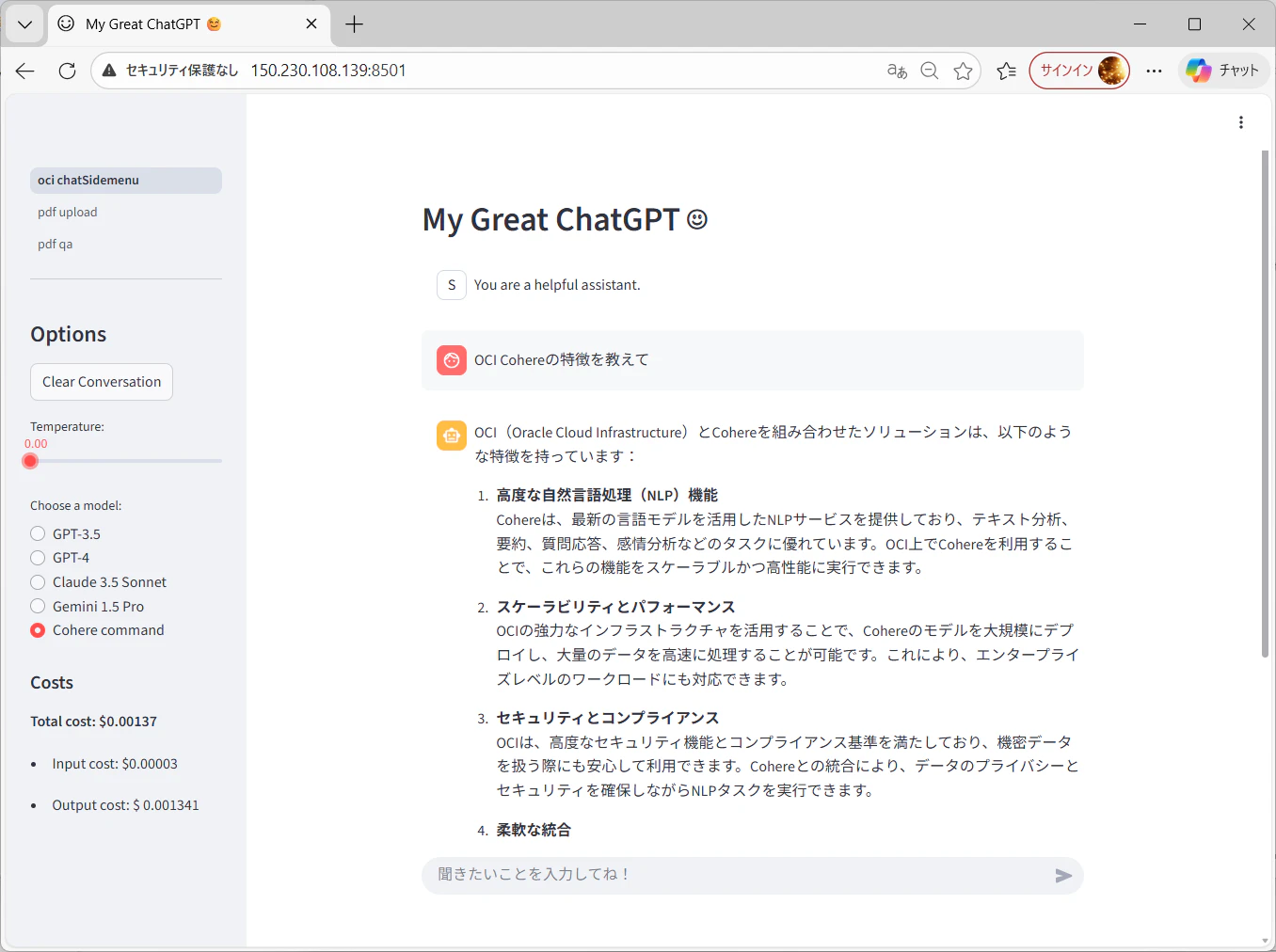
前回のチャット画面はそのままに、streamlitで画面横にLLMの選択とコストの表示画面周りを作っていきます。
画面サンプル
3.ソース
各LLMのAPIKEYやCOMPARTMENT_IDなどの変数は先にOS側で変数にセットしていますので、各々の環境で適宜変更してください。
#!/usr/bin/python3
import tiktoken
import streamlit as st
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# models
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
from langchain_google_genai import ChatGoogleGenerativeAI
import os
import sys
import io
import getpass
# OCIの設定
from dotenv import load_dotenv
import oci
import json
from oci.config import from_file
from oci.generative_ai import GenerativeAiClient
from oci.generative_ai_inference import GenerativeAiInferenceClient
from oci.generative_ai_inference.models import (
OnDemandServingMode,
GenerateTextDetails,
CohereLlmInferenceRequest,
CohereMessage,
CohereChatRequest,
ChatDetails,
CohereUserMessage,
CohereChatBotMessage,
CohereSystemMessage,
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
load_dotenv()
config = from_file()
GEN_AI_ENDPOINT = os.getenv('GEN_AI_ENDPOINT')
GEN_AI_INFERENCE_ENDPOINT = os.getenv('GEN_AI_INFERENCE_ENDPOINT')
COMPARTMENT_ID = os.getenv('C')
model_id = 'cohere.command-a-03-2025'
generative_ai_inference_client = GenerativeAiInferenceClient(config=config, retry_strategy=oci.retry.NoneRetryStrategy(), timeout=(10,240))
MODEL_PRICES = {
"input": {
"gpt-3.5-turbo": 0.5 / 1_000_000,
"gpt-4o": 5 / 1_000_000,
"claude-3.5-sonnet-220240620": 3 / 1_000_000,
"gemini-1.5-pro-latest": 3.5 / 1_000_000,
"cohere.command-a-03-2025": 1.6 / 1_000_000
},
"output": {
"gpt-3.5-turbo": 1.5 / 1_000_000,
"gpt-4o": 15 / 1_000_000,
"claude-3.5-sonnet-220240620": 15 / 1_000_000,
"gemini-1.5-pro-latest": 10.5 / 1_000_000,
"cohere.command-a-03-2025": 1.6 / 1_000_000
}
}
# Cohereの処理
def _to_cohere_role(role: str) -> str:
# st.session_state.message_history の role: "system" / "user" / "ai"
# OCI CohereMessage.role の allowed values: CHATBOT / USER / SYSTEM など :contentReference[oaicite:2]{index=2}
if role == "system":
return "SYSTEM"
if role == "user":
return "USER"
return "CHATBOT"
def _to_cohere_history_item(role: str, text: str):
if role == "system":
return CohereSystemMessage(message=text)
if role == "user":
return CohereUserMessage(message=text)
# あなたの履歴では assistant が "ai"
return CohereChatBotMessage(message=text)
def oci_cohere_chat_once(user_input: str, temperature: float = 0.0, max_tokens: int = 1024) -> str:
"""
OCI Generative AI Inference (Cohere) を chat API で1回呼んで、text を返す。
"""
# これまでの会話履歴を CohereMessage に変換
history = []
for r, m in st.session_state.get("message_history", []):
history.append(_to_cohere_history_item(r,m))
chat_req = CohereChatRequest(
message=user_input, # 今回のユーザー入力はここ
chat_history=history, # それ以前の履歴
temperature=temperature,
max_tokens=max_tokens,
)
chat_details = ChatDetails(
compartment_id=COMPARTMENT_ID,
serving_mode=OnDemandServingMode(model_id=model_id),
chat_request=chat_req,
)
resp = generative_ai_inference_client.chat(chat_details)
return resp.data.chat_response.text
def init_page():
st.set_page_config(
page_title='My Great ChatGPT ?',
page_icon='?'
)
st.header("My Great ChatGPT ?")
st.sidebar.title("Options")
def init_messages():
clear_button = st.sidebar.button("Clear Conversation", key="clear")
# clear_button が押された場合や message_histor がまだ存在しない場合に初期化
if clear_button or "message_history" not in st.session_state:
st.session_state.message_history = [
("system", "You are a helpful assistant.")
]
def select_model():
st.session_state.use_oci_cohere = False
# スライダーを追加し、temperatureを0から2までの範囲で選択可能にする
# 初期値は0.0、刻み幅は0.01とする
temperature = st.sidebar.slider(
"Temperature:", min_value=0.0, max_value=2.0, value=0.0, step=0.01)
st.session_state.temperature = temperature
models = ("GPT-3.5", "GPT-4", "Claude 3.5 Sonnet", "Gemini 1.5 Pro","Cohere command")
model = st.sidebar.radio("Choose a model:", models)
if model == "GPT-3.5":
st.session_state.model_name = "gpt-3.5-turbo"
return ChatOpenAI(
temperature=temperature,
model_name=st.session_state.model_name
)
elif model == "GPT-4":
st.session_state.model_name = "gpt-4o"
return ChatOpenAI(
temperature=temperature,
model_name=st.session_state.model_name
)
elif model == "Claude 3.5 Sonnet":
st.session_state.model_name = "claude-3.5-sonnet-20240620"
return ChatAnthropic(
temperature=temperature,
model_name=st.session_state.model_name
)
elif model == "Gemini 1.5 Pro":
st.session_state.model_name = "gemini-1.5-pro-latest"
return ChatGoogleGenerativeAI(
temperature=temperature,
model=st.session_state.model_name
)
elif model == "Cohere command":
st.session_state.model_name = model_id
st.session_state.use_oci_cohere = True
return None
class OciCohereChain:
def __init__(self, temperature: float):
self.temperature = temperature
def stream(self, inputs: dict):
# st.write_stream が generator を期待するので yield する
text = oci_cohere_chat_once(
user_input=inputs["user_input"],
temperature=self.temperature,
)
# 疑似ストリーミング(UI表示用)
chunk_size = 20
for i in range(0, len(text), chunk_size):
yield text[i:i+chunk_size]
def init_chain():
# ここで select_model を呼ぶが、Cohere の場合は None が返る
llm = select_model()
# select_model() 内で立てたフラグを見る
if st.session_state.get("use_oci_cohere", False):
# sidebar の temperature 値を持ってくる必要があるので、
# select_model() 内で temperature を session_state に保存しておくのが楽です。
# 例: st.session_state.temperature = temperature
return OciCohereChain(temperature=st.session_state.temperature)
st.session_state.llm = llm
prompt = ChatPromptTemplate.from_messages([
*st.session_state.message_history,
("user", "{user_input}") # ここにあとでユーザの入力が入る
])
output_parser = StrOutputParser()
return prompt | st.session_state.llm | output_parser
def get_message_counts(text):
if "gemini" in st.session_state.model_name:
return st.session_state.ollm.get_num_tokens(text)
else:
# Claude 3 はトークナイザーを公開していないので、tiktokenを使ってトークン数をカウント
# これは正確なトークン数ではないが、大体のトークン数をカウントすることができる
if "gpt" in st.session_state.model_name:
encoding = tiktoken.encoding_for_model(st.session_state.model_name)
elif "Cohere" in st.session_state.model_name:
encoding = tiktoken.encoding_for_model(st.session_state.model_name)
else:
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo") # 仮のものを利用
return len(encoding.encode(text))
def calc_and_display_costs():
output_count = 0
input_count = 0
for role, message in st.session_state.message_history:
# tiktoken でトークン数をカウント
token_count = get_message_counts(message)
if role == "ai":
output_count += token_count
else:
input_count += token_count
# 初期状態で System Message のみが履歴に入っている場合はまだAPIコールが行われていない
if len(st.session_state.message_history) == 1:
return
input_cost = MODEL_PRICES['input'][st.session_state.model_name] * input_count
output_cost = MODEL_PRICES['output'][st.session_state.model_name] * output_count
if "gemini" in st.session_state.model_name and (input_count + output_count) > 128000:
input_cost *= 2
output_cost *= 2
cost = output_cost + input_cost
st.sidebar.markdown("## Costs")
st.sidebar.markdown(f"**Total cost: ${cost:.5f}**")
st.sidebar.markdown(f"- Input cost: ${input_cost:.5f}")
st.sidebar.markdown(f"- Output cost: ${output_cost: 5f}")
def main():
init_page()
init_messages()
chain = init_chain()
# チャット履歴の表示
for role, message in st.session_state.get("message_history", []):
st.chat_message(role).markdown(message)
# ユーザの入力を監視
if user_input := st.chat_input("聞きたいことを入力してね!"):
st.chat_message('user').markdown(user_input)
# LLMの返答をStreaming表示する
with st.chat_message('ai'):
response = st.write_stream(chain.stream({"user_input": user_input}))
# チャット履歴に追加
st.session_state.message_history.append(("user", user_input))
st.session_state.message_history.append(("ai", response))
# コストを計算して表示
calc_and_display_costs()
if __name__ == '__main__':
main()
大体のブロックごとに何をやっているのか書いているのでそれほど困るところは無いかなと思いますが、
Cohereだけちょっと別な事をしてたりするのでそこら辺が他のLLMと同じにならないところがもどかしいというか慣れが必要そうな感じがしています。
所感
上にも書きましたが、少しCohereの扱いが違うのでそこを一緒に出来ないところが普及の妨げになるんじゃないかと思ったり思わなかったり・・・
ただ、最近はLLMにソースをぶん投げればだいぶまともな回答が来るようになったなと思うところなので、そこも含めて慣れていければ良いなと思います。
前回はLangchain+OpenAIでサクッと動きますと書きましたが、LLMを味方につけたらCohereでも思いのほか単純に行けたので前回よりはハードルは下がったんじゃないかと思ってます。
※単純に慣れてきた問題がありますが、LLMも賢くなったという事で・・・
次回
今回で複数のLLMを含めたチャットアプリが出来たので、次回はWebサイト要約アプリを作りたいと思います。