概要
- 実験回数を大幅に効率化する「実験計画法」について(ざっくり)説明します。
- 実験計画法の手続きがやや複雑なため、手続き部分をPythonで自動化します(今回の目的)。
実験計画法とはなにか(どう役に立つか)
実験計画法(じっけんけいかくほう、英: Experimental design、Design of experiments)は、効率のよい実験方法を設計(デザイン)し、結果を適切に解析することを目的とする統計学の応用分野である。
Wikipediaより
科学実験などで、いろんなパラメータ(原因)がある中でどの効果が大きいのかを知りたいとします。
実験計画法を用いると、それを調べるのに必要な実験回数を大幅に削減する事ができます。
難しそうに書いてしまいましたが、実は、この実験計画法は日常生活の場面でも役立ちます。
例として料理を例に取ります。
美味しいカレーを作りたいとして、カレーの美味しさを決めるパラメータとして、
- 煮込み時間
- 小麦粉の比率
- カレー粉の種類
を2種類ずつ試して、
どのパラメータがどれくらい美味しさに影響しているかを調べます。
| パラメータ | 1 | 2 |
|---|---|---|
| 煮込み時間 | 20分 | 60分 |
| 小麦粉の比率 | 5% | 10% |
| カレー粉の種類 | 横須賀海軍 | バーモント |
| 上記表の例で、これらを全ての組み合わせで試すと、 |
222 = 8回カレーを食べなければなりません。
ところが実験計画法を使うと、
4回食べるだけで、どの要素がどの程度美味しさに影響しているか分かります。
※下グラフは結果の例です。
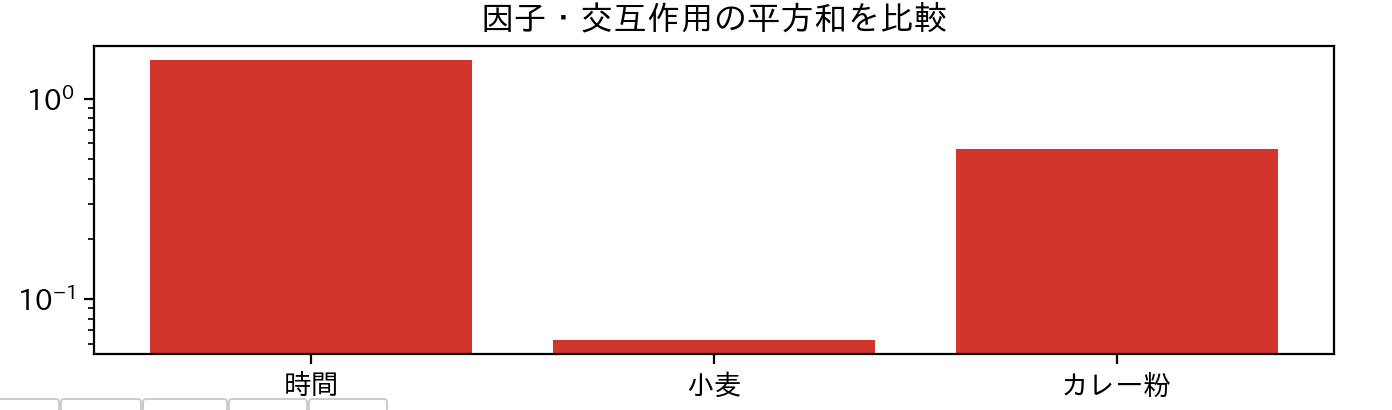
※この例では、煮込み時間が一番効果が高く、小麦粉比率の影響は小さい事がわかります。
実験計画法の威力
回数が半分(8⇒4)になるだけでもそこそこ凄いのですが、
さらにパラメータが増えるほど、実験計画法の威力を発揮します。
- パラメータが7個の場合、組み合わせが全部で128回 ⇒実験計画法なら、8回で済みます!
- パラメータが15個の場合、組み合わせが全部で32768回 ⇒ 実験計画法なら、16回で済みます!!
ここまで効率化できるのはすごいと思いませんか?
どんな人に有効か
前述したように、日常生活、研究生活、社会人生活などなど応用範囲は広いはずです。
使うことで生活が便利になります。
自分の例ですが、大学生のときに知っていれば研究を大幅に効率化できたのに、当時は知らなかった。
「大学生の自分に教えてあげたい」というのが、この記事を書くモチベーションです。
そして、なんとこの実験計画法は、小学生の夏休みの自由研究でも使えます。
根拠として、この方法でパラメータの影響を計算するとき**「平均」しか使わない**からです。
(理解している大人が少しサポートしてあげる必要はあるかもしれません。。)
それで? なぜPython?
実験計画法はとても強力な効率化ツールなので、多くの人に活用してもらいたいです。
ですが、使い方を覚えるのがちょっと難しいです。
これは個人的な考えですが、このような手法は数学の公式みたいなもので、
普段はツールとして楽に使いたいというのが工学的な発想です。
普段からツールとして使えるように、複雑な手続きの部分をPythonで自動化しちゃおう!
というのが、今回のPython化の理由です。
仕組みについて知りたい
数学の公式でもそうですが、一度は内容を理解する必要があると思います。
ですが、一度理解したあとは、実際使うときに毎回中身を覚えておく必要はないと考えています。
下記のリンクなど参考に勉強してみて下さい。
実験計画法の直交表によって実験回数を削減できる仕組みなどについては理解しておいていただきたいです。
Pythonによる実験計画法 - Design_of_Experiment(DoE) with Python in Jupyter Notebook
今回は、下記をPython + Jupyter notebookで実装しました。
Jupyter notebookのファイルはGitHubにアップしています。
- 2水準系の直交表を用いた実験計画の作成(create_expt_plan_2_levels.ipynb)
- 上記実験結果の解析(可視化から分散分析まで)(analysis_expt_result_2_levels.ipynb)
特徴 - Feature
- 因子だけでなく、交互作用も割り付け・解析ができます。
- 交互作用とは、因子同士の組み合わせによる効果のことです。
※カレーの例では、交互作用はないものとして説明を省いています。
使用言語とライブラリ - Dependency
- Python : 3.6.5
- pandas : 0.23.0
- openpyxl : 2.5.3
- matplotlib : 2.2.2
- scipy : 1.1.0
準備 - Setup
上記Python関連とJupyter Notebookの環境が必要です。
それらを一括でインストールするにはAnacondaが便利です。
Anacondaの説明やインストール方法(参考リンク)
Jupyter notebookで参考にした記事
使用方法 - Usage
2水準系の直交表を用いた実験計画の作成
- create_expt_plan_2_levels.ipynb
- **2水準直交表への因子と交互作用の割付(わりつけ)**を行います。
- 割付後の実験計画をEXCELに出力します。
●例
美味しいカレーに影響を与えるパラメータを調べたいとします。
- 煮込み時間:20 / 60 min
- 小麦粉割合:5 / 10 %
- カレー粉種類:横須賀海軍 / バーモント
これを下記のように入力します。
# 因子の名前
factor_symbols_all = ["時間", "小麦", "カレー粉"]
# 各因子の水準
factors = [
[20,60],
[5,10],
["海軍","BMT"]
]
# 見たい交互作用を因子の番号(o~)で指定。
interactions = [
# [0, 1], # AxB
# [1, 2] # BxC
]
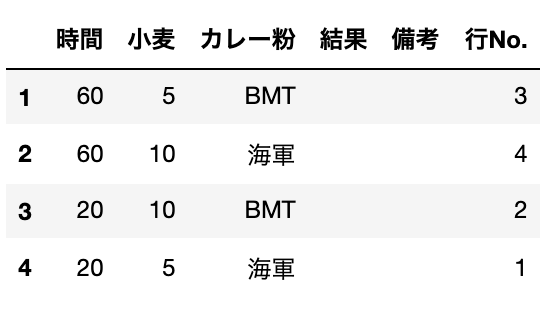
実行すると、下記のような実験計画表とEXCELが出力されます。
出力ファイル名:output_Expt_Plan_L*.xlsx
実験結果の解析(可視化から分散分析まで)
- analysis_expt_result_2_levels.ipynb
- 前回作成した実験計画を用いた実験後の結果データを用いて、
因子と交互作用の効果を可視化・分析・推定します。
●例
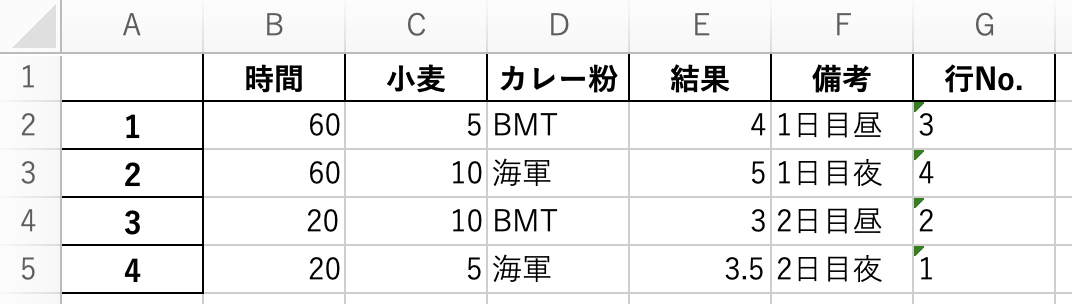
先程出力したEXCELに、結果を記入して保存します。
- ここでは、カレーの美味しさを5点満点として評価したとします。
- 結果を記入したファイルを「result_Expt_Plan_L4.xlsx」として保存します。
※実験結果の記入例
コードでファイルを指定します。
path = 'result_Expt_Plan_L4.xlsx'
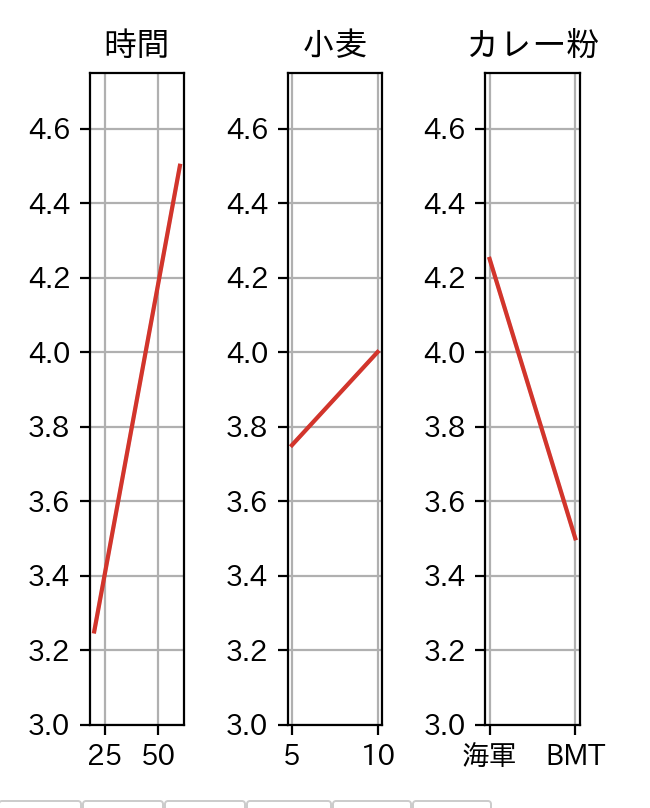
実行すると、各パラメータ(因子と呼びます)の単独の影響がグラフで可視化されます。
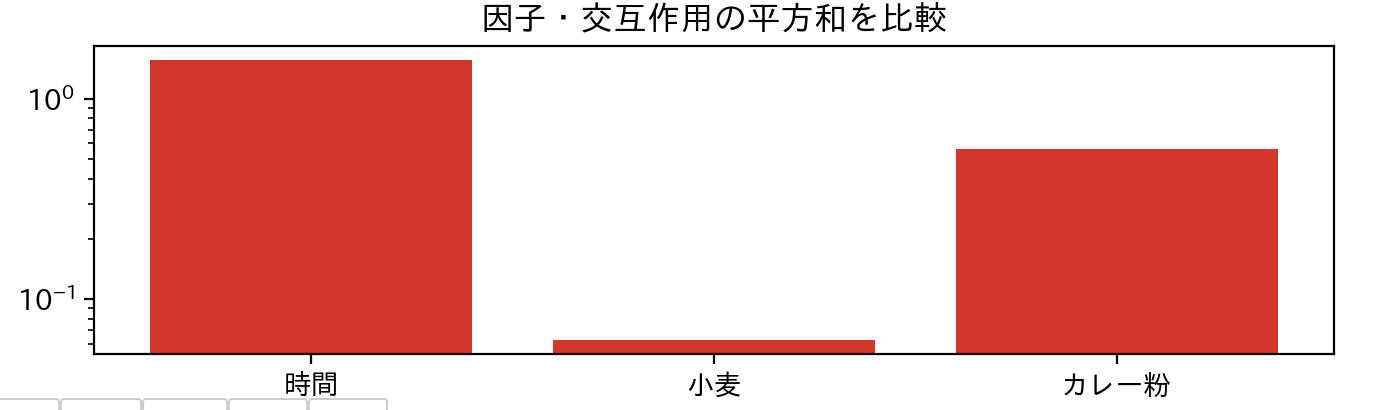
さらに**統計的な解析結果(分散分析表)**を見ることもできます。
結果から影響が小さいものを誤差としてプーリングするため、
今回の場合は、小麦を指定してやる必要があります。
# ['時間', '小麦', 'カレー粉']
pool_list = [0,1,0]
そうすると、下記のように分散分析されます。

ライセンス - License
Released under the MIT license
参考 - References
参考にした情報源(サイト・論文)などの情報、リンク
http://jasst.jp/archives/jasst05w/pdf/S4-1.pdf
https://www.slideshare.net/hajimemizuyama/par-49440366
今後の課題
現状は交互作用の割付けに、「交互作用の表」の方法のみを使用しています。
信頼性を上げるため、割付け方法に「交互作用の表を使った方法」と「成分記号による方法」
の2通りを行い、検算を追加したいと考えています。
また、今は2水準系のみにしか対応していません。
- 3水準系への対応
- 4水準、擬水準への対応
今後これらも実装していきたいと思います。
あとがき
最近勉強した実験計画法がかなり使えそうな印象だったので、
多くの人に知ってもらうのを第一目的としてこの記事を書きました。
わかりやすさを優先するために(自分の説明力不足のために)説明を省いてしまった部分もあります。
今後よい例が思いつけば追記するかもしれません。
Pythonについても初心者なので、荒かったり見づらい部分もあると思いますが、
誰かの参考になれば幸いです。
結果を報告資料にまとめる際は、以前に投稿した
パワーポイント資料自動作成も参考になると思います。
→Pythonを使ったレポートの自動作成(Qiita記事)
最後に、宣伝
iOSメモアプリ「サクメモ!」を個人開発でリリースしました。
シンプルな画面・ドラッグ&ドロップで並べ替えなど、直感的な操作が特徴のメモ・ToDo管理アプリです。
→サクメモ! - いつでもサクッとメモ,Todo,並べ替え(Apple App Store)