「あの請求書、どこに入れたっけ?」問題
先日、法人カードの申請で「直近1年分の請求書を全部出してください」と言われた。2025年5月〜2026年4月、つまり12ヶ月分。Google Driveを開いて、検索窓に「請求書」と打ち込む。出てくるのは取引先も年度もバラバラなPDFの山と、よく分からないスプレッドシート。
「Invoices」フォルダの中の「2025」フォルダを開く。その中に月別フォルダがある——はずだった。実際にあったのは「取引先別」のフォルダ構成で、月が混在している。しかも2026年に入ってからの請求書は「2026」フォルダではなく「未整理」フォルダに雑に突っ込んであった。
自分でフォルダを作ったはずなのに、自分のルールが思い出せない。半年前の自分はどういう基準で分類したのか、もはや謎だ。
結局、Driveの検索とフォルダを行ったり来たりして、12ヶ月分の請求書を集めるのに40分かかった。法人カードの申請ひとつでこれだけ時間を取られるのかと思うと、さすがに嫌になった。
フォルダ階層の限界
考えてみると、フォルダによる分類は最初から無理がある。
1枚の請求書には「2025年8月」「取引先A」「外注費」「経費精算済み」「プロジェクトX案件」といった複数の属性が同居している。フォルダはこのうちひとつの軸でしか整理できない。「年月で分けるか、取引先で分けるか、費目で分けるか」を毎回判断しなければいけないし、過去の自分の判断を未来の自分が覚えている保証もない。
ファイル名に全部の属性を詰め込めばいい、という反論はある。2025-08-15_取引先A_外注費_精算済.pdf みたいに。実際にやっていた時期もあったが、命名規則が揺らぐと検索でヒットしなくなる。「取引先A」と「株式会社A」が混在し始めた時点で破綻した。
ファイル名やフォルダではなく、ファイルそのものに「タグ・相手・種類・日付」をデータとして持たせて、好きな軸で絞り込む——そういう仕組みが欲しかった。要するに、Driveを諦めて文書管理システムを導入することにした。
Paperless-ngxという選択肢
調べた末にたどり着いたのが Paperless-ngx というOSSだった。GitHubで25,000スター超、Python/Django製の文書管理システムで、家庭用から個人事業主、小さな会社まで使われている。
Paperless-ngxでは、各ドキュメントが以下のメタデータを持つ。
-
Tag(タグ): 任意個。
光熱費経費精算済2024年確定申告など -
Correspondent(通信相手): 1個。
東京ガスAmazonなど -
Document Type(ドキュメント種類): 1個。
領収書契約書保険証券など - Created date(書類の日付): ファイル作成日ではなく、書類自体の日付
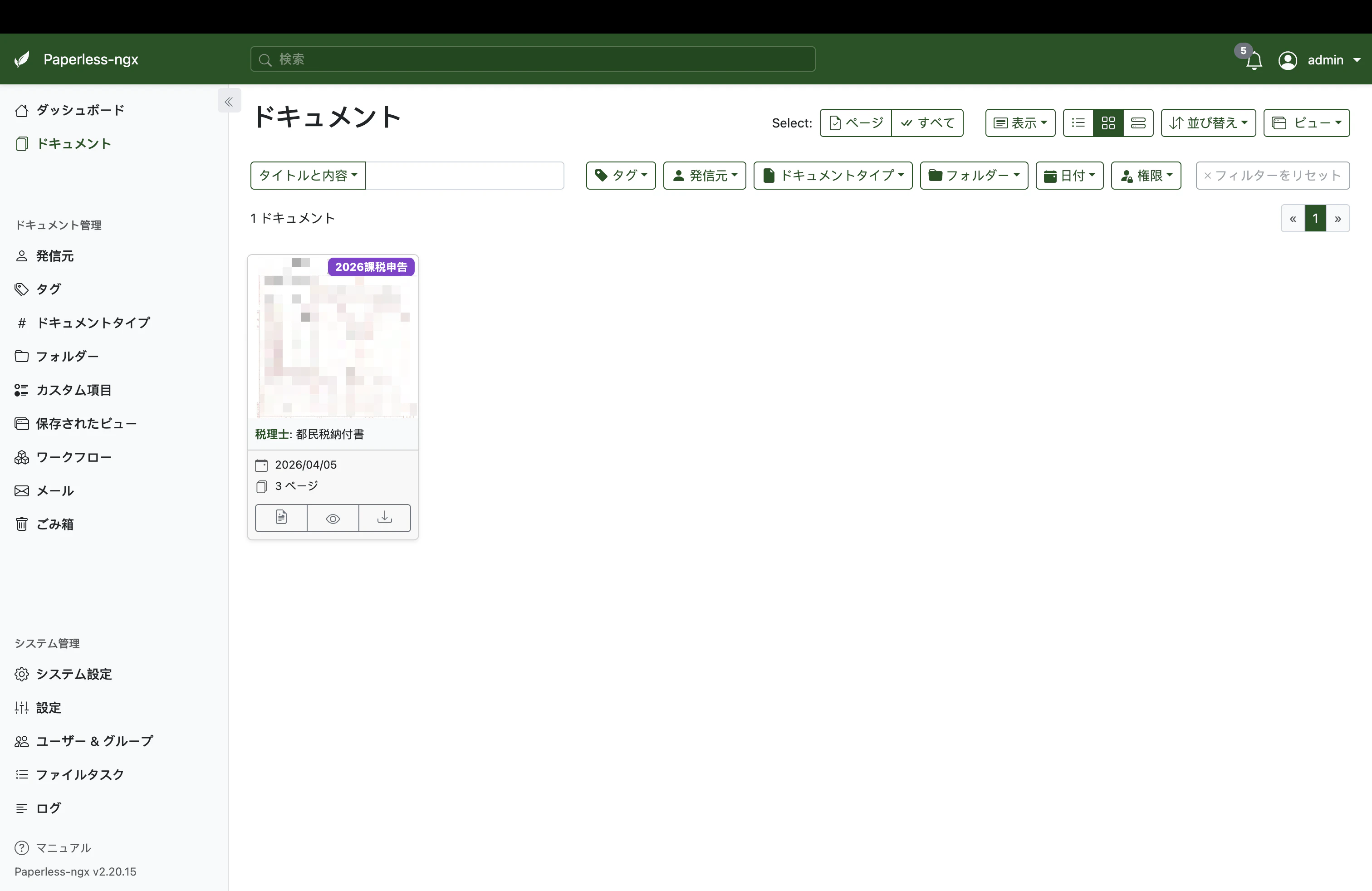
検索画面では「2024年」×「東京ガス」×「領収書」のようにメタデータを掛け合わせて絞り込む。Driveでフォルダを行き来していた作業が、ほぼ即座に終わるようになったというのが導入後の率直な感想だ。
加えてOCR(Tesseract)が全PDFに走るので、本文中の単語でも全文検索できる。手書きの伝票でも、印字されている契約番号で引っ張り出せる。
実際に使ってみる
Paperless-ngxはセルフホスト前提のソフトウェアで、導入方法は環境に応じて選べる。
サーバーがある場合
VPSや自宅サーバーがあるなら、公式のインストールスクリプトが手っ取り早い。
bash -c "$(curl -L https://raw.githubusercontent.com/paperless-ngx/paperless-ngx/main/install-paperless-ngx.sh)"
Docker Composeでの詳細な構成は公式リポジトリに書かれている。
サーバーがない場合
自分はVPSの管理が面倒で、Railwayで動かしている。自分用に作ったテンプレートも公開しているので、同じ構成で試したい人はそちらからどうぞ。
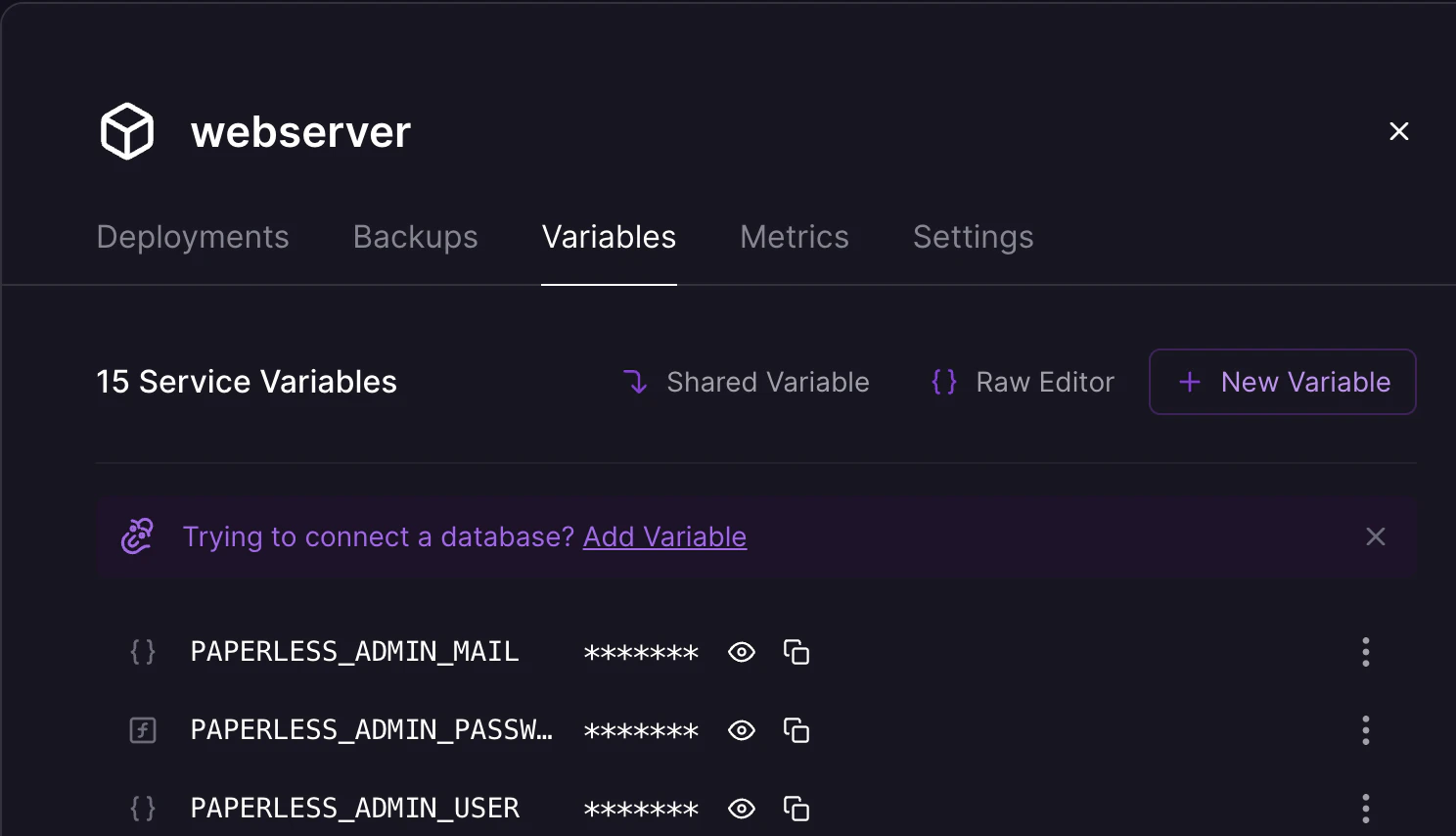
デプロイが完了したら、Railway上の webserver サービスの Variables(環境変数)を開くと、初期アカウントのユーザー名(admin)とパスワードが確認できる。このパスワードでログインしたら、まずは自分用のパスワードに変更しておくことをおすすめする。
日常の運用
ファイルの取り込みは、主に2つの方法で回している。
- Webからアップロード: ブラウザでPaperless-ngxを開いて、PDFをドラッグ&ドロップするだけ。PCで受け取った請求書や契約書はこれで十分。
- スマホアプリでスキャン: iOS/Android向けに「Paperless」というサードパーティアプリがある。自分のインスタンスのURLとアカウント情報を入力しておけば、スマホのカメラでスキャンした書類がそのままPaperless-ngxに同期される。郵便物や紙の領収書はこれで片付く。
個人事業主にも効く
このメタデータ4軸の分類は、個人事業主や小さな会社にも刺さると思う。
2024年から電子帳簿保存法が本格適用され、電子取引の請求書・領収書は電子のまま保存し、かつ「日付・金額・取引先」で検索できる状態にしておく必要がある。Paperless-ngxの Created date・Correspondent・タグ(金額10万円以上 のような独自タグ)はそのまま要件を満たせる。
freeeやマネーフォワードのストレージ機能でも対応できるが、月数千円のサブスクが乗ってくる。Paperless-ngxなら自前の小さなサーバーで完結し、データも手元から出ない。クライアントワークが多くて契約書・NDA・請求書が増え続ける個人事業主には、特に向いていると思う。
正直な不満点
しばらく使ってみて気になった点も書いておく。
- 同一PDFのバージョン管理が弱い: 同じ書類を修正して再アップロードすると、別ドキュメントとして登録される。履歴を辿るには手動でタグやメモで紐づける必要がある。あくまで「確定した書類のアーカイブ」として使うのが前提で、作業途中のファイルを版管理する用途には向いていない。もっとも、Google Driveのバージョン履歴もそこまで便利ではないので、これはどのツールでも似たような課題ではある。
- PDF自体の編集はできない: 「ちょっとテキストを追加したい」「署名を入れたい」といった操作はPaperless-ngx上ではできない。あくまでPDFの管理ツールであって、編集ツールではない。編集が必要な場合は別のアプリで開いて、修正後に再度取り込む運用になる。
- バックアップは自己責任: GoogleやDropboxのようなクラウドサービスと違い、データは自分のサーバーにしかない。サーバーが飛べば書類も消える。重要なファイルは定期的にエクスポートして別の場所にバックアップしておくのが無難だ。ホスティング型サービスに比べると、この一手間が地味に面倒ではある。
ただ、フォルダで詰むよりは100倍マシだ、というのが正直なところ。
まとめ
ペーパーレスに必要だったのは、より良いスキャナでもより速いクラウドストレージでもなく、「フォルダで整理する」という発想を捨てることだった気がする。
Paperless-ngxはその発想転換を支える道具として、個人にも小さな会社にも十分実用的だった。書類探しにストレスを感じている人は、一度試してみる価値があると思う。