分析業務を行うときにJupyter Notebookを使えるとめちゃくちゃ便利です。
頑張って複雑なSQL書くよりも、必要なデータだけ取り出して加工して見やすくどこかに置いておくのが良いと思います。
そんな時にJupyter Notebookです。最終的に下図のようになります。【リポジトリへのリンク】

他の言語は書いたことがあるがpythonは書いたことがないという人でも、csvをちょっと加工したりするのに使うのには特に困らないくらい簡単なのでやってみてください。
簡単に、Jupyterの特徴と利点は下みたいな感じです。特に大きな強みがgithubでそのまま確認できるところだと思います。
- ブラウザでインタラクティブに実行できる
- 大きいデータを加工する時も、一度読み込めば加工を試行錯誤できる(インタラクティブでないと毎度毎度読み込む必要があり非常に面倒)
- csv形式のデータを加工するのに便利
- pandas の dataframe と相性が良い(すごく見やすい)
- ちょっとずつ結果を確認したり、今変数に入ってるのが何か確認もしやすい
- notebookがgithub上で展開される
- markdownでコメントを書いておける
環境構築から行きましょう。
私の環境は macOS High Sierra です。
環境構築
python環境構築
pyenv + virtualenv を使って環境構築します。
ここはドキュメントがたくさんあるのでざっといきます。
何してるか気になる方は pyenv と pyenv-virtualenv で環境構築 などを読んでみてください。こちらの記事は分かりやすいです。
$ git clone https://github.com/yyuu/pyenv.git ~/.pyenv
$ git clone https://github.com/yyuu/pyenv-virtualenv.git ~/.pyenv/plugins/pyenv-virtualenv
$ echo 'export PYENV_ROOT=$HOME/.pyenv' >> ~/.bash_profile
$ echo 'export PATH=$PYENV_ROOT/bin:$PATH' >> ~/.bash_profile
$ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile
$ echo 'eval "$(pyenv virtualenv-init -)"' >> ~/.bash_profile
# pythonのversionは3.6とかでも良いと思います。2.7系はやめましょう。
$ pyenv install 3.5.1
$ pyenv virtualenv 3.5.1 main
$ pyenv global main
Mojave では zlib で pyenv install が失敗する場合があるので [MacOS Mojave]pyenvでpythonのインストールがzlibエラーで失敗した時の対応を参考にしてください。
ここまでで以下のようになってたらokです。
$ which python
/path/to/.pyenv/shims/python
$ pyenv versions
system
3.5.1
3.5.1/envs/main
* main
Jupyter install + 起動
$ pip install jupyter
$ mkdir hoge
$ cd hoge
$ jupyter notebook
# 勝手にブラウザが立ち上がってhttp://localhost:8888/treeが開くと思います。
# あとはブラウザからファイル作るとこのディレクトリ以下にファイルが作られていきます。
# ターミナルで Ctrl + c すると終了します。
ブラウザはこんな画面になります。

右の方の New から Python 3 をクリックすると下のようにipython notebookのファイルが開きます。これを編集していきます。
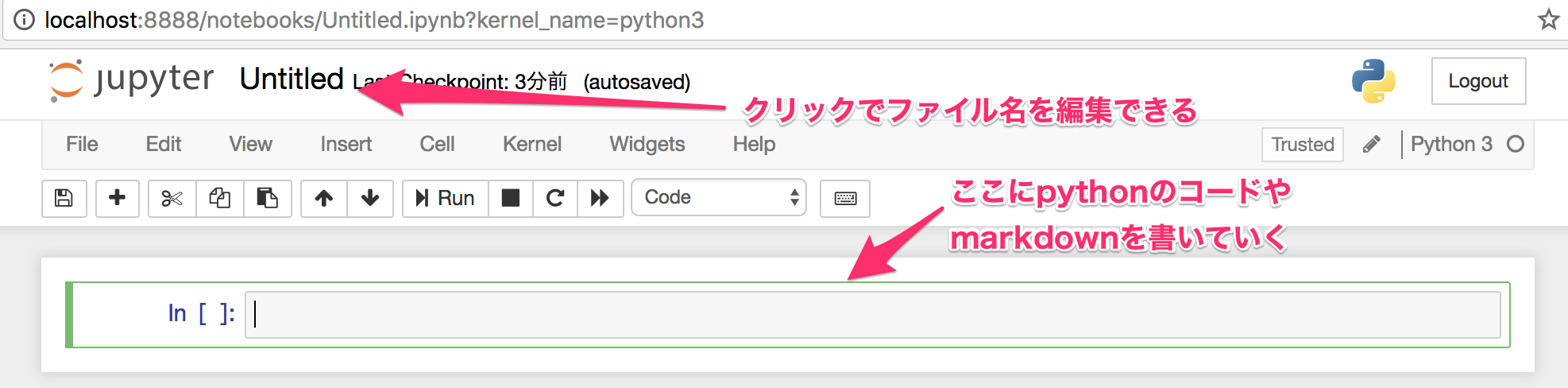
ファイル名を変えると hoge ディレクトリ以下にファイルが作成されているのがわかると思います。あとはゴリゴリ書いていけば良いです。
後のTipsでも記述しますが、pythonとmarkdownの入力モードは Esc→y と Esc→m でそれぞれに切り替えられます。
Jupyter Tips
メニューバー
上にごちゃごちゃしたメニューバーがありますが使わなくても下のコマンドで大体どうにかなります。個人的に、メニューバーで使うのは下の3つです。
- 左上の
File > Open- このファイルが置いてあるディレクトリが開く
- ディレクトリ作ったりファイル追加するときに使います
- 真ん中上の Kernel の下あたりにあるreloadアイコン
Restart the kernel- 全ての変数が初期化される
- cellを実行し直したい時に使う
- 同じく Kernel の下あたりにある黒四角アイコン
Interrupt the kernel- 重すぎる処理を実行してしまった時に止める用
コマンド
Jupyterには編集モードとコマンドモードがあります。
- 編集モード
- cellの中にコードを書くモード
- cellを選択(Enterかクリック)するとこのモードになる
- 選択中のcellの枠が緑
- コマンドモード
- cellを操作するモード
- ESCを叩くとコマンドモードになります。vimみたいな感じですね。
- 選択中のcellの枠が青
- 下記の基本コマンドを覚えましょう(コマンドモードでは下表のESC不要です)
| コマンド | 内容 |
|---|---|
| ESC → h | コマンド一覧がでる |
| ESC → a | 選択中のcellの上にcellを作成 |
| ESC → b | 選択中のcellの下にcellを作成 |
| ESC → m | cellをmarkdownモードに |
| ESC → y | cellをコードモードに |
| Ctrl + Enter | cellを実行 |
| Shift (Optionも可) + Enter | cellを実行して下にcellを作成 |
よく使うものはあらかじめimportしておける
~/.ipython/profile_default/startup/ 以下に以下のようなファイルを置いておくと起動時に自動的に読み込んでくれます。よく使うpandasなど書いておくと便利です。
import numpy as np
import pandas as pd
可視化などもする場合はここに書いてあるくらい記述しておくと便利ですね。
簡単な例(pandas DataFrameの紹介)
DataFrame はこんなやつ(下図)です。

今回は適当に作った、3日間の地域ごと、性別ごとのデータから、男性の地域ごとの割合を出します。
pandasはめちゃくちゃ便利なので、メソッドを使いこなせればすぐできるかもしれませんが、たまに使うくらいでは忘れるので、私は「csvをpandasのdf (DataFrame) として読み込み中身を確認→各行をdictに変換して処理する→最後にdfに戻して表示」という感じで使ってます。
ここに詳しく書いているので見てみてください。https://github.com/oharakouhei/introduce_jupyter/blob/master/hoge/summary_of_this_survey.ipynb
最終結果は下図の画面がブラウザで確認できます。

一応コードをまとめて書くと下になります。上のgithubリンクに何をしているか細かく書いているので参考にしてください。
from collections import defaultdict
csv_file = "./data/example.csv"
# 読み込み
df = pd.read_csv(csv_file)
# 各行をdictに変換して処理
records = df.to_dict("records")
dates = []
area2percentage_man = defaultdict(list)
man_records = records[1::2]
woman_records = records[::2]
for (man_record, woman_record) in zip(man_records, woman_records):
area = man_record['area']
date = man_record['date']
shortened_date = "/".join(date.split("-")[1:]) # 2018-06-01 -> 06/01
if shortened_date not in dates:
dates.append(shortened_date)
total = man_record['count'] + woman_record['count']
rate = 1.0 * man_record['count'] / total
percentage = round(rate * 100, 2)
area2percentage_man[area].append(percentage)
# 最後にdfに戻して表示
pd.DataFrame.from_dict(area2percentage_man, orient='index', columns=dates)
参考
pyenv と pyenv-virtualenv で環境構築
Jupyter Notebookをより便利に使うために、色々まとめ
データサイエンティストに向けたコーディング環境Jupyter Notebookの勧め