元記事
Python学習記録_プログラミングガチ初心者がKaggle参加を目指す日記
いよいよ実践編。
ここからは1日2日で内容がまとまるとは思えないのでひと段落ついたらその都度更新していくスタイルで行こうと思います。
この記事を書き終わるまでに何回心が折れるのか今から楽しみですね、頑張っていきます。
…というかいまだに環境構築せずにGoogleColab使ってるけど大丈夫なんかなコレ…
Kaggleについて
そもそもKaggleってなんぞやって話から。
他の方がわかりやすくまとめてるところが無限にありますが僕が目を通したところをいくつかおいておきます。
Kaggleとは?機械学習初心者が知っておくべき3つの使い方
Kaggle とは?始め方や入門「タイタニック問題」も紹介!
Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel
3つ目のqiita記事が意味わからんくらいわかりやすかったので主にこれを見ながら進めていきました。
GoogleKolabみたいな仮想環境?がKaggle上にもあるみたいなので今回はこっちに色々書いてみます。
とりあえず手を動かしてみる
愚直にやれって言われたことをやっていきつつわからないことがあったら都度ググってメモを残していきます。
import pandas as pd
import numpy as np
!ls ../input/titanic
train=pd.read_csv("../input/titanic/train.csv")
test=pd.read_csv("../input/titanic/test.csv")
gender_submission=pd.read_csv("../input/titanic/gender_submission.csv")
train.head()
test.head()
data=pd.concat([train,test],sort=False)
data.head()
concat()はデータを結合させる関数。
merge関数との違いはざっくり言って
・結合方向
→mergeは横にしか結合できないがconcatは縦横どちらでも可能。
・結合方法
→mergeは全部できるがconcatは内部結合と外部結合だけ
2つのDataFrameで横方向に結合するならばmerge関数、それ以外はconcat関数で実装すると良いらしいです。
だいたいconcat使うことになりそうですね。
print(len(train))
print(len(test))
print(len(data))
data.isnull().sum()
data['Fare'].fillna(np.mean(data['Fare']), inplace=True)
age_avg = data['Age'].mean()
age_std = data['Age'].std()
data['Age'].fillna(np.random.randint(age_avg - age_std, age_avg + age_std), inplace=True)
delete_columns = ['Name', 'PassengerId', 'SibSp', 'Parch', 'Ticket', 'Cabin']
data.drop(delete_columns, axis=1, inplace=True)
train = data[:len(train)]
test = data[len(train):]
y_train = train['Survived']
X_train = train.drop('Survived', axis = 1)
X_test = test.drop('Survived', axis = 1)
X_test.head()
X_train.head()
y_train.head()
ここまでがデータの前処理。
randint(a,b)はaからbの間のランダムな値を返す関数で、
平均‐標準偏差から平均⁺標準偏差の間でランダムな値を返すことで欠損値を埋めてます。
全てのカラムに処理ができたのでまたテスト用と学習用にデータを戻す、というところまでですね。
ちなみにここまでやってきたデータの前処理のことを特徴量エンジニアリングと呼ぶみたいです。
既存のデータを扱える形に整えてあげたり、既存の変数から新しいものを生み出したり…
とにかく説明変数をいじってこの後の機械学習のスコアをあげるための下準備ですね。
from sklearn.linear_model import LogisticRegression
clf=LogisticRegression(penalty='l2',solver='sag',random_state=0)
ここで使用するモデルのインポートとパラメータを指定。
何が何を指定してるのか分からなかったのでググりました。
scikit-learn – LogisticRegression
うん、何言ってるかわかんねえや!
多分こういうデータを扱うときはこのパラメータはこう、みたいなテンプレがありそうなので
とりあえず今はそういうテンプレだと思って覚えます。
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
y_pred[:20]
sub = gender_submission
sub['Survived'] = list(map(int, y_pred))
sub.to_csv("submission.csv", index=False)
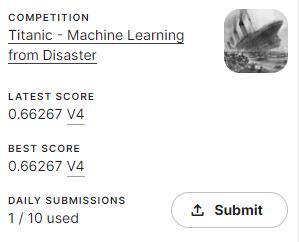
ということで線形回帰モデルを使ってのスコアがこちら。
0.66って多分とんでもなく弱いような…
というわけでここから精度をあげていきます。
精度をあげるために_再現性を担保する
精度向上のために手を出していく前に再現性についてのお話がありました。
「再現性がある」とは、何度実行しても同じ結果が得られることです。Kaggleで言うと、同一のスコアが得られると言い換えても良いでしょう。
再現性がないと、実行ごとに異なるスコアが得られてしまいます。今後、特徴量エンジニアリングなどでスコアの向上を試みても、予測モデルが改善されたか否かを正しく判断できなくなる問題が生じます。
今回の例で行くとageの部分でランダム関数を使っているので、提出するたびに微妙にスコアが変わってしまい再現性が担保できていないという問題があります。
なので、ランダムに振るのではなく代表的な指標である中央値を使おうねということでした。
age_avg = data['Age'].mean()
age_std = data['Age'].std()
data['Age'].fillna(data['Age'].median(),inplace=True)
ということでこちらに差し替え。
この再現性に関しては大事な考え方だと思うのでちゃんと覚えておきます。
精度をあげるために_新しい特徴量を作成する
次に仮説を立てて新しい特徴量を追加していきます。
ビジネスドメインの知識があればそもそもモデル作る前に仮説ありきで着手するのでもともとのデータにその特徴量があると思いますが
そうでない場合は自分で色々とデータを見てから仮説を立てる必要がありますよという感じ。
ここで役に立つのがEDAって呼ばれるやつだったりするんだと思います、たぶん。
ドメインの知識があろうがなかろうがデータは可視化して仮説の正当性を確認する、という動きは基本的に必要にはなりそうですね。
ということでここではseabornを使って色んなカラムの特徴を見ていきます。
import seaborn as sns
data['FamilySize'] = data['Parch'] + data['SibSp'] + 1
train['FamilySize'] = data['FamilySize'][:len(train)]
test['FamilySize'] = data['FamilySize'][len(train):]
sns.countplot(x='FamilySize', data=train, hue='Survived')
こちらの例では「一緒に乗ってる人数が増えればその分しがらみも増えて死亡率が高まるんじゃね?」という仮説を検証。
元のデータにあったParch(子供の数)とSibSp(配偶者)と自身の1を足したものをFamilySizeという新しい変数として用意してます。
そうして作成した新しい変数でグループ化した生存者数を表したグラフがこちら。
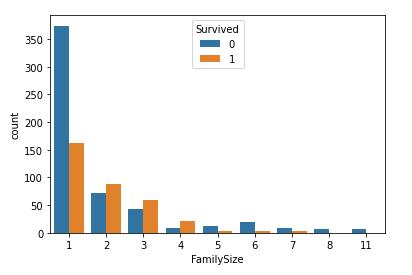
5以上の人はサンプルが少なめではあるものの0(死亡)が1(生存)を上回っているので、5人以上で乗船している人は死亡率が高そうだな…という傾向がわかりました。
さらに1の人はサンプルも多く、0(死亡)の数が1(生存)の数を上回っているため、ここの数字が1の人は何かの意味を持っていそうです。ぼっちは生きてる価値がないってこと??
なので、同乗者がいない人のフラグを作っておきましょう。
data['IsAlone'] = 0
data.loc[data['FamilySize'] == 1, 'IsAlone'] = 1
train['IsAlone'] = data['IsAlone'][:len(train)]
test['IsAlone'] = data['IsAlone'][len(train):]
ということでFamilySizeとIsAloneという二つの新しい変数を作成しました。
ここまででスコアはどの程度改善したんでしょうか。わくわく。
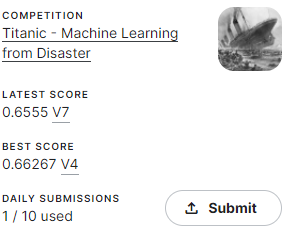
むしろスコア落ちてて笑いました。なんでや。
ソロ乗船なのか否かで結構大きな差がでてるし、FamilysizeよりIsAloneの方が特徴量として強いんかな…?
ということでFamilySizeを落として再度Submit。
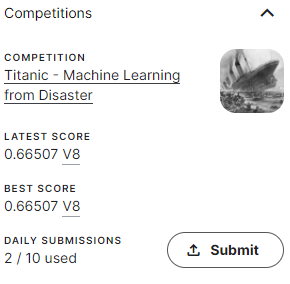
ちょっとだけ上がりました。やったぜ。
というわけでこんな形で新しい特徴量を作ったりその有用性を検証したりしてスコアを上げていく、というのが精度をあげるアプローチの一つですというお話でした。
精度をあげるために_機械学習のモデルを変更する
続いてはモデルの変更です。
ロジスティック回帰を使っていたとことをランダムフォレストやらなんやらに変えてみようね、って感じですね。
昨今のトレンドというか、環境キャラはLightGBMというやつらしいです。
精度が高い分色々と下準備が必要みたいです。
とにかく色んなモデルを試してみましょう、ということでまずはスタンダードなランダムフォレストから。
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
ロジスティック回帰を指定していたセルをこちらに差し替え。
これだけで学習モデルをランダムフォレストに変更できます。
差し替えてからsubmitした結果がこちら
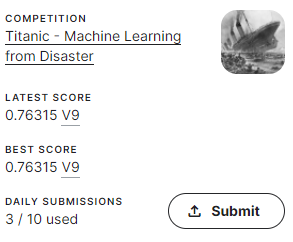
ランダムフォレストしゅごい…
ランダムフォレストでこれだけ精度が上がるんなら勾配ブースティングなるものを使ったら爆上がりなのでは…?
ということで今度はLightGBMに変更していきます。
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.3, random_state=0, stratify=y_train)
categorical_features = ['Embarked', 'Pclass', 'Sex']
LightGBMを使う時には
1学習用と検証用でデータセットを分けてあげる
2カテゴリ変数をリスト形式で宣言する
の2つがまず下準備として必要。
test_sizeでどれくらいをテストデータに割り振るのか指定してるのかな…?
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train, categorical_feature=categorical_features)
params = {
'objective': 'binary'
}
model = lgb.train(params, lgb_train,
valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
early_stopping_rounds=10)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred = (y_pred > 0.6).astype(int)
y_pred[:10]
下準備が終わったら学習スタート。
ここでもパラメータを指定してるのでここの設定次第でまた精度が変わりそうな気がしますが
とりあえず書いてあった通りに実装してみます。
submit結果はこちら
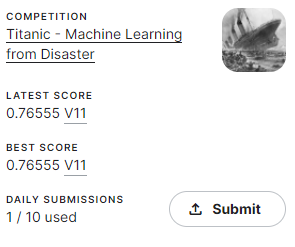
思ってたより伸び幅は小さいですがランダムフォレストよりも精度があがりました。
こんな形で色んなモデルを試してみて一番精度が高くなるものを採用していく、というのもフローの一つになりそうです。
精度をあげるために_パラメータを変更する
続いてモデルのパラメータをいじっていきます。
パラメータは手動で設定する方法とグリッドサーチなどで最適なものを見つけてもらう方法があります。
前にやったところですね。
ちょっと意外だったのが
一般に、ハイパーパラメータでのスコアの上がり幅は特徴量エンジニアリングで良い特徴量を見つけた場合に劣るので、あまり時間をかけずに手動で微調整をする場合も多いです。
というところでした。
結構パラメータにはシビアにならないといけないのかなと思っていたのですが、
どちらかというとデータの前処理・合成変数の作成が肝ってことみたいです。
というわけでここではパラメータを手動でいじるとどうなるかと実際に最適なものを機械に見つけてもらう方法を試します。
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train, categorical_feature=categorical_features)
params = {
'objective': 'binary',
'max_bin': 300,
'learning_rate': 0.05,
'num_leaves': 40
}
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid,
reference=lgb_train,
categorical_feature=categorical_features)
model = lgb.train(params, lgb_train, valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
early_stopping_rounds=10)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred = (y_pred > 0.6).astype(int)
y_pred[:10]
max_bin、learning_rate、num_leavesという3つのパラメータを指定。
それぞれのパラメータには意味があって手動で調整する時にはちゃんとそれぞれの意味を理解しておく必要があるとのこと。
中々に前途多難ですがここでもいったん書いてあった通りに実装します。

スコア更新できずでした…
ということでここからはパラメータの調整を機械にお願いしていきます。
import optuna
from sklearn.metrics import log_loss
def objective(trial):
params = {
'objective': 'binary',
'max_bin': trial.suggest_int('max_bin', 255, 500),
'learning_rate': 0.05,
'num_leaves': trial.suggest_int('num_leaves', 32, 128),
}
lgb_train = lgb.Dataset(X_train, y_train,
categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid,
reference=lgb_train,
categorical_feature=categorical_features)
model = lgb.train(params, lgb_train,
valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
early_stopping_rounds=10)
y_pred_valid = model.predict(X_valid, num_iteration=model.best_iteration)
score = log_loss(y_valid, y_pred_valid)
return score
study = optuna.create_study(sampler=optuna.samplers.RandomSampler(seed=0))
study.optimize(objective, n_trials=40)
study.best_params
うーむ…そろそろ何やってるのかよくわからなくなってきたぞ…
そろそろ関数の意味と引数に何をどういう形で指定してあげるのかがパンクしそうです…
出力結果を見る感じmax_binが255~500の間、num_leavesが32~128の間で最適な値を見つけるべく
色々変えて試行してくれてるんだと思います。
{'max_bin': 390, 'num_leaves': 101}
まあとにかくoptuna先輩がベストなパラメータを導き出してくれたのでこちらで指定してsubmitしてみます。
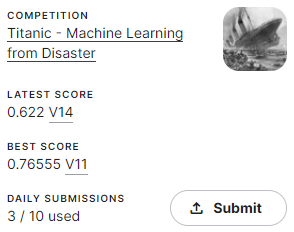
どうしてこうなった…???
って思ったら閾値の設定を忘れてました。悲しみ。
でも閾値設定したらスコアまた上がるでしょ!ってワックワクで修正したら
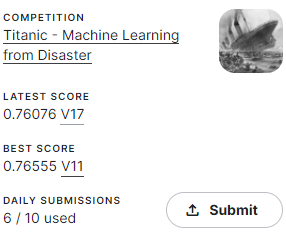
何故だ…???
これは↑で試行した40回ではデフォルト値を超えるパラメータの組み合わせが出なかったから、なんですかね…?
であれば試行回数は4桁単位でやらないといけないものなのかな…
とはいえパラメータ調整の流れは理解できました。
ここまでやってきたことをざっくりまとめると
・意味のありそうな特徴量にあたりをつけて新しい特徴量が作れないか考える
・特徴量の作成とデータの整形が終わったらモデルにあててみる
・色んな種類のモデルがあるのでいくつか試してみる
・良さそうなモデルがあれば細かいパラメータの調整をする
という流れですね。
一区切り
思ってた以上に難しいですww
なんというか…他の人が書いたコードパクってちょっといじって自分の作りたいモデルを作る、みたいなことはたぶんできるようになったと思います。
ただ「仕組みはわかってないけどこういう作業すれば予測が返ってくるよ!」だとブラックボックスすぎて怖いですね。
最低限何してるかを理解できるようになるまでまだまだ時間がかかりそうですが、
それができてない内から運用に取り入れるのは怖すぎるので
めげずに勉強を続けようと思います。
とりあえず当面の目標は今回写経させていただいたコードについて
良くわかってない関数と引数を一つ一つ整理していくこと、でいこうと思います。
引き続きがんばれ自分