元記事
Python学習記録_プログラミングガチ初心者がKaggle参加を目指す日記
9日目です。なんやかんや最終日まで来ました。
ちょっと色々詰め込みすぎた気もしますがとりあえずやっていこうと思います。
CRISP-DM入門 20m
CRISP-DMとは
CRISP-DM(CRoss-Industry Standard Process for Data Mining)は、データ分析プロジェクトのためのプロセスモデルです。
CRISP-DMでは、下のようなプロセスでデータ解析が行われます。
プロセスに矢印が引かれ、円形のプロセスマップからもわかる通り、データ解析の分野では必要に応じて、処理を戻ってやり直したり、繰り返したりすることが求められます。
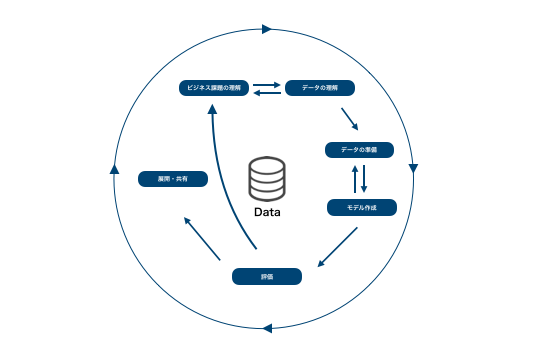
CRISP-DMの6つのプロセス
CRISP-DMには、次の6つのプロセスがあります。
❶ビジネス課題の理解
まず始めにビジネス課題を理解するところから始まります。(Business Understainding)
❷データの理解
データの理解のフェーズでは、分析のもととなるデータについて理解します。
データを理解するためには、ただ手を動かせば良いわけでなく、担当者との密なコミュニケーションが必要になります。さらに、可視化を行うことでデータ理解につながります。
❸データの準備
データを理解できたら、モデルを作成する前段階としてデータを準備・前処理します。
データ前処理は、全体の8割を占めると一般的に言われます。
どのように特徴量を作成するかが、次のフェーズのモデルの精度を左右します。さらには、ビジネス理解のフェーズに定めた分析目標を達成できるかどうかにもつながるため、作業には十分に時間を割くべきです。
❹モデル作成
このフェーズでモデル(データに潜むルールやパターンの集まり)を作成します。
❺評価
モデル作成フェーズで得られた結果から、分析の目標とビジネス目的を達成できるか評価します。
次の『展開・共有』フェーズで実際にモデルを運用し、効果を確認することも必要です。
評価の結果、ビジネス目的を達成できなければ、ビジネス理解のフェーズに戻り、再度分析の目標と成功の判定基準を設定します。
❻展開・共有
ビジネス目的を達成できるモデルを得られたら、既存の業務フローへ展開、共有し既存システムに組み込みます。
このフェーズでは組み込んで終わりではなく、効果をモニタリングし、フィードバックを行い、さらなる改善を繰り返します。
モデルは一度作って終わりではなく、継続的に価値を出し続けるために、最新の状態に保つ必要があります。分析の価値が下がらないよう、モデルは日々更新します。
ここでもデータ処理の重要性が説かれてますね。
モデル作成のところが一番時間かかりそうなイメージがあったので意外です。
Pythonでデータの理解を行う
ということでEDAの段階でするべきあれこれの操作を学んでいきます。
import pandas as pd
df1=pd.read_csv('/content/train.csv')
df1.head()
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
まずはhead()。
これで扱うデータの頭5件を見ることができます。
df1.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
続いてinfo()。
これはデータフレームの概要を返してくれる。
見た感じだとカラムの一覧とデータ型、それとnullになってる値の確認ができそう。
ここで欠損値が多いカラムは処理するのが必要になりそうです。
df1.describe()
PassengerId Survived Pclass Age SibSp Parch Fare
count 891.000000 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208
std 257.353842 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429
min 1.000000 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400
50% 446.000000 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200
75% 668.500000 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200
describe()で各カラムのカウント・平均・標準偏差・最小値、25%50%75%分位数、最大値を見ることができる。
ここで偏りがないか、外れ値がないかを確認できそうです。
こんな形で概要というデータの特徴をつかむためのメソッドはほかにもあって以下の通り。
df.head() => data frameの最初の5行を表示
df.info() => カラム名とその型の一覧を表示
df.tail() => data frameの末尾5行を表示
df.columns => data frameのカラム名を表示
df.shape => data frameの次元数(2次元データの場合は行列を表示)
df.describe() => 基本統計量の表示(数字データのみ)
df.sample() => ランダムサンプリング
データの可視化
続いて前回学んだseabornを使って可視化していく。
import seaborn as sns
df1.Age.plot(kind='hist')
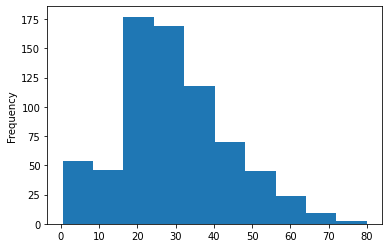
こちらは年齢ごとのヒストグラム。
データフレーム名.カラム名.plot(kind='グラフの種類')
が構文ですね。
他にも
sns.jointplot(x="Age",y="Fare",data=df1,size=7)
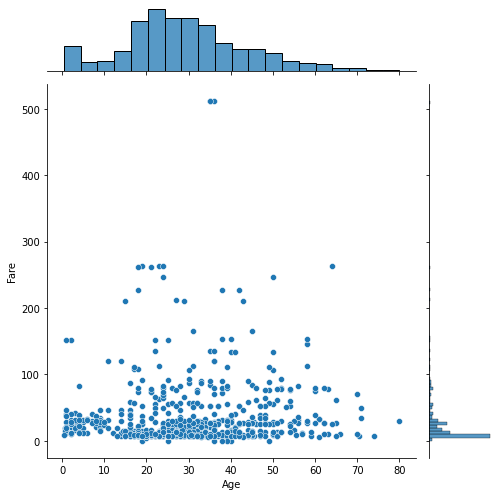
年齢とチケット料金の散布図を出してみたり
import numpy as np
sns.barplot(x="Pclass",y="Survived",data=df1,estimator=np.average)
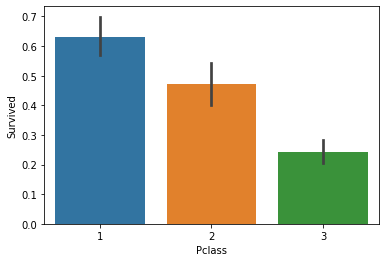
Pclass(客室のグレード)ごとの生存率を出してみたり。
これ生存者数でみる(estimatorをsumで指定する)と1と3が同じくらいの数になってましたが率で見るとやっぱり1のグレード高い人ほど生き残ってるんですね。無情。
ここまでが可視化する部分。
で、ここからはデータの処理の話になります。
preparation for machine learning
さて、機械学習とは関数f(θ)を求めることと一言で表すこともできます。
x⇒f(θ)⇒y
ただ機械学習モデルf(θ)に入力xを渡す場合、xは数字でなければなりません。
また、xに欠損値があるとアルゴリズム入力できないです。
ということでやることはざっくり3つ
①文字型のカラムを数字型に変換する
②欠損値が多すぎるカラムは削除する
③一部が欠損しているカラムは欠損値を補完する
で以下のような処理をする。
import pandas as pd
df1=pd.read_csv('/content/train.csv')
print(df1.info())
print(df1.Sex.unique())
change_sex_to_numerical = {"male":0,"female":1}
df1["Sex"] = df1.Sex.map(change_sex_to_numerical)
print(df1.info())
df2=df1.drop(['Name','Ticket','Cabin','Embarked'],axis=1)
print(df2.info())
df2=df2.fillna(0)
print(df2.info())
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
['male' 'female']
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null int64
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Sex 891 non-null int64
4 Age 714 non-null float64
5 SibSp 891 non-null int64
6 Parch 891 non-null int64
7 Fare 891 non-null float64
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Sex 891 non-null int64
4 Age 891 non-null float64
5 SibSp 891 non-null int64
6 Parch 891 non-null int64
7 Fare 891 non-null float64
ちょっと見づらいですが最終的にデータ型が全て数字でnullがないデータセットになります。
やっていることは
Sexの中身を確認してmaleを0、femaleを1に変換
データ型がobjectになっているName,Ticket,Cabin,Embarkedのカラムを削除
Ageに一部欠損があるのでfillnaを使って0で埋める
という感じですね。
ここまでやってやっと機械学習モデルに入力が可能になるようです。
今まで分析に協力していただいていた機械学習チームの皆さんに土下座したくなりました。
これからはちゃんと諸々の処理したデータをお渡しするようにします…
アンサンブル学習 15m
アンサンブル学習
アンサンブル学習とは複数のモデルを組み合わせて予測する手法です。
ポイントは性能の低い学習器(弱学習器)を組み合わせて、高性能な学習器を作ることができる点です。
アンサンブル学習には、バギングやブースティングなどがありますので、それらを1つ1つ見ていきます。
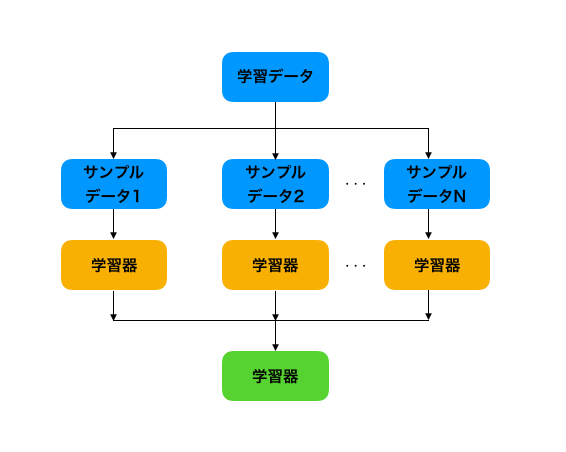
バギング
バギング(bootstrap aggregating: bagging)は、元の学習データからランダムにn行のデータを重複を許し抽出し、新しい学習データを作成するということを繰り返します。
何度もデータの一部変えながら学習を行うということです。
これをブートストラップと言います。
学習器を並列に学習して組み合わせる手法だと言えます。
分類の場合、結果の集約、回帰の場合は平均値をとったりします。
バギングの利点として、学習器を並列で学習できることや、過学習しにくいことが挙げられます。
ランダムフォレストはバギングの中で決定木を用いている手法です。
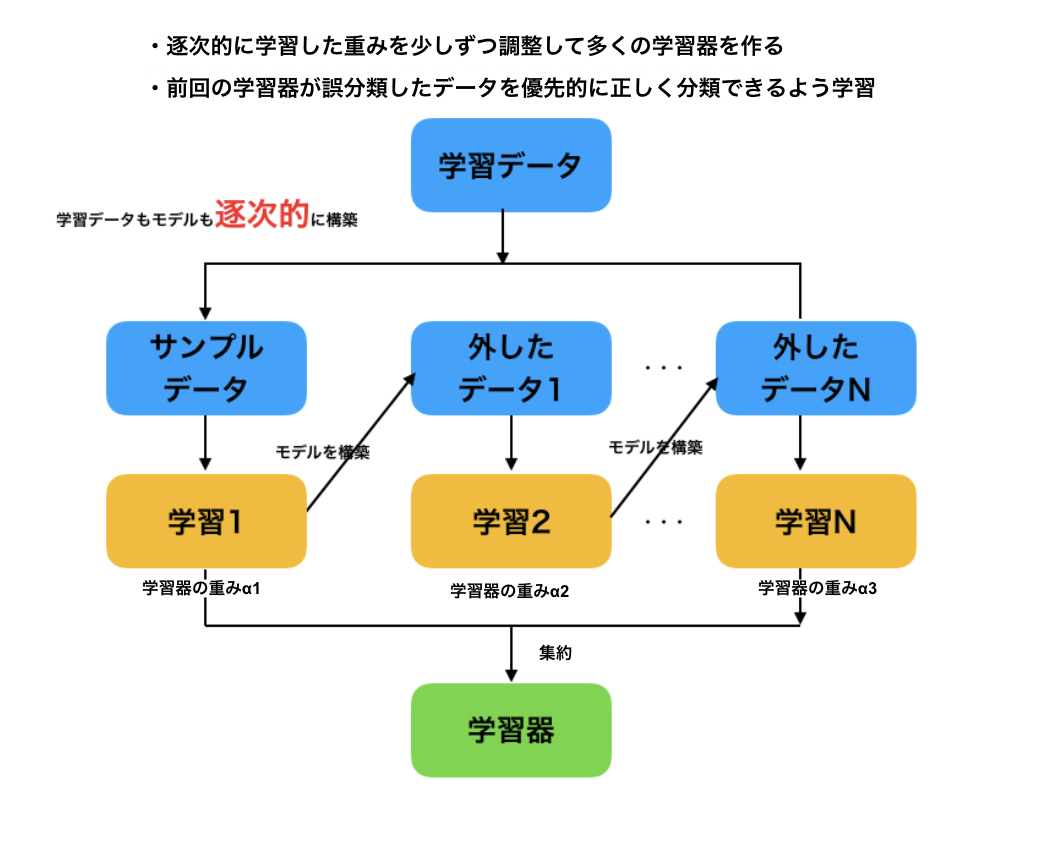
ブースティング
ブースティング(boosting)とは、直前の予測器の修正を繰り返し行ない、学習データに変化を与えながら学習器を作ります。
ブースティングも複数の予測器から強い予測器を作ることは同じですが、バギングが並行して訓練するのに対して、ブースティングは逐次的に処理します。
ブースティングは学習不足(underfitting)傾向の時に効果的な手法と言われています。
なんとなくブースティングの方が精度高そうなモデルができる気がしますがどうなんでしょう。
過学習のリスクが高い時はバギングでそうじゃない時はブースティング、みたいな住み分けですかね…?
ホールドアウト法・交差検証 15m
こちらは4日目にやっていたので割愛。
Python学習記録_4日目.自作関数のモジュール化とNumpyについて
回帰分析 40m
回帰分析とは
回帰分析とは、予測したい値(目的変数)を1つもしくは複数の変数(説明変数)を用いて予測する分析手法です。
回帰は教師あり学習に分けられます。
回帰分析の活用シーンは以下の通りです。「駅からの距離」から「家賃」を予測
「広告費」から「ライブコンサートの来場人数」を予測
「広告宣伝費」から「売上」を予測
「町の警察官人数」から「月間の犯罪発生件数」を予測
「気温」から「アイスコーヒの注文数」を予測上記の左側の「」部分の値を説明変数と呼び、右側の予測したい「」の部分を目的変数と呼びます。
(予測に使う変数を説明変数、予測するものを目的変数と呼びます。)単回帰分析は、1つの説明変数からゴールとなる1つの目的変数(数値)を予測する分析手法です。
例えば、テレビCM(説明変数)から獲得契約件(目的変数)など、1つの説明変数からゴールとなる1つの目的変数を予測するのが、単回帰分析です。
重回帰分析は、テレビCMや販促物、雑誌など複数の説明変数からゴールとなる1つの獲得契約件(目的変数)を予測するのが重回帰分析になります。
重回帰分析は単回帰分析に比べ、複数の説明変数を利用できる事から様々なデータ分析で利用されます。
話が長い
要するに
数値を予測するためのものが回帰分析
予測に使うものが1個だけなら単回帰、2個以上使うなら重回帰
色んなデータ使えるから重回帰便利だよ
ってことですね。
実際に書いてみるとこんな形になるそうです。
from sklearn.linear_model import LinearRegression
x = [[12,2],[16,1],[20,0],[28,2],[36,0]]
y = [[700],[900],[1300],[1750],[1800]]
model = LinearRegression()
model.fit(x,y)
x_test = [[16,2],[18,0],[22,2],[32,2],[24,0]]
y_test = [[1100],[850],[1500],[1800],[1100]]
prices = model.predict(x_test)
for i, price in enumerate(prices):
print('Predicted:%s, Target:%s'%(price,y_test[i]))
score = model.score(x_test,y_test)
print("r-squared:",score)
Predicted:[1006.25], Target:[1100]
Predicted:[1028.125], Target:[850]
Predicted:[1309.375], Target:[1500]
Predicted:[1814.58333333], Target:[1800]
Predicted:[1331.25], Target:[1100]
r-squared: 0.7701677731318467
ピザの直径とトッピングの数で金額を予測する、という仮定の話らしいです。
解説見るとそれだけで理解した気になりそうなのでいったん自分で見て考えます。
sklearnから持ってきているLinearRegressionが回帰分析用のモデルで、
model.fit(説明変数,予測変数)でモデル作る感じですね。
そして精度検証用のx_testとy_testでxから予測した値が実測値とどれくらい近いかを確認して、
最終的にmodel.score(説明変数,目的変数)で精度を出力
という流れです、たぶん。
enumerateと%sだけよくわかりませんでした。
それぞれ以下の通り。
Pythonの標準関数であるenumerate関数は、リストのインデックスと要素を同時に取得できます。
この関数により、iにはインデックスが代入され、priceには予測されたインデックスに対応する価格を受け取っています。
なるほど、iにインデックス番号渡して、iを参照してy_testの値を代入してるのか。
こんな感じの処理する時にリストのデータにいちいちインデックス振るのめんどい時に便利そうです。
print関数内の%sですが、%演算子と呼ばれるもので、%sに特定の文字列を埋め込むことが可能です。
formatみたいなもんですかね。
って思って調べてみたらpython3ではformatメソッドが推奨されてるらしいのでコイツのことは忘れます。
ということでだいたい理解できました。
これで簡単な回帰分析くらいなら自力でできるような気がしてますが多分気のせいなので
後でちゃんと復習しておきます。
評価指標(回帰) 15m
平均二乗誤差 (MSE)
平均二乗誤差 (MSE)とは、それぞれのデータに対して、実際の値と予測値の差の2乗を計算しその総和をとり、データの総数で割った値です。
平均二乗誤差 (MSE)では、値が小さいほど誤差の少ないモデルと言えます。
ちなみにMSEは"Mean Squared Error"の略です。
MSE=\frac{1}{n}\sum_{i=0}^{n-1} (y_i-y_i^{\prime})^2 \\
sklearnだとmean_squared_errorで出せるそうです。
二乗平均平方根誤差(RMSE)
二乗平均平方根誤差(RMSE) とは、上記のMSEに平方根をとることで計算されるものです。
※平均平方根二乗誤差と呼んだりもします。
二乗したことの影響を、平方根で補正しています。
ちなみにRMSEは"Root Mean Squared Error"の略です。
この値が小さければ小さいほど、誤差の小さいモデルであると言えます。
数式では二乗平均平方根誤差は以下のように表せます。
RMSE=\sqrt{\frac{1}{n}\sum_{i=0}^{n-1} (y_i-y_i^{\prime})^2} \\
こちらを求める際には先ほどのmean_squared_errorをsqrdで囲めばOK。
決定係数
決定係数(R2)とは、推定された回帰式の当てはまりの良さ(度合い)を表します。
0から1までの値を取り、1に近いほど、回帰式が実際のデータに当てはまっていることを表しており、説明変数が目的変数を説明していると言えます。
逆に0に近ければあまり良くない性能であることを示します。
R^2=1-\frac{\sum_{i=0}^{n-1}(y_i-y_i^{\prime})^2}{\sum_{i=0}^{n-1}(y_i-\bar{y_i})^2} \\
らしいです。
この手の数式を再現するたびに動悸息切れ眩暈吐気等の症状に襲われるので勘弁してほしい
ランダムフォレスト 30m
ランダムフォレストとは
ランダムフォレストとは決定木を拡張したもので、分類、回帰、クラスタリングに用いることが可能な機械学習のアルゴリズムのひとつです。
ランダムフォレストは、複数の決定木でアンサンブル学習を行う手法になります。
アンサンブル学習とは、複数の学習器を用いて学習を行う手法です。
複数の学習器で学習することによって、精度が高くなると一般的に言われています。
アンサンブル学習には大きくバギング、ブースティング、スタッキングなどがあります。
ランダムフォレストはバギングの中で決定木を用いている手法という位置付けになります。
ランダムフォレストには、下記のようなメリットとデメリットがあります。メリットとしては、
● データ数が多くても高速な学習と識別が可能
ー ランダム学習により高次元特徴でも効率的な学習が可能
ー 選択された特徴量のみで識別可能
● 教師信号のノイズに強い
ー 学習データのランダム選択により影響を抑制可能
● 特徴量の正規化や標準化が必要ない
などが挙げられ、デメリットとしては
● オーバーフィッティング(過学習)しやすい
ー パラメーターが多い
ー 学習データが少ないとうまく学習ができない
などが挙げられます。
ランダムフォレストの実装(分類)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
x = iris.data[:, 2:]
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)
clf_rf = RandomForestClassifier(n_estimators=30, random_state=0)
clf_rf = clf_rf.fit(x_train, y_train)
from sklearn import metrics
def measure_performance(x,y,clf, show_accuracy=True,show_classification_report=True, show_confussion_matrix=True):
y_pred=clf.predict(x)
if show_accuracy:
print("Accuracy:{0:.3f}".format(metrics.accuracy_score(y, y_pred)), "\n")
if show_classification_report:
print("Classification report")
print(metrics.classification_report(y, y_pred), "\n")
if show_confussion_matrix:
print("Confussion matrix")
print(metrics.confusion_matrix(y, y_pred),"\n")
measure_performance(x_train, y_train, clf_rf)
ひえぇ…クソ長え…
前半がモデル作成部分。
RandomForestClassifierがランダムフォレストのメソッドですね。
n_estimatorsで作成する決定木の数、randam_stateがランダムサンプリングする時のシード値というパラメータ設定みたいです。
この辺のパラメータはグリッドサーチで最適なものを見つけられるんですかね…?
そして後半のmetricsがモデルの評価部分ですね。
confusion_matrixとclassification_reportを見れば適合率とか再現率がでてくるので最悪ここだけ見ておけばOKそうな予感。
しかしコイツを自分で書けるようにならないといけないのか…
9日目の感想
ということでインプットの段階が本日でいったん終了しました。
正直なところ最後のランダムフォレスト実装のコードなんかはとても1からはかけそうにないですが…
とはいえSQLを覚えた時もそうだったんですが、とりあえず色んなコードを見てみて自分の引き出しを増やしていくのが
まず慣れる第一歩な気がするので、そのための最低限の下地はできたと思いたいです。
次回からは実際にKaggleのタイタニックのデータを触ってみます。
その過程もこちらに記事として残していく予定なのでもう少し続けようと思います。
多分ボコボコにされると思いますがとりあえずモデルを作って指標を見るところまでは続けていくつもりなので
もう少しだけお付き合いいただければと思います。
来週からも頑張れ自分