元記事
Python学習記録_プログラミングガチ初心者がKaggle参加を目指す日記
4日目numpyについてがメインになりそうです。
今日も頑張ります。
グリッドサーチ 15m …
はじめに
このテキストは、交差検証の続きです。
先に交差検証のテキストをお進めください。
じゃあ交差検証もカリキュラムに入れてくれ…
ということで交差検証から見ていきます。
これはたぶんクロスバリデーションってやつですね、機械学習チームとの協業で何度か出てきたワードな気がします。
ホールドアウト法
ホールドアウト法は、モデルを作る学習データ(x_train,y_train)と、モデルを評価するテストデータ(x_test,y_test)に分割して評価します。
学習したモデルで予測する際に、学習に使っていない未知のデータで予測します。
よってデータを分けることで、汎化性能(未知のデータに対する性能)を向上させることができます。
ホールドアウト法は大量のデータセットがあり、モデルの推論に時間がかかる場合などに利用されます。
※大量や時間がかかる目安は決まっていません。
元のデータセットからトレーニングデータ(x_trainとy_train)とテストデータ(x test と y test)に分割します。
その後、xとyを含むトレーニングデータ(すなわちx_trainとy_train)を用いてモデルを学習させます。
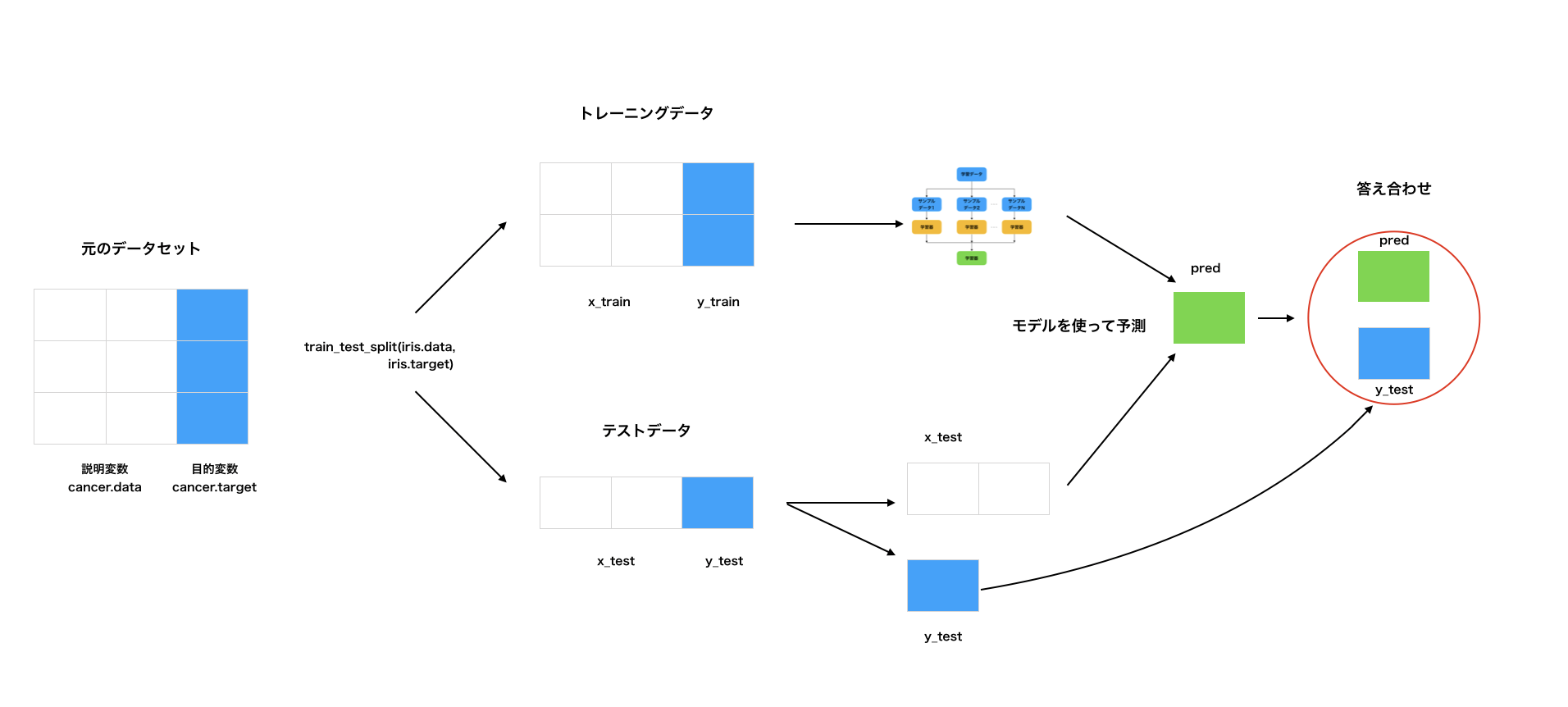

次にテストデータのx_testを用いて、先ほど学習させたモデルを予測し予測した結果を得ます。(predが得られる)
テストデータの実際の答え(y_test)とモデルが予測したpredを用いて答え合わせを行います。
(※画像のcancer.dataやcancer.targetは、scikit-learn付属の乳がんデータセットをcancerという変数名に格納している状態です。)
もし、未知のデータを予測するにあたり全てのデータを学習データにしてしまうと、過学習してしまいます。
scikit-learnのtrain_test_split()を使うことでホールドアウト法により、データを分けることが可能です。
過学習は以前痛い目を見た記憶がありますね…
目的変数にセットした変数にほとんど等しい変数を説明変数に入れた結果正解率が0.96くらいのモデルを作ってもらってぬか喜び、みたいなことがありました。
scikit-learnは以前勉強したライブラリの一種ですね!
なるほど、ホールドアウト法っていう分析によく使う処理をライブラリ化することで時短してると…
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris() # アイリスの花のデータセットの読み込み
x = iris.data # 全体は150個
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y) # データをトレーニング用とテスト用に分割
#(test_size=テストサイズの数を引数に渡すことで、テストサイズを調整可能です)
print(len(x_train)) # 112(全体の75%がトレーニングデータに分割)
print(len(x_test)) # 38(全体の25%がテストデータに分割)
例文はこんな形で、トレーニング用とテスト用の割合を個別に設定することもできるが何もしなかった場合は75:25になるとのこと。
sklearnには他にも色々ありそうですね…覚えるのに苦労しそうな気配…
交差検証(クロスバリデーション)
交差検証(cross-validation)とは、汎化性能を評価する統計的な手法で、分類でも回帰でも用いることができます。
機械学習を行うとき、学習を行うための学習データと未知のデータに適用したときのモデルを評価するためのテストデータがあります。
トレーニングデータでの性能がとても良いのにもかかわらず、テストデータでの性能が悪くなってしまうことを過学習と言います。
過学習は機械学習を扱う上で大変重要な用語ですのでしっかり覚えておきましょう。交差検証の中でも、よく利用されるK-分割交差検証について説明します。
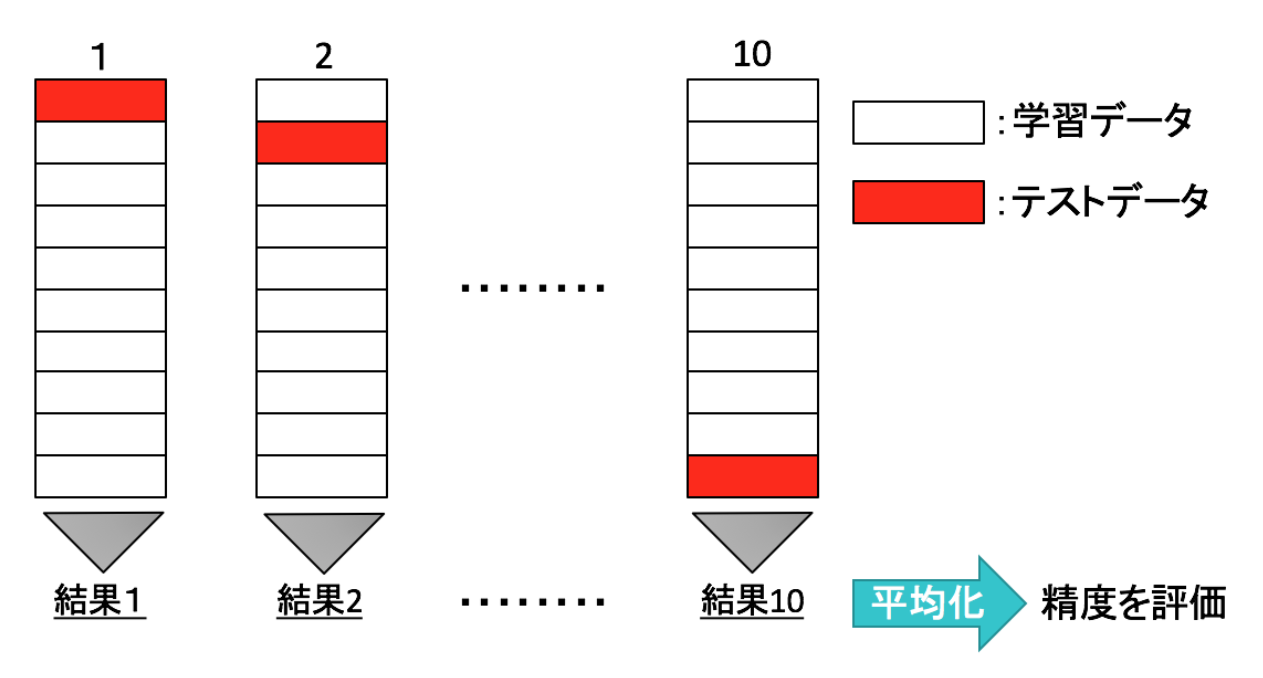
K-分割交差検証は、データをK個に分割してそのうち1つをテストデータに残りのK-1個を学習データとして正解率の評価を行います。
これをK個のデータすべてが1回ずつテストデータになるようにK回学習を行なって精度の平均をとる手法です。
from sklearn.model_selection import cross_val_score, KFold
from scipy.stats import sem
import numpy as np
def evaluate_cross_validation(clf, x, y, K):
cv = KFold(K,shuffle=True,random_state=0)
scores = cross_val_score(clf,x,y,cv=cv)
print(scores)
print ("Mean score: {} (+/-{})".format( np.mean (scores), sem(scores)))
構文としてはこんな形。
例によってsklearnからcross_val_score,kFoldをインポート。
そしてdef evaluate_cross_validation(clf,x,y,K)でそれぞれの引数は
clf→機械学習アルゴリズム
x→説明変数
y→目的変数
K→データを何分割するかの指定
という構文らしいです。
グリッドサーチ
交差検証はモデルの汎化性能を測定する方法でした。
それに対してグリッドサーチは、学習モデルに用いられるハイパーパラメータを調整していき、モデルの汎化性能を向上させる方法を探す代表的な手法です。
グリッドサーチでは、指定したハイパーパラメータの全ての組み合わせに対して学習を行い、もっとも良い精度を示したパラメータを採用していきます。
ハイパーパラメータとは、SVCでのカーネルのバンド幅gamma、正則化パラメータCなどのことで人が調整する必要のあるパラメータのことをハイパーパラメータと呼びます。このパラメータはモデルの性能に大きく影響を与えます。
例えば、ハイパーパラメータであるgammaとCにそれぞれ0.001, 0.005, 0.1, 1, 5などと当てはめて、モデルの汎化性能を試してみるだけで、5×5=25通りのハイパーパラメータの組み合わせがありますが、それら全ての中で汎化性能の一番良いものを採択します。
グリッドサーチはScikit-learnを用いて実装できます。
ハイパーパラメータなるものがあって最適なものを採用するためのものがグリッドサーチ。
そしてコイツもScikit-learnで実装するらしい。すごいなScikit-learn…
Python 自作関数のモジュール化 15m …
独自で作成したモジュールをインポートする
def get_fortune():
import random # randamではなく、randomなので注意です
results = ['大吉', '吉', '小吉', '凶', '大凶', '末吉']
return random.choice(results)
こちらのファイルをfortune.pyのファイル名でアップロード。
random.choiceがリストの中からランダムで1つの要素を選択するモジュールなのかな。
今回学習するのはこういう「別で作ったモジュール」をインポートして使う方法みたいです。
import fortune
result = fortune.get_fortune()
print("今日の運勢は... ", result)
こんな形で、ファイル名.pyで保存されてるものは
import ファイル名
で使えるようになりますよ、というデモンストレーションでした。
モジュールをインポートする時は別の名前をつけることもできて
import fortune as ft
result = ft.get_fortune()
print("今日の運勢は... ", result)
というふうに as 別名で指定。
numpyはだいたいnpって名前でインポートされてるのでその時もこの書き方でよさそうです。
Jupyter Notebook入門 20m …
pipを用いたパッケージ管理 15m …
こちらの2つのコースはPCにPythonの環境整えるための記事でした。
諸事情により本体設定をいじることができない環境でこちらの学習を進めているので
この辺は後ほど本格的に運用を始める際に見てみようと思います。
NumPy入門 45m …
さあ来ました。ここまでさんざん見てきたnumpyさんと改めて対面していきます。
対戦よろしくお願いします。
NumPyとは
NumPy(ナムパイ/ナンパイ / Numerical Python)はPythonで数値計算を効率的に行うためのライブラリです。
NumPyは、この次のテキストにて説明する、Pandas、MatplotlibなどのPythonのライブラリと合わせてよく利用されます。
NumPyを使うことでベクトル(1次元配列)や行列(2次元配列)などの多次元配列を作ることができます。
そのため、データ解析では必須と言っても良いほど、よく利用するライブラリになります。
なぜNumPyを学ぶのか
なぜNumPyを学ぶのかについてあらかじめ説明します。
NumPyは機械学習・ディープラーニングを扱う機械学習エンジニア(Pythonエンジニア)に取って、必須のライブラリといっても良いくらい多く利用します。
NumPyは大規模なデータの処理に優れており、機械学習・ディープラーニングの現場で多く使います。
そのためNumPyは機械学習エンジニアにとって「最初の一歩」となるライブラリですので、是非この章でしっかり基礎を学んでいきましょう。
配列(アレイ)を作る
import numpy as np
x = np.array([1.0,2.0,3.0,4.0,5.0])
print(x)
# [1. 2. 3. 4. 5.]
my_list1=[1,2,3,4,5]
my_array1=np.array(my_list1)
print(my_array1)
# [1 2 3 4 5]
my_list2=[10,20,30,40,50]
my_list3=[my_list1,my_list2]
print(my_list3)
# [[1, 2, 3, 4, 5], [10, 20, 30, 40, 50]]
my_array2=np.array(my_list3)
print(my_array2)
# [[ 1 2 3 4 5]
# [10 20 30 40 50]]
リストにリストを追加しても出したいような2列のリストにはならないけどarrayを使うと
2列×5行のリストにすることができると。
NumPy配列の形状を調べる
NumPy配列(ndarray)の形状を調べるにはshapeというインスタンス変数を使うことで調べることができます。
import numpy as np
a = np.array([1, 2, 3, 4])
print(a.shape) # (4,)が出力される。これは1次元配列でかつ、4つ要素があることを意味します。
b = np.array([[1, 2],[3,4]])
print(b.shape) # (2, 2) これは行列で、2行2列を意味しています。
インスタンス名.shapeでそのインスタンス(ndarray)の形状を出すことができる。
1行だけのデータならただ要素がいくつかあるかだけ出力されるが行列であれば行数と列数を出力してくれる。
データ型の指定
NumPy配列を作成する時に、array()の引数dtypeにデータ型を指定すると、全ての要素が指定したデータ型に揃えられます。
import numpy as np
# float32は、32ビットの浮動小数点数
ary = np.array([1, 2, 3], dtype='float32')
ary.dtype # dtype('float32')
arrayの引数でdtype=型名とすることで出力される配列のデータ型を指定可能。
数値型の中でもfloatなのかintなのかを指定する時に使うことになりそう。
配列の生成 arange()と配列操作
arange()はpythonのfor文で使ったrange()関数と似た関数です。
range()同様に引数に渡した数の配列を生成します。
import numpy as np
x = np.arange(10)
print(x)
x = np.arange(1, 10).reshape(3,3) # 3×3の多次元配列に変換
y = np.arange(1, 10).reshape(3,3) # 3×3の多次元配列に変換
print(x)
print(y)
print(x + y)
print(x - y)
print(x * y)
#[0 1 2 3 4 5 6 7 8 9]
#[[1 2 3]
# [4 5 6]
# [7 8 9]]
#[[1 2 3]
# [4 5 6]
# [7 8 9]]
#[[ 2 4 6]
# [ 8 10 12]
# [14 16 18]]
#[[0 0 0]
# [0 0 0]
# [0 0 0]]
#[[ 1 4 9]
# [16 25 36]
# [49 64 81]]
np.arrange(x)で0からx-1までの配列を作成してくれる。
range()と同様にnp.arrange(x,y)でxからy-1までの配列の作成も可能。
ブロードキャスト(Broadcasting)
ブロードキャストは、配列の大きさが異なっていれば、自動的に要素をコピーし大きさを揃えるNumPyの機能です。
つまり要素が一致しなかった際に、自動で補ってくれます。
import numpy as np
sample_array = np.arange(10)
print(sample_array)
print(sample_array + 5)
#[0 1 2 3 4 5 6 7 8 9]
#[ 5 6 7 8 9 10 11 12 13 14]
モジュールとして、とかではなくデフォルトの機能としてこんなものがついているらしい。
もうこの時点で新卒時代の自分よりも賢い
配列の形状取得
import numpy as np
n1 = np.array([1,2,3,4,5])
print(n1) # [1 2 3 4 5]
np.ndim(n1) # 1
n1.shape # (5,)
n2 = np.array([[1,2], [3,4], [5,6]])
print(n2)
print(n2.ndim) # 2
ndimが次元数の取得、shapeが形状を取得してくれる関数。
4日目の感想
numpyは思ってたよりもシンプルな内容にとどまっていてサクッと終わりました。
ここで紹介されているのはほんの一部だと思いますが、機械学習の部分で使うというよりはその前段階のデータ処理のところで使うライブラリなのかなと思います。
scikit-learnが機械学習の部分で使うライブラリな気配を感じたので覚悟を持って臨もうと思います。
その前に明日は機械学習のための数学があるので多分泣きそうになってますが…
明日も頑張れ