DBマイグレーションとは
アプリケーション開発や機能追加の際には、
機能追加に応じて追加で管理が必要になったデータを保存することや、パフォーマンスを改善するなど、目的に沿ってDBの状態を適切に修正する必要が度々出てきます。
これをスキーマ変更といい、スキーマ変更をDBに対して適用することをDBマイグレーションといいます。
例えば、以下のような変更が挙げられます。
-
テーブルの追加
CREATE TABLE order_history ( id INT AUTO_INCREMENT PRIMARY KEY, user_id INT, product_id INT, order_date DATETIME, quantity INT ); -
カラムの追加
ALTER TABLE users ADD COLUMN phone_number VARCHAR(20); -
カラムのデータ型変更
ALTER TABLE orders MODIFY COLUMN order_date DATETIME; -
カラムの削除
ALTER TABLE products DROP COLUMN description; -
インデックスの追加
CREATE INDEX idx_user_email ON users (email); -
制約(CONSTRAINT)の追加
ALTER TABLE users ADD CONSTRAINT chk_age CHECK (age >= 18);
特に、すでに運用中で実データが存在するDBに対して上記のような変更を適用するとき、その手段はプロジェクトやチームごとに様々です。
今回は、DBマイグレーションの手段および、各手法のメリットデメリット、どのような時に適しているかを考えていきたいと思います。
知見を集めたいため、ご意見があればぜひコメントをいただけるとありがたいです。
DBマイグレーションは何が難しいのか
最初に、DBマイグレーションの難しい点・考慮すべき点を考えます。
次項で、DBマイグレーション手法とその利点を挙げ、ここで挙げられた課題をどのように解決することができるかを考えます。
1. 変更に時間がかかる場合がある
中規模ほどのアプリケーションの変更(デプロイ)は、長くても数分〜十数分程度で完了することが多いかと思います。
それに対して、巨大テーブルへの変更がある場合、数時間〜日付単位で時間がかかる場合があります。
ここで考えるのは以下のうち2のパターンです。
- メタデータのみ変更するDDL(カラム名変更、インデックス削除、ビュー作成など)・・・通常、瞬時に終了するため問題なし
- 既存データのコピーを伴うDDL(カラム追加、削除、インデックス追加、PK追加など)・・・データ量に依存して実行時間がかかるため注意が必要
例えば、カラム追加の場合は以下のように処理が進みます。
この時、実行中に既存テーブルの更新がロックされます。
テーブルが巨大であればあるほどロック時間が長くなり、アプリケーションの継続に支障が出る可能性があります。
※ちなみにMySQLでは以下のようにオンラインDDL(更新をロックせずにスキーマ変更)の実行が可能です。
例・・・主キーの削除および別の主キーの追加
この変更は非常にコストのかかる操作ですが、同時DMLが許可されます。
ALTER TABLE *tbl_name* DROP PRIMARY KEY, ADD PRIMARY KEY (*column*), ALGORITHM=INPLACE, LOCK=NONE;
2. プロジェクトによってバージョン管理の方法が異なる
アプリケーションのバージョン管理にはGitを使う場合が多いと思います。
一方、DBマイグレーションの場合は、マイグレーションツールを使うのか、その中でもどのツールを使うのか、
または、生SQLをGitで管理 + どこまで変更を適用したかの記録を別途管理するのかなど、さまざまな手法が考えられます。
そして、プロジェクトによって優先度を上げるべき考慮事項が異なるため、適した手法も異なります。
3. データ損失のリスク
考慮不足や誤ったSQLの実行により、データを失う場合があります。
対策としては、事前にバックアップを取ったり、以前のバージョンへの切り戻し手順を決めておくことや
テスト環境での実行・動作確認をすることが重要です。
4. CI/CDによるデプロイ・マイグレーション実行順による障害
CI/CDでデプロイとマイグレーションを両方実行するパターンでは注意が必要な場合があります。
例えば以下の記事では、
デプロイ・マイグレーションの実行順が適切でないことにより障害が発生した事例と、その対応策が紹介されています。
今回の障害はデータベースのマイグレーションとソースコードのデプロイが同一ワークフローにあり
ソースコードのデプロイより先にデータベースのマイグレーションを実行してしまったのが原因でした。
- データベースのマイグレーションが実行される(テーブルが削除される)
- 存在しないテーブルにアクセスしようとする(障害発生)
- ソースコードがデプロイされる(復旧)
上記の課題を解決したい
個人的には、
- 作業工程が少なく
- 誰がやっても過程・結果が同じになる
- 失敗した、問題が発生した際に前の状態に戻せる
- できればアプリ無停止
を重視したい
マイグレーション手法
マイグレーション手法を比較していきます。
1. 生SQL
弊社では現在、この手法を採用しています。
- マイグレーション用のsqlファイルを作成し、ローカル環境で実行・動作確認
- PR〜レビューを実施
a. 機能開発と同時に実施する際など、場合によってはレビュー前にテスト環境へ反映して動作確認することもあります - レビュー通過後、本番環境に入ってsqlを実行し、反映する
メリット
- 時間がかかりすぎた時にストップできる
- 場合によって必要な手順が異なっているときも柔軟に対応できる
2. マイグレーションツール
フレームワーク
代表的なフレームワークには、マイグレーション機能が付属しているものもあります。
新たに別のツールを導入する必要がなく、事例も探しやすいのが利点です。
以下の例では生のSQLを書く必要がなく、PHPやRubyで作成されたDSLを利用してテーブルの変更を記述できます。
Laravel
Artisanコマンドを利用してマイグレーションすることができます。
$ php artisan make:migration create_flights_table
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
return new class extends Migration
{
/**
* マイグレーションの実行
*/
public function up(): void
{
Schema::create('flights', function (Blueprint $table) {
$table->id();
$table->string('name');
$table->string('airline');
$table->timestamps();
});
}
/**
* マイグレーションを戻す
*/
public function down(): void
{
Schema::drop('flights');
}
};
アプリケーション開発が続くと、マイグレーションファイルが蓄積してファイル数が膨大になりますが、
Laravelではこれらのファイルを単一SQLファイルに圧縮する機能もあるため便利です。
Ruby on Rails
Active Recordの機能の一つとして、マイグレーションが利用できます。
$ bin/rails generate migration CreateProducts
# db/migrate/20240502100843_create_products.rb
class CreateProducts < ActiveRecord::Migration[7.2]
def change
create_table :products do |t|
t.string :name
t.text :description
t.timestamps
end
end
end
Railsは、DBスキーマの最新状態を取得し、db/schema.rbファイルを作成します。ただしこのファイルでは一部のDB固有項目が表現できない弱点があります。
そこで、スキーマフォーマットに:sqlを指定することで、DB固有のツールを用いて、db/structure.sqlにダンプを取得することも可能です。
専用ツール
pressly/goose
参考: https://developers.cyberagent.co.jp/blog/archives/41187/
Go製のDBマイグレーションツールです。
先に挙げたフレームワーク付属のマイグレーションツールと同等の機能も持っています。
-- +goose Up
CREATE TABLE post (
id int NOT NULL,
title text,
body text,
PRIMARY KEY(id)
);
-- +goose Down
DROP TABLE post;
上記ファイルを用意した上で以下コマンドを実行することで更新および切り戻しが可能です。
$ goose up
$ goose down
Goでも書ける
package migrations
import (
"database/sql"
"github.com/pressly/goose/v3"
)
func init() {
goose.AddMigration(Up, Down)
}
func Up(tx *sql.Tx) error {
_, err := tx.Exec("UPDATE users SET username='admin' WHERE username='root';")
if err != nil {
return err
}
return nil
}
func Down(tx *sql.Tx) error {
_, err := tx.Exec("UPDATE users SET username='root' WHERE username='admin';")
if err != nil {
return err
}
return nil
}
実行
$ go run main.go -dir ./path/to/file dbuser:dbpassword@tcp(123.4.5.6:3306)/dbname up
どこまで実行したか等も調査できます。
$ goose status
$ Applied At Migration
$ =======================================
$ Sun Jan 6 11:25:03 2013 -- 001_basics.sql
$ Sun Jan 6 11:25:03 2013 -- 002_next.sql
$ Pending -- 003_and_again.go
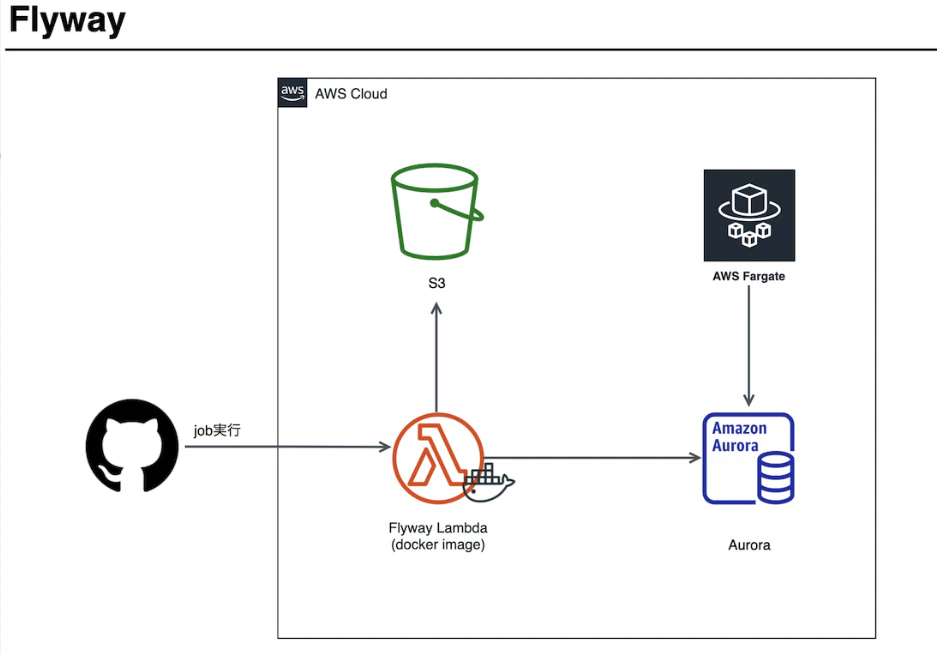
Flyway
基本的なマイグレーションだけでなく、プロジェクト中のSQLがDBに適用されているかどうかを調べるなども可能です。
こちらの記事で導入事例が紹介されています。GitHub Actionsとの組み合わせで、自動マイグレーションが実現されています。
GitHubジョブ実行からFlyway実行終了までのフローは下記の通りです。
- GitHubジョブから実行用のファイルをS3にアップロード
- Payload(JSON)から必要なパラメータを抽出
- AWS CLIを利用し、Flyway実行に必要な情報を抽出
- S3バケットからSQLを含むzipファイルを取得
- Flyway実行(Lambda上のDocker imageで)
- 結果をS3バケットに配置
Dbmate
マイグレーション後に、現在のschema dumpを取得できます。テスト用に空のDBを作りたい場合などは便利です。
メリット
- バージョン管理の自動化
- dumpの自動取得など便利機能
- 問題発生時の以前のバージョンへのロールバック
3. CI/CDで自動実行
以下で実施方法の事例が紹介されています。1または2との組み合わせとなると思います。
- featureからstagingブランチへのマージ時にGitHub Actionsを起動する
- Dry-runとmigrationジョブの間に手動承認フェーズを入れる
- stagingブランチをproductionブランチにマージし、GitHub Actionsを起動、productionにも反映
メリット
- Codebuild上でGitHub Actionsを動かすことで、RDSへの接続などセキュアなパイプラインを構築できる
- GitHub Acitonsワークフローファイルを利用できる
- ホストランナーの実行コンピューティングにLambdaを選択可能
生のSQL vs マイグレーションツール
各マイグレーションツールおよび、生のSQLでできることはそれほど大きく変わりません。(生SQLが最もなんでもできますが)
基本的に何に重きを置くかによって採用すべき手法は変わります。
最後に、上記の課題を解決したいに記載した4つの優先事項について、それぞれの方法が適しているか考えていきます。
- 作業工程が少なく
- 誰がやっても過程・結果が同じになる
- 失敗した、問題が発生した際に前の状態に戻せる
- できればアプリ無停止
1. 作業工程が少ない
マイグレーションを実施する手順は、生SQLでもツール利用でもCI/CD等で自動実行しない限り手作業が入るため、
複雑さは変わらないと考えられます。
どちらかといえばツールを利用することで、自動的にdumpが取れるなどするためコマンド実行回数は減るかもしれません。
2. 誰がやっても過程・結果が同じになる
ツールによって実行するコマンドや用意するファイルが異なるため、キャッチアップが楽なものでいいと思います。
特に生のSQLを利用する場合は、手順を明文化しておくことが重要となるでしょう。
3. 失敗した、問題が発生した際に前の状態に戻せる
こちらは生のSQLに軍配が上がりそうです。
マイグレーション内容が間違っていた場合に関しては、ツールでもロールバック機能があるため戻すことができます。
また、実行が終わらない場合は以下のようにクエリのプロセスIDを調べ、強制終了することが可能です。
AWS RDSを利用している場合、パフォーマンスインサイトで高負荷なクエリを確認できるので調査がしやすくなります。
$ SHOW PROCESSLIST;
$ KILL QUERY <process_id>;
ただし、ツールを利用しても生SQLでも、実行が終わらないクエリを強制終了することで
中途半端なマイグレーションが残る場合があります。
このような状態を修正するには、生SQLの方が柔軟に対応できるでしょう。
ちなみにMySQLの場合、KILLした場合は強制終了フラグが立ち、一時テーブルが掃除されます。
テーブルのコピーを作成する
ALTER TABLE操作では、元のテーブルから読み取られたいくつかのコピーされた行について、強制終了フラグが定期的にチェックされます。 強制終了フラグが設定されていた場合、このステートメントは中止され、一時テーブルが削除されます。
https://dev.mysql.com/doc/refman/8.0/ja/kill.html
戻せないマイグレーションは?
全てのマイグレーションが元に戻せるとは限りません。
このような場合も別途スクリプトを実行するなど、その時々の対応が必要となるため生SQLが柔軟な対応が可能でしょう。
例えば、not nullなカラムをnullableに変更し、nullを含むデータを投入するマイグレーションを実行した場合を考えます。
この時、ロールバックしてnot nullなカラムに戻す際に、すでにnullのデータが含まれるため失敗します。
ツールを利用する場合の例を示します。
RailsのActive Recordの場合は、以下のマイグレーション実行後、
class ChangeColumnToNullable < ActiveRecord::Migration[6.0]
def up
change_column :users, :email, :string, null: true
# ここで null を含むデータを投入したと仮定
User.create!(name: 'John Doe', email: nil)
end
def down
change_column :users, :email, :string, null: false
end
end
以下のようなスクリプトでnullのデータを修正したのちに、rails db:rollbackを実行します。
namespace :data_fixes do
desc "Nullのemailカラムをデフォルト値に修正"
task update_null_emails: :environment do
User.where(email: nil).update_all(email: '') # ここで''に戻す
puts "Nullのemailカラムを更新しました。"
end
end
または、downメソッドで以下のように記述し、元に戻せないマイグレーションであることを明示しておきます。
def down
raise ActiveRecord::IrreversibleMigration
end
どちらにせよ、実行前にテスト環境でのチェックやレビューは確実に行っておきたいですね。
4. できればアプリ無停止
長時間かかることが予測される場合、あらかじめメンテナンス期間を設けることで安全にマイグレーションを実施することができます。
しかし、ユーザー体験を損なわないためにも、可能であればアプリケーションを無停止のまま実施したいところです。
場合によりますが、実行手順を工夫することで、ツールでも生SQLでも対応可能です。
以下に無停止でのマイグレーションの例を1つ紹介します。
ストラングラーフィグパターン
移行を一度で行うのではなく、段階的に実施する方法です。
commentsテーブルのマイグレーションを実施する手順は以下のとおりです。
- 移行前のcommentsテーブルのみ存在している
- commentsテーブルと移行後のv2_commentsテーブルを共存させる
- アプリケーションを修正し、それぞれのテーブルにwrite処理を実行する。readは旧テーブルに対して行う
- 徐々にreadを新テーブルに移す。writeは両テーブルのまま
- 全てのread、writeを新テーブルに移す
詳しくは以下の記事で事例が紹介されています。
CI/CDの利用
上記の1〜4はCI/CDと組み合わせることで、属人化を防ぎ手順と結果に一貫性を持たせることができます。
ただし、実際に本番環境で実施した際に問題が発生した場合、即座に修正や中止の対応が取れるとは限らないことや、
実行に時間がかかった場合のコスト増大など新たな課題が発生するため入念な検証が必要となるでしょう。