ローカル完結で「ずんだもんと声で会話できる」AI スタック AIzunda
ブラウザのマイクを押すと、ローカルだけで動く LLM がずんだもんの声で返事をしてくれて、VRM がリップシンクで口パクする ―― そういう「音声 → STT → LLM → TTS → VRM」のパイプラインを 1 台のマシンで完結させる試みです。
クラウド API は一切呼ばず、AMD Ryzen AI Max+ 395 + ROCm のワンマシンで動かすことを前提にしています。GitHub リポジトリは kotetsuy/AIzunda にあります。
長文応答でも初音まで約 1 秒になるよう、Qwen3 の thinking 抑制と LLM→TTS のパイプライン化を入れているのが地味なポイントです。
こちらは動画です。
前半:git clone してから動かすまで
動作確認済みの環境
| 項目 | 値 |
|---|---|
| OS | Ubuntu 24.04.4 LTS |
| GPU | AMD Ryzen AI Max+ 395 / Radeon 8060S (gfx1151、48GB VRAM) |
| ROCm | 7.2.1 (/opt/rocm) |
| Python | 3.12.3 |
| Docker | 29.x(VOICEVOX 用) |
| ブラウザ | Google Chrome(Firefox でも可) |
| その他 | tmux / curl(起動スクリプトで使用) |
ROCm 対応 AMD GPU + Ubuntu 24.04 の組み合わせを想定しています。NVIDIA / CUDA で動かす場合は WHISPER_DEVICE=cuda のままで OK ですが、HSA_OVERRIDE_GFX_VERSION 系の環境変数は外してください。
1. リポジトリと外部依存を取得
# 本リポジトリ
git clone https://github.com/kotetsuy/AIzunda.git ~/AIzunda
cd ~/AIzunda
# llama.cpp(ROCm/HIP ビルド)
git clone https://github.com/ggerganov/llama.cpp.git ~/AIzunda/llama.cpp
# WhisperX-ROCm(STT)・CTranslate2-ROCm を ~/AIzunda 直下に配置
# (それぞれ各プロジェクトの README に従ってビルド)
~/AIzunda 以下に揃えるディレクトリ構成は次のとおりです。
~/AIzunda/
├── llmtvoice/ # パイプライン総合ドキュメント
├── three-vrm/ # VRM ビューア + VOICEVOX 中継 (aiohttp)
├── ttllm/ # WhisperX ↔ llama.cpp ブリッジ (FastAPI)
├── voicevox/ # VOICEVOX Docker 起動の手順 / テスト
├── vtt/ # CLI PTT クライアント (任意)
├── start_all.sh # 一括起動
├── stop_all.sh # 一括停止
├── llama.cpp/ # ← 自分で git clone & ビルド
├── qwen3.6/ # ← GGUF モデルを置く
├── whisperx-rocm/ # ← WhisperX-ROCm の venv
└── zundavrm/VRM/ # ← VRM ファイルを置く
各サブモジュールの README は GitHub 上で個別に確認できます:
READMEJ.md(全体)llmtvoice/READMEJ.md(総合パイプラインドキュメント)ttllm/READMEJ.mdthree-vrm/READMEJ.mdvoicevox/READMEJ.mdvtt/READMEJ.md
2. llama.cpp を ROCm でビルド
~/AIzunda/llama.cpp で HIP 対応ビルドを行います(詳細は llama.cpp 本体の手順に従ってください)。最終的に ~/AIzunda/llama.cpp/build/bin/llama-server が出来ていれば OK です。
その上で Qwen3.6-35B-A3B の GGUF を ~/AIzunda/qwen3.6/Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf に置きます。
3. WhisperX-ROCm(STT)の venv を作る
WhisperX 本体は別リポジトリの ROCm フォークを使います。~/AIzunda/whisperx-rocm/.venv に WhisperX / torch-ROCm 2.9 / ctranslate2-rocm / faster-whisper / pyannote.audio を入れた venv を作ります(llmtvoice/READMEJ.md の「セットアップ」節参照)。
4. ttllm ブリッジの依存を venv に追加
cd ~/AIzunda/ttllm
./install.sh
ttllm/install.sh は WhisperX の venv に fastapi / uvicorn / httpx / python-multipart / pydantic を追加するだけのスクリプトです。
5. VOICEVOX を Docker で取得
docker pull voicevox/voicevox_engine:cpu-ubuntu20.04-latest
docker run -d --name voicevox_engine --restart unless-stopped \
-p 50021:50021 voicevox/voicevox_engine:cpu-ubuntu20.04-latest
curl -s http://localhost:50021/version # 起動確認
ROCm との VRAM 競合を避けたいので CPU イメージを使っています。短文ならこれでも十分リアルタイムです。
6. VRM モデルを配置
~/AIzunda/zundavrm/VRM/Zundamon_2025_VRM10A.vrm にずんだもん VRM 1.0 モデルを置きます。別ファイル名にしたい場合は three-vrm/server.py の VRM_DIR と、ブラウザ側 zundamon.html の VRM_URL を揃えてください。
7. 一括起動
ここまで来れば、あとは 1 コマンドです。
~/AIzunda/start_all.sh
start_all.sh は tmux セッション aizunda を作って、各サービスを別ウィンドウで走らせます。
| window | コマンド |
|---|---|
| 0 voicevox | docker logs -f voicevox_engine |
| 1 llama | llama-server -m Qwen3.6... --port 8080 -ngl 99 -c 8192 |
| 2 ttllm |
ttllm/run.sh (uvicorn) |
| 3 three-vrm | python3 three-vrm/server.py |
| 4 vtt |
vtt/run.sh --device USB (CLI PTT、任意) |
起動順序は依存関係に合わせて直列化してあり、各段で HTTP health check を待ちます(llama-server だけタイムアウト最大 600 秒)。ttllm が立ち上がった直後に /warmup を叩いて WhisperX を先読みするので、最初の発話が遅くなりません。
ログを覗くには:
tmux attach -t aizunda
全部止めるには:
~/AIzunda/stop_all.sh
# VOICEVOX のコンテナだけ残したいときは
~/AIzunda/stop_all.sh --keep-voicevox
stop_all.sh は tmux セッションと VOICEVOX コンテナを止めます。
8. ブラウザで使う
start_all.sh が自動で Chrome を開きます(http://localhost:8000/zundamon.html)。
- 画面を一度クリック して AudioContext を有効化(ブラウザの user-gesture 要件)
- 右下の 🎤 ボタン
- 長押し(≥ 250ms): 押している間だけ録音、離すと送信
- 短クリック: 録音開始 → もう一度クリックで送信
- ユーザー発話は薄青の字幕、ずんだもんの返答は白の字幕で出ます
CLI から動作確認するなら:
# 各サービス疎通
curl -s http://localhost:50021/version
curl -s http://localhost:8080/health
curl -s http://localhost:8001/health
# テキスト → VOICEVOX → ブラウザで口パク
curl -X POST http://localhost:8000/speak \
-H 'Content-Type: application/json' \
-d '{"text":"こんにちはなのだ","speaker_id":3}'
# 音声ファイル → 文字起こし + LLM 応答 + 合成 + 口パク
curl -X POST http://localhost:8000/voice_chat_speak \
-F "audio=@sample.wav" -F "speaker_id=3"
後半:ブロック図とテクノロジー詳細
全体ブロック図
ブラウザ → three-vrm サーバ → ttllm ブリッジ → (WhisperX + llama-server) → VOICEVOX → ブラウザ という 5 段構成です。点線が WS による音声 + viseme のブロードキャストで、ここがリップシンクの入力になります。
AIzunda パイプライン全体
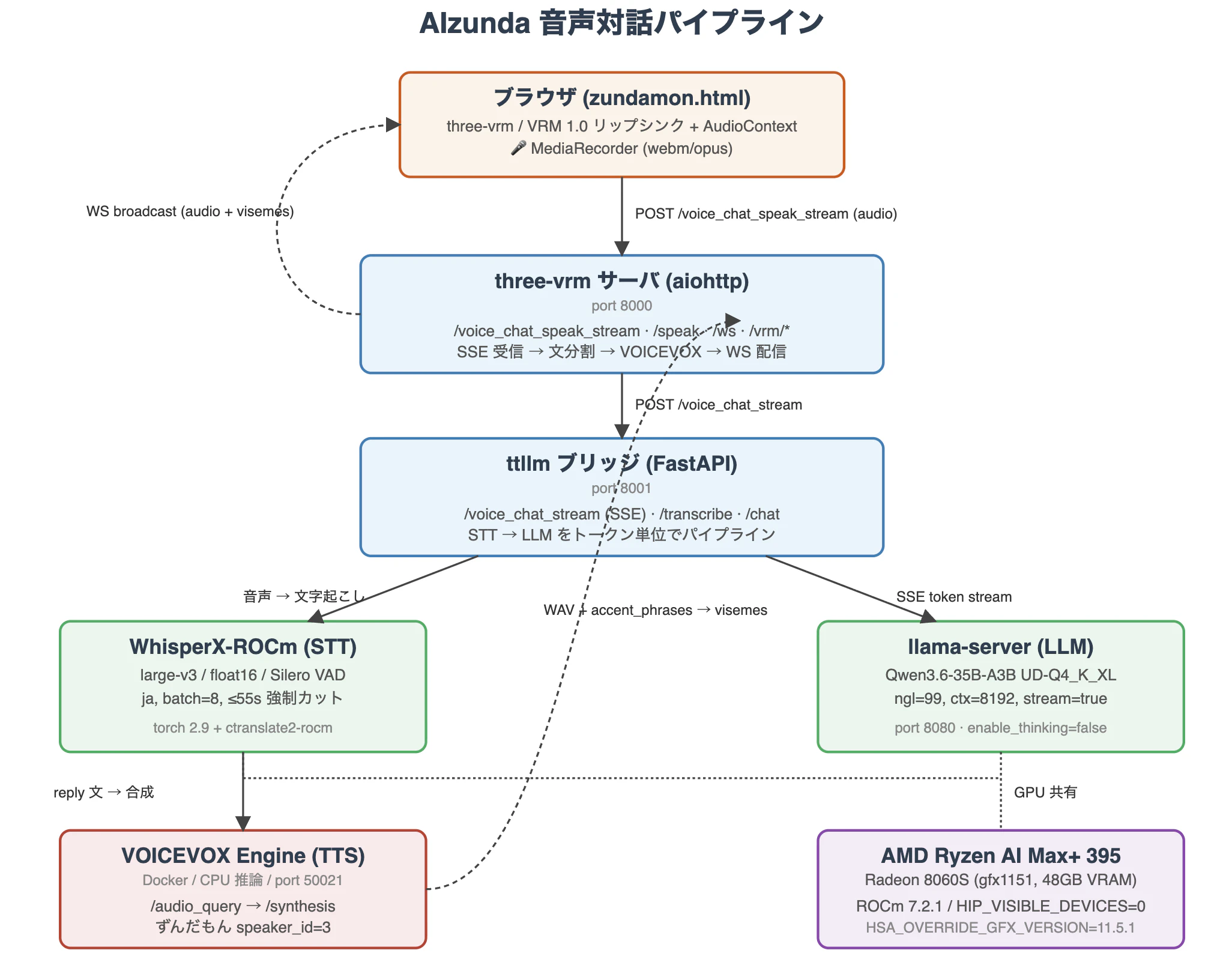
ブラウザ (three-vrm)
└─ マイク録音 (MediaRecorder webm/opus)
↓ POST /voice_chat_speak_stream
three-vrm サーバ (port 8000)
↓ POST /voice_chat_stream
ttllm ブリッジ (port 8001)
├─ WhisperX-ROCm (STT, large-v3)
└─ llama-server (Qwen3.6-35B-A3B, port 8080)
↓ SSE で token ストリーム
three-vrm: 文境界で分割 → VOICEVOX (port 50021) → WS 配信
↓ WS (audio + visemes)
ブラウザ: AudioContext 連続再生 + VRM リップシンク + 背景 + idle motion
各サービスの役割とポートをまとめると次のとおりです。
| パス | 役割 | ポート |
|---|---|---|
voicevox/ |
VOICEVOX Engine(Docker, CPU 推論) | 50021 |
~/AIzunda/llama.cpp/build/bin/llama-server |
Qwen3.6 推論 | 8080 |
qwen3.6/Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf |
LLM モデル | — |
ttllm/ |
FastAPI ブリッジ(WhisperX + llama.cpp) | 8001 |
three-vrm/ |
aiohttp サーバ + VRM ビューア(HTML/three-vrm) | 8000 |
vtt/ |
CLI PTT マイク(任意) | — |
images/ |
VRM ビューア背景(5 分ごとにローテーション) | — |
zundavrm/VRM/Zundamon_2025_VRM10A.vrm |
ずんだもん VRM 1.0 モデル | — |
whisperx-rocm/ |
WhisperX の ROCm フォーク | — |
採用テクノロジー
| 段 | 採用 | 理由 |
|---|---|---|
| STT | WhisperX-ROCm + Silero VAD | 単一プロセスで VAD・転写・(必要なら)強制アライメントまで完結。ROCm 上で float16 が出る |
| LLM | llama.cpp(llama-server) + Qwen3.6-35B-A3B UD-Q4_K_XL | OpenAI 互換 API + SSE。MoE で 35B 級でも GPU 1 枚に乗る |
| TTS | VOICEVOX(CPU Docker) | accent_phrases から moras が取れ、リップシンク用 viseme に変換しやすい |
| アバター | @pixiv/three-vrm(VRM 1.0) |
expressionManager で aa/ih/ou/ee/oh/nn が標準化されている |
| バックエンド | FastAPI(ttllm) + aiohttp(three-vrm) | SSE / WebSocket / multipart の取り回しがそれぞれ素直 |
主要エンドポイント
ttllm(port 8001) — ttllm/server.py
| メソッド | パス | 用途 |
|---|---|---|
| GET | /health |
自身 + llama-server 到達性 |
| POST | /warmup |
WhisperX モデル先読み |
| POST | /transcribe |
音声 → テキスト |
| POST | /chat |
テキスト → LLM 応答(非 streaming) |
| POST | /voice_chat |
音声 → 応答(非 streaming) |
| POST | /voice_chat_stream |
音声 → SSE(transcript + token + done) |
three-vrm(port 8000) — three-vrm/server.py
| メソッド | パス | 用途 |
|---|---|---|
| GET | /zundamon.html |
ビューア |
| GET | /ws |
WebSocket(turn_start / speak / turn_end / transcript / error) |
| POST | /speak |
テキスト指定で発話 |
| POST | /voice_chat_speak |
音声 → ワンショット応答(非 streaming) |
| POST | /voice_chat_speak_stream |
音声 → パイプライン応答 |
| GET | /images_list |
背景画像一覧 |
| GET | /images/{name} |
背景画像配信 |
| GET | /vrm/{name} |
VRM ファイル配信 |
| GET | /status |
クライアント数 |
レイテンシ最適化:初音 3.32 s → 1.06 s
ここが本スタックの実装上の主役です。短い発話(「こんにちは」程度)で体感 1 秒前後、長文応答でも初音 1 秒台を目標にしました。
Before/After 比較

実測値は次のとおりです(8 文応答)。
| 指標 | 改善前(非 streaming) | 改善後(pipeline) |
|---|---|---|
| 初音までの時間 | 3.32 s | 1.06 s |
| 全体完了時間 | 3.32 s | 2.98 s |
1. Qwen3 thinking モードを切る
既定で Qwen3 系は返答前に reasoning_content(内部独白)を数百トークン吐くので、これだけで体感 4〜8 秒くらい遅延します。ttllm から llama-server を叩くときに chat_template_kwargs で無効化しています。
# ttllm/server.py: _call_llama
payload = {
"messages": messages,
"temperature": temperature,
"max_tokens": max_tokens,
"stream": False,
# Qwen3 系は既定で thinking を吐くので chat template 側で切る
"chat_template_kwargs": {"enable_thinking": False},
}
参考: ttllm/server.py
これを渡さないと、reasoning_content 側に数百トークン食われて content が空のまま max_tokens に到達することがあります。
2. LLM → VOICEVOX のパイプライン化
-
ttllm側に/voice_chat_stream(SSE) を追加し、llama-serverをstream: trueで叩く。{transcript}→{token}×N→{done}の順で流す。 -
three-vrm側の/voice_chat_speak_streamがこの SSE を消費し、[。!?\n]で文分割、長文保険として 60 文字超は[、]でも切る。 - TTS は
asyncio.Queue+ consumer task で直列化(WebSocket の順序保証が要るため)。一方で LLM のデコードは並列継続させる。 - クライアントは
turn_startで playhead をリセットし、各speakチャンクをstartAt = max(playheadTime, audioCtx.currentTime)でキュー末尾に連続再生。viseme は絶対時刻でスケジュールするので、複数チャンクでも干渉しない。
3. 新ターン開始時に前の発話を即停止
マイクを押した時点で、クライアントは現在スケジュール済みの全 AudioBufferSourceNode を stop(0) し、viseme キューも消します(stopAllPlayback)。サーバの turn_start 到着を待たないので、体感が即応します。
VOICEVOX → viseme → VRM のリップシンク経路
VOICEVOX の accent_phrases から取れる moras を、VRM 1.0 標準表情 aa / ih / ou / ee / oh / nn にマップしているのがリップシンクの心臓部です。
リップシンクのデータフロー
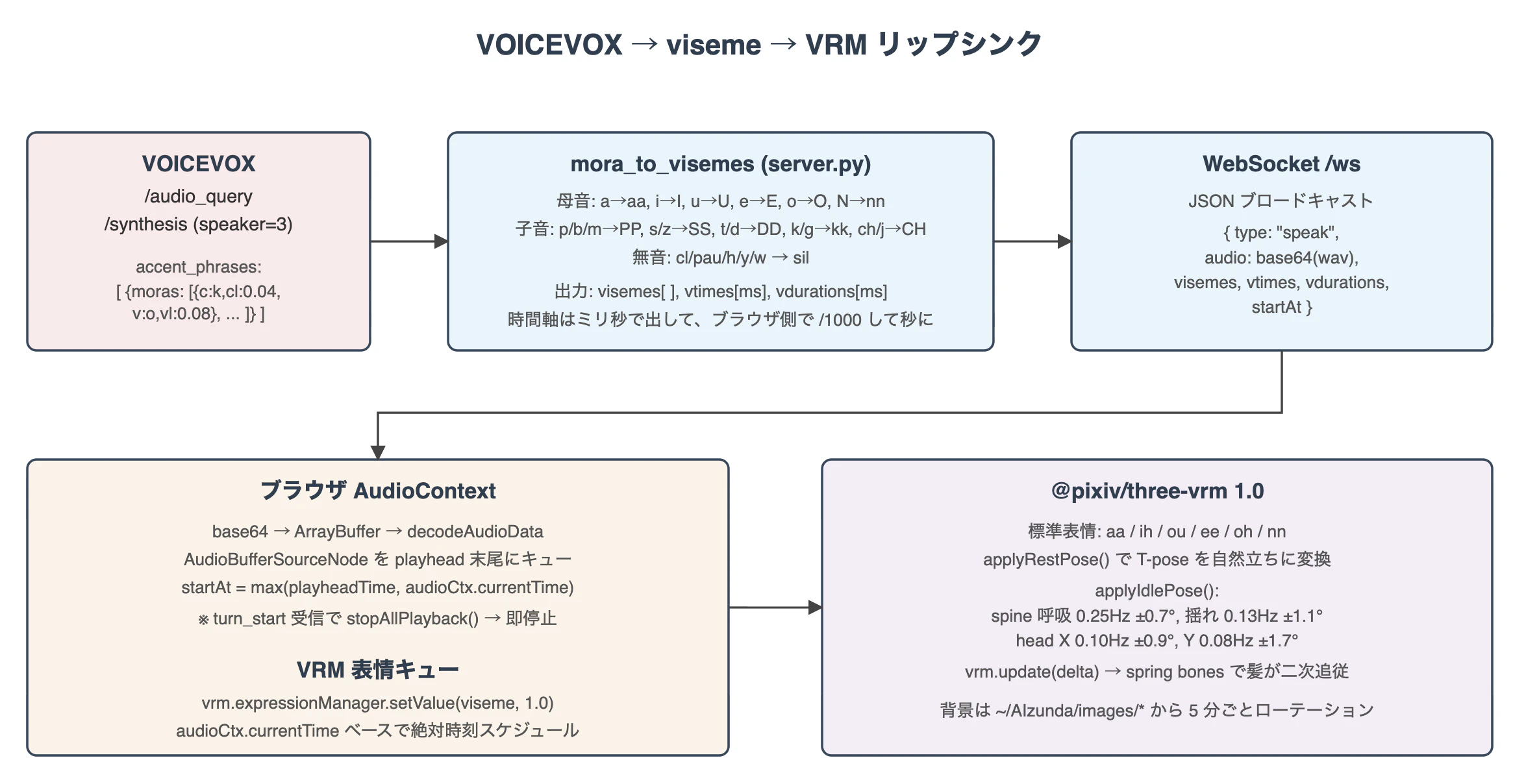
実装は three-vrm/server.py の mora_to_visemes 関数に集約されています。
VOWEL_TO_VISEME = {
"a": "aa", "i": "I", "u": "U", "e": "E", "o": "O",
"N": "nn", "cl": "sil", "pau": "sil",
}
CONSONANT_TO_VISEME = {
"p": "PP", "b": "PP", "m": "PP",
"py": "PP", "by": "PP", "my": "PP",
"f": "FF",
"s": "SS", "z": "SS", "sh": "SS",
"t": "DD", "d": "DD", "ts": "DD",
"k": "kk", "g": "kk", "ky": "kk", "gy": "kk",
"ch": "CH", "j": "CH",
"n": "nn", "ny": "nn",
"r": "RR", "ry": "RR",
"h": "sil", "hy": "sil", "w": "sil", "y": "sil",
}
時間軸はミリ秒でサーバから送り、ブラウザ側で audioCtx.currentTime(秒)と比較するため /1000 変換するのが地味なハマりポイントです(README にもわざわざ書いてある)。
VRM ビューアの演出
背景ランダムローテーション
- 画像は
~/AIzunda/images/*.{jpg,png,webp}を自動検出 -
GET /images_listで一覧、GET /images/<name>で配信 - ページ読み込み時に 1 枚選び、5 分ごとに別画像へランダム切替
- 画像はリポジトリに同梱しません。追加するならディレクトリに放り込むだけで OK(サーバ再起動不要)
Idle モーション
T-pose 棒立ちを避けるため、毎フレーム微小な回転を加えています(zundamon.html:applyIdlePose)。
| 部位 | 周波数 | 振幅 |
|---|---|---|
| spine / chest(X 軸、呼吸) | 0.25 Hz | ±0.7° |
| spine / chest(Z 軸、左右揺れ) | 0.13 Hz(位相違い) | ±1.1° |
| head(X 軸) | 0.10 Hz | ±0.9° |
| head(Y 軸) | 0.08 Hz | ±1.7° |
vrm.update(delta) の前にポーズを当てているので、VRM の spring bones(髪・スカート等)が自然に二次追従します。
両手を下ろす
VRM のデフォルトは T-pose なので、ロード直後に applyRestPose() で両腕を自然立ちの位置に落とし、肘も約 14° 曲げています。
既知の制約
-
WhisperX は 60 秒超で GPU memory fault(ROCm 7.x + PyTorch nightly の既知問題)。
vttは VAD で 55 秒に強制カットして回避しています。ブラウザ側の録音も長尺は避けてください。 -
無音発話で以前 500 エラー が出ていましたが、Silero VAD が "No active speech" を返したときの WhisperX
IndexErrorを_transcribe_pathで捕捉して空文字に落とすように修正済み。 - VOICEVOX は CPU 推論。ROCm との VRAM 競合を避けるための選択。短文なら十分リアルタイム、長文では合成が律速になることがあります。
- Chrome の AudioContext は初回クリック必須(user-gesture 要件)。
-
Qwen3 の thinking は
ttllm経由では常に OFF ですが、llama-serverを直叩きする場合はchat_template_kwargsを自分で付ける必要があります。
トラブルシュート
| 現象 | 対処 |
|---|---|
| マイク を押しても無音 | 画面をクリックして AudioContext を有効化。ブラウザの mic 権限も確認 |
| ずんだもんが喋らない / 500 エラー |
tmux attach -t aizunda で ttllm のログ確認。curl :8001/health で llama 到達性もチェック |
| 初回発話が遅い |
curl -X POST :8001/warmup で WhisperX 先読み |
| 腕の向きがおかしい(VRM 差し替え時) |
zundamon.html:applyRestPose の rotation.z 符号を反転 |
| 背景が切り替わらない | DevTools console で /images_list のレスポンスを確認。画像を置いたらブラウザリロード |
| VRM が読めない |
server.py の VRM_DIR と実ファイルパスを確認 |
| 全部止めたい | ~/AIzunda/stop_all.sh |
拡張の余地
- 会話履歴の保持(現在は毎ターンステートレス、
historyパラメタで渡すだけ) - VRMA 形式の idle アニメ読み込み(現在はプロシージャル)
- VOICEVOX を GPU ビルドに差し替え(長文応答の合成を高速化)
- smaller STT model への切替(medium で 200〜300 ms 短縮可能)
- LLM ストリーミング中の手振りジェスチャ連動
- LLM プロンプトに
<emotion>...</emotion>を出力させ、VRM 1.0 のhappy / sad / angry表情にマッピング
参考・ライセンス
- リポジトリ本体: kotetsuy/AIzunda
- WhisperX: https://github.com/m-bain/whisperX(BSD-4-Clause)
- CTranslate2: https://github.com/OpenNMT/CTranslate2(MIT)
- llama.cpp: https://github.com/ggerganov/llama.cpp(MIT)
- VOICEVOX: https://voicevox.hiroshiba.jp/ (利用規約・キャラクター個別ライセンス要確認)
- three-vrm: https://github.com/pixiv/three-vrm(MIT)
- ずんだもん VRM:
~/AIzunda/zundavrm/Zundamon_vn3license_*.pdf参照
各コンポーネントの README は GitHub 上で個別に読めます。