LLaVA on ROCm — USB カメラ × YOLO11m × Nemotron Nano Omni × Chrome WebRTC
NucBox EVO X2 (Ryzen AI MAX+ 395 / Radeon 8060S, ROCm 7.2.1) 上で USB カメラ映像を Chrome ブラウザに低遅延 WebRTC 配信し、同じ映像に対して YOLO11m の物体検出 (30fps) と Nemotron Nano Omni による日本語キャプション (0.5fps) をリアルタイムオーバーレイするデモ。
必要なもの
| 項目 | 想定値 |
|---|---|
| マシン | NucBox EVO X2 (AMD Ryzen AI MAX+ 395, gfx1151, 48GB unified) |
| OS | Ubuntu 24.04.4 LTS (HWE kernel) |
| ROCm | 7.2.1 (/opt/rocm symlink) |
| Python | 3.12 |
| パッケージ管理 |
uv (ローカル: ~/.local/bin/uv) |
| USB カメラ | UVC 対応のもの 1 台 |
| Chrome | 任意の最近のバージョン (同一マシンまたは LAN 内の別端末) |
事前にインストール済みであることを期待:
-
uv(curl -LsSf https://astral.sh/uv/install.sh | sh) -
tmux(sudo apt install tmux) - ROCm 7.2.1 (https://qiita.com/kotetsu_yama/items/2f5f585f93cb28f6dbe7)
- llama.cpp ROCm/HIP ビルド (
~/llama.cpp/build/bin/llama-serverとllama-mtmd-cliがビルド済み) (https://qiita.com/kotetsu_yama/items/a9cd044f8c695415a18c)
GitHub
セットアップ手順
1. リポジトリ取得
git clone https://github.com/kotetsuy/LLaVA
cd ~/LLaVA
2. Python 仮想環境と基本依存
uv venv
uv sync
これで numpy / opencv-python / pyyaml / pyudev がインストールされ、Step 1 (USB カメラ → SHM) と Step 2 (ホットプラグ対応 CAL) が動く状態になります。
3. ROCm 版 PyTorch (Step 3 以降に必要)
PyPI の torch は CUDA 版なので使えません。AMD の ROCm wheel を直接 wget してインストール:
mkdir -p ~/wheels && cd ~/wheels
wget "https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2.1/torch-2.9.1%2Brocm7.2.1.lw.gitff65f5bc-cp312-cp312-linux_x86_64.whl"
wget "https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2.1/torchvision-0.24.0%2Brocm7.2.1.gitb919bd0c-cp312-cp312-linux_x86_64.whl"
wget "https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2.1/torchaudio-2.9.0%2Brocm7.2.1.gite3c6ee2b-cp312-cp312-linux_x86_64.whl"
wget "https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2.1/triton-3.5.1%2Brocm7.2.1.gita272dfa8-cp312-cp312-linux_x86_64.whl"
cd ~/LLaVA
uv pip install ~/wheels/torch-*.whl ~/wheels/torchvision-*.whl \
~/wheels/torchaudio-*.whl ~/wheels/triton-*.whl
4. YOLO + ONNX (退避プラン用)
uv pip install -e .[yolo,onnx]
ultralytics (YOLO11m を初回 predict 時に自動ダウンロード) と onnx / onnxruntime (CPU 版) が入ります。
5. WebRTC (aiortc + FastAPI)
uv pip install -e .[webrtc]
6. ROCm 環境変数
~/.bashrc などに追加して、新しいシェルで自動的に効くようにしておくと楽:
export HSA_OVERRIDE_GFX_VERSION=11.5.1
export ROCM_PATH=/opt/rocm
export HIP_VISIBLE_DEVICES=0
(start_all.sh は内部で再 export するので、シェル設定を忘れていても tmux セッションでは効きます。)
7. Nemotron Nano Omni GGUF の準備
mkdir -p ~/nemotron-3
cd ~/nemotron-3
# unsloth/NVIDIA-Nemotron-3-Nano-Omni-30B-A3B-Reasoning-GGUF (Q4_K_XL)
huggingface-cli download \
unsloth/NVIDIA-Nemotron-3-Nano-Omni-30B-A3B-Reasoning-GGUF \
NVIDIA-Nemotron-3-Nano-Omni-30B-A3B-Reasoning-UD-Q4_K_XL.gguf \
--local-dir Nemotron-3-Nano-Omni-30B-A3B-Reasoning-GGUF
huggingface-cli download \
unsloth/NVIDIA-Nemotron-3-Nano-Omni-30B-A3B-Reasoning-GGUF \
mmproj-F16.gguf \
--local-dir Nemotron-3-Nano-Omni-30B-A3B-Reasoning-GGUF
合計 ~24.5 GB。config.yaml の vlm.model / vlm.mmproj のパスがこれと一致することを確認してください。
8. (任意) GPU が見えていることを確認
uv run python -c "import torch; print(torch.cuda.is_available(), torch.cuda.get_device_name(0))"
# True AMD Radeon Graphics
起動と停止
一括起動 (推奨)
cd ~/LLaVA
./start_all.sh
これだけで:
- tmux セッション
llavaを作成 - window 0:
uv run capture-run(USB カメラ → SHM、Step 1+2) - window 1:
uv run serve(FastAPI + aiortc + YOLO bbox + VLM caption WS、Step 6+7) - window 2:
llama-server --reasoning off(Nemotron 常駐、Step 7b) -
http://localhost:8080/がレスポンスを返すまで最大 30 秒待機 - Chrome を自動で開く
オプション:
./start_all.sh --no-browser # SSH 越しなどで自動 open 不要なとき
./start_all.sh --help
セッションへの接続:
tmux attach -t llava # ログを直接見る
# Ctrl-b 0 / 1 / 2 で window 切替
# Ctrl-b d でセッションを生かしたまま離脱
停止
./stop_all.sh
各 window に Ctrl-C を送って 5 秒待ち、そのあと tmux kill-session。万一プロセスが残っていれば SIGINT → SIGKILL の段階で後始末します。
ブラウザで確認
./start_all.sh 実行後、Chrome で http://localhost:8080/ (または LAN 内別端末から http://<NucBox の IP>:8080/) を開くと:
- 中央の
<video>に USB カメラ映像 (1280x720, ~150ms 以下の遅延) - 上に半透明
<canvas>で YOLO の bbox (色分け、30fps、person 92%形式のラベル) - 下に半透明ボックスで Nemotron の日本語キャプション (約 50 字、2 秒ごとに更新)
- ステータス行に WebRTC 接続状態 / bbox WS / caption の inference 時間と t/s
llama-server がモデルをロードする最初の ~10 秒は caption が (no caption yet) のまま、その後更新が始まります。
ステップごとの個別実行 (デバッグ用)
start_all.sh を使わず一つずつ起動したいとき:
# Step 1+2: capture
uv run capture-run # 別ターミナル
uv run shm-reader-demo --ticks 10 # SHM 読出しのみ確認
uv run shm-reader-demo --save /tmp/snap.jpg # 1 枚保存
uv run list-cameras # /dev/v4l デバイス一覧
# Step 3: YOLO 単独
uv run benchmark-yolo --source synthetic # synthetic 1280x720 ノイズ
uv run benchmark-yolo --source shm # 上の capture を起動した上で
uv run export-yolo-onnx --verify # ONNX 退避プラン
# Step 4: VLM 単独 (mtmd-cli subprocess)
uv run benchmark-vlm --image /tmp/snap.jpg
# Step 5: YOLO + VLM 同居
uv run benchmark-concurrent --frames 600
uv run benchmark-concurrent --no-vlm # baseline
# Step 6+7: サーバ単体起動
uv run serve # T2 相当
~/llama.cpp/build/bin/llama-server -m ... --mmproj ... --reasoning off # T3 相当
トラブルシューティング
uv run capture-run でカメラが見つからない
ls /dev/v4l/by-id # USB カメラの symlink が出るか
v4l2-ctl --list-devices # (要 sudo apt install v4l-utils)
config.yaml の camera.preferred[].by_id が手元のカメラ名と一致しない場合は fallback: any 経由で適当に選ばれます。特定のカメラを優先したいときは by_id: usb-Vendor_Model* を編集。
connection failed が Chrome に出る
WebRTC の ICE ネゴシエーション失敗。多くは一時的で、Ctrl-Shift-R でハードリロードすれば回復します。LAN 別端末から繋がらない場合は sudo ufw allow 8080 でファイアウォール開放。
caption が空のまま ((no caption yet))
llama-server がまだモデルロード中 (~10 秒) か、--reasoning off を付け忘れたか。tmux attach -t llava → Ctrl-b 1 で serve window のログを確認:
vlm-runner: caption (1300ms) 'これは...' ← OK
vlm-runner: empty caption after strip; raw='<think>...' ← --reasoning off 不足
start_all.sh が「session already exists」で失敗
./stop_all.sh # まず停止
./start_all.sh # 再起動
または tmux kill-session -t llava で強制終了。
モデルロードが極端に遅い (初回 30 秒以上)
21 GB の GGUF を NVMe から SSD にコピー → ページキャッシュに乗せる時間。2 回目以降は ~10 秒に短縮されます。
YOLO の fp16 を fp32 に戻したい
config.yaml の yolo.half: true を false に。fp32 のほうが精度はわずかに上がるが、Step 5 の同居測定で fp16 のほうが VLM 側の余裕が大きくなったので fp16 を採用しています。
開発時のセルフチェック
# 全 Python ファイルの構文チェック
python3 -m compileall -q src scripts && echo OK
# モジュール import 確認 (依存解決の確認も兼ねる)
uv run python -c "from src.server.app import app; print('imports OK')"
技術詳細
このドキュメントは HANDOFFJ.md で示した設計をどう実装したか、なぜその設計を選んだか、そして実装中に判明した落とし穴を体系化したものです。導入手順は READMEJ.md を参照。
1. アーキテクチャ全体像
Pipeline architecture
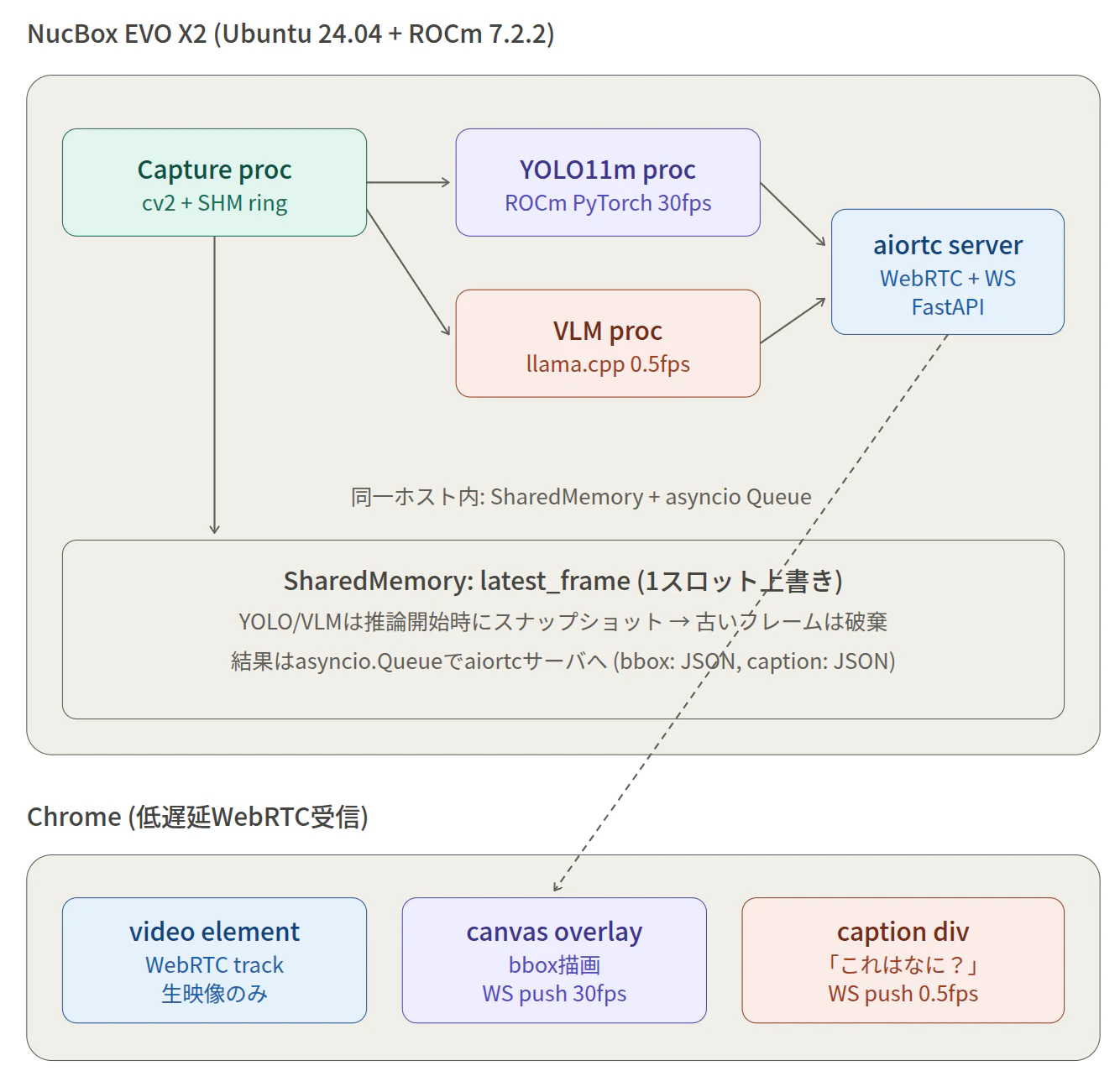
NucBox EVO X2 (Ryzen AI MAX+ 395, gfx1151, 48 GB unified) 1 台のうえで 4 つの並走コンポーネントを動かし、Chrome へ WebRTC + WebSocket で配信します。
| コンポーネント | プロセス | 入力 | 出力 |
|---|---|---|---|
| Capture | uv run capture-run |
USB カメラ | SHM (1280×720 BGR letterbox 済) |
| YOLO11m |
serve 内のバックグラウンドスレッド |
SHM | bbox JSON → /ws/bbox
|
| VLM |
llama-server --reasoning off (別プロセス) |
serve の VlmRunner からの HTTP リクエスト (画像+プロンプト) |
キャプション JSON → /ws/caption
|
| aiortc サーバ |
uv run serve (FastAPI + uvicorn) |
SHM | WebRTC video track + WS broadcast |
設計の鍵となる判断
-
SHM は "latest frame slot" 1 つだけ。Capture は常時上書き、読み手 (aiortc / yolo / vlm) は推論開始時にスナップショット (
np.array(copy=True)) する。古いフレームでの推論積み残しを構造的に防ぐ。 - キューにはフレームを乗せない。bbox / caption JSON だけが asyncio.Queue → WebSocket に流れる。
-
VLM へのフレーム受け渡しは JPEG 圧縮済みバイト列。SHM の生 BGR を
cv2.imencode('.jpg', ...)してから llama-server の/v1/chat/completionsに base64 で投げる。 -
YOLO は
serveプロセス内のスレッドで動く。HANDOFF の元案は別プロセスだが、torch/CUDA は GIL を C++ 中で解放するので asyncio loop を block しない。Step 5 で fp16 推論 8 ms p50 が確認できた時点でこの判断は妥当。 - VLM だけは別プロセス (llama-server)。理由は (a) 21 GB の GGUF を Python venv とは独立に常駐させたいこと、(b) llama.cpp のチューニングや再起動を server 本体と切り離したいこと。
2. カメラ抽象化レイヤ (CAL)
Camera abstraction layer
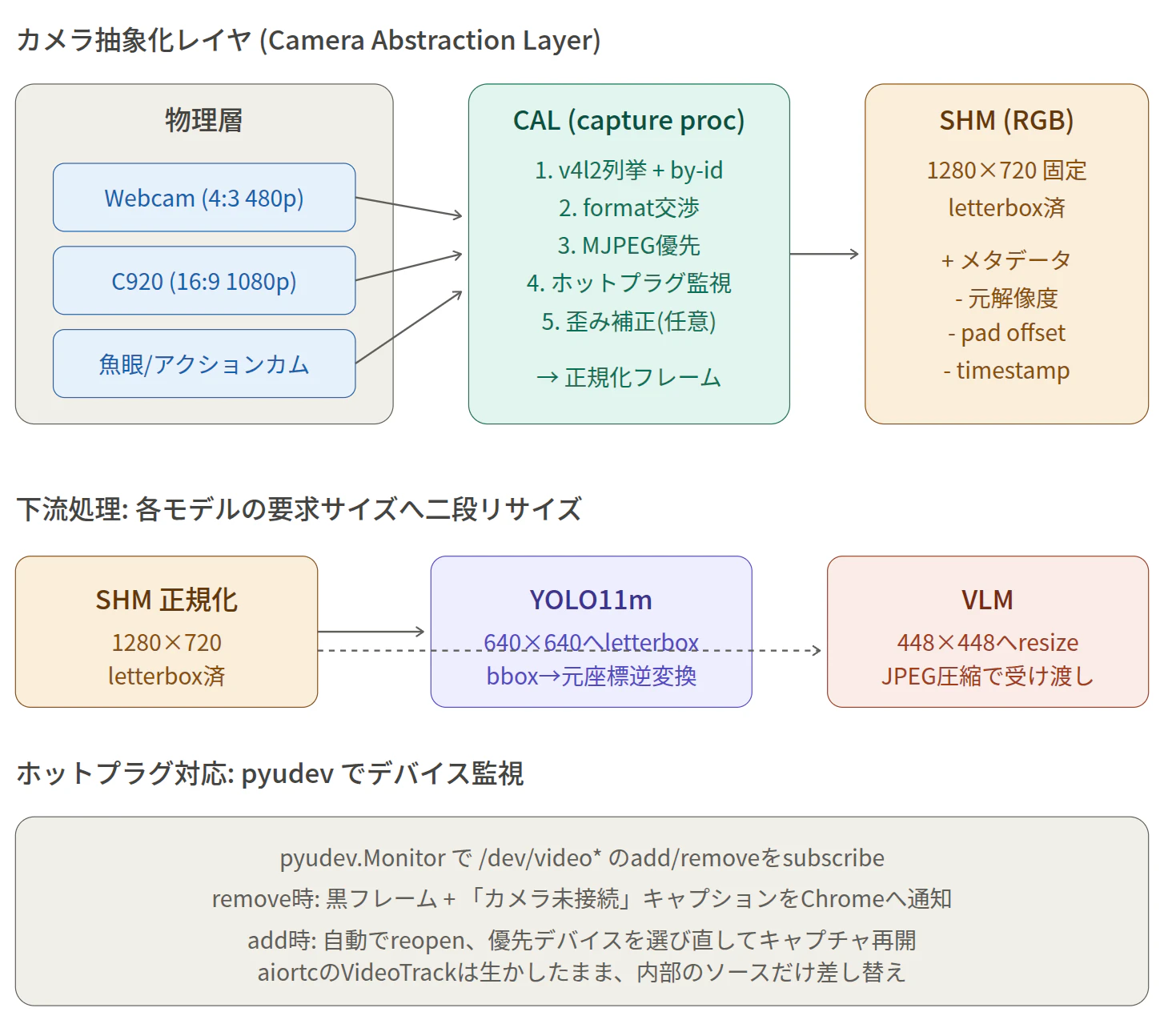
「画角の違うカメラ・差し込むポートが変わっても動く」要件を満たすため、src/capture/ に物理層 → 正規化フレーム生成までを集約しました。
2.1 デバイス検出 (device_manager.py)
-
pyudev.Context().list_devices(subsystem='video4linux')で udev に登録された v4l デバイスを列挙 - USB の
ID_VENDOR_ID/ID_MODEL_IDを取り出してvid_pid="046d:0892"のような指定にも対応 -
/dev/v4l/by-id/...の symlink からは安定 ID としてby_idを取得 - 1 つの USB カメラが
index0(映像) /index1(メタデータ) など複数 v4l ノードを作るので、is_capture_capable()で実際にcv2.VideoCapture.read()成功するノードに絞り込み -
config.yamlのcamera.preferred[]をパターン照合 (globusb-Logitech*/ VID:PID) → なければfallback: any
2.2 フォーマット交渉 (format_negotiator.py)
cv2.VideoCapture の set(CAP_PROP_FOURCC, ...) ladder を MJPG → YUYV の優先順で試行し、get(CAP_PROP_*) で実際に確定した値を読み戻します。MJPEG を優先するのは USB 帯域効率が YUYV より圧倒的に良いから (1280×720@30fps が YUYV だと USB 2.0 帯域で破綻しやすい)。
2.3 letterbox 二段構成 (frame_normalizer.py)
- CAL 出力 = 1280×720 固定 BGR letterbox 済
- スケール =
min(target_w/src_w, target_h/src_h)でアスペクト保ったまま縮小、余白は(114, 114, 114)グレーで埋める -
pad_x / pad_y / scale / original_w / original_hを SHM ヘッダに記録 → 下流で逆変換可能 - YOLO11m 入力 (640×640) と VLM 入力 (~448) は Ultralytics / mtmd 側で自動 letterbox。CAL では二段目を作らない (重複変換のコストを避ける)
- bbox 座標は CAL 正規化フレーム (1280×720) 上の絶対座標で WS 送出。Chrome 側は
<canvas width=1280 height=720>の固有解像度を CSS でビデオに合わせるだけ → 1 段の縮尺だけで描画可能
2.4 ホットプラグ対応 (hotplug_watcher.py, capture_session.py)
-
pyudev.MonitorObserver(filter_by='video4linux')でadd/removeイベントを Queue に積む - メイン loop は 2 状態の状態機械:
-
SEARCHING: capture 不能。30 fps で黒フレーム +connected=Falseを SHM に書き続ける (下流が「カメラ不在」を即座に認識できる) -
CAPTURING:cv2.VideoCaptureを別スレッド (CaptureReader) で読み、main thread が SHM へ書く
-
-
CaptureReaderはcv2.VideoCapture.read()の抜き取り時ブロックを避けるため、daemon thread で常時 read。停止時はcap.release()で stuck read を解除 -
addイベントで即時 rescan、remove時に当該 dev_path がアクティブなら SEARCHING に遷移 - aiortc の
ShmVideoTrackは SHM 経由で間接接続なので、カメラが入れ替わってもRTCPeerConnectionを切らない (Chrome の動画が止まらない)
3. SharedMemory 設計 (shm_writer.py)
3.1 レイアウト (合計 36 B + frame data)
| offset | size | フィールド |
|---|---|---|
| 0 | 8 |
seq_lock (uint64): even=stable / odd=writer mid-write |
| 8 | 8 |
timestamp_ns (uint64) |
| 16 | 2 |
original_w (uint16) |
| 18 | 2 |
original_h (uint16) |
| 20 | 2 |
frame_w (uint16) |
| 22 | 2 |
frame_h (uint16) |
| 24 | 2 |
pad_x (uint16) |
| 26 | 2 |
pad_y (uint16) |
| 28 | 4 |
scale (float32) |
| 32 | 1 |
channels (uint8) |
| 33 | 1 |
pixel_format (uint8): 0=BGR / 1=RGB |
| 34 | 1 |
connected (uint8): 0=合成黒フレーム / 1=実映像 |
| 35 | 1 | (padding) |
| 36 | W·H·3 | frame data (uint8) |
struct フォーマット: <QQHHHHHHfBBB1x (Python の struct.calcsize で 36 確認済)。
3.2 seqlock の挙動
ライター (Capture) は単一プロセス。x86_64 の整列 8 byte 書き込みは hardware atomic なのでロックフリー seqlock が成立します。
ライター:
1. seq = next odd (= 書き込み中マーカー)
2. ヘッダとフレームを書き込む
3. seq = next even (= 完了マーカー)
リーダー:
for retry in range(16):
s1 = read seq
if s1 odd: sleep(100us); continue ← ライターと衝突中
copy header + frame
s2 = read seq
if s1 == s2: success
else: continue ← copy 中にライターが上書き
return None ← 16 retry でも捕まえられず
3.3 「画面が一瞬黒くなる」バグの修正
初版ではリーダーがタイトに 8 retry → 失敗で None 返却 → ShmVideoTrack が黒フレームに fallback、というパスで Chrome 上に時々 1 frame の黒が出ていました。原因は:
- ライターの "odd" 滞在時間 ≈ 500 µs (
np.copytoで 2.6 MB) - リーダーの 8 retry はタイトループで合計 ~8 µs しか経過せず、ライターが終わる前に諦めていた
修正:
-
read()の retry にtime.sleep(100us)を挟み、最大 retry を 8 → 16 に -
ShmVideoTrack側で「最後に成功したフレーム」をキャッシュし、None だったら直前フレームで埋める (TTL 1 秒で stale ガード)
これで Chrome 上の黒フレーム発生は実測 0 に。
3.4 resource_tracker パッチ
multiprocessing.shared_memory には bpo-38119 があり、attach した側でも unlink しようとして spurious warning や二重 unlink が起きます。_suppress_resource_tracker_for_shm() で register / unregister をモンキーパッチして無視させる定石対応を入れています。
4. 推論バックエンド
4.1 YOLO11m (Step 3)
| 項目 | 値 |
|---|---|
| バックエンド | Ultralytics + ROCm PyTorch 2.9.1 |
| 入力 | 1280×720 BGR (SHM 正規化フレーム) |
imgsz |
640 (Ultralytics 内部で letterbox + 逆変換、bbox は元座標で返る) |
| 量子化 | fp16 (yolo.half: true) |
| 単独 fps |
97.8 fps (benchmark-yolo --source shm、ただし dedup なし、GPU 律速) |
| パイプライン fps |
30.1 fps (benchmark-concurrent --no-vlm、カメラ 30fps 律速) |
ベースラインの取り違いに注意: benchmark-yolo --source shm は SHM 重複 read で同フレーム何度も推論する → GPU 純粋スループット 97.8。一方 benchmark-concurrent --no-vlm は meta.seq で dedup → カメラレートに張り付く 30 fps。Step 5 の比較は後者を baseline に取らないと「-71% 劣化」のような誤読が起きます。
退避プラン (scripts/export_yolo_onnx.py): model.export(format='onnx', imgsz=640, simplify=True) で ONNX を吐き、onnxruntime で読める状態を維持。CPU EP で実測 15.4 fps (30 fps target には届かないので primary ではなく、graceful degradation 用)。MIGraphX EP は AMD-built ort 必須。
4.2 Nemotron-3 Nano Omni (Step 4 / 7b)
| 項目 | 値 |
|---|---|
| モデル |
unsloth/NVIDIA-Nemotron-3-Nano-Omni-30B-A3B-Reasoning-GGUF, Q4_K_XL (~21 GB) + mmproj-F16 (~1.5 GB) |
| ランタイム | llama.cpp ROCm/HIP build (llama-server 常駐) |
| 入力 | 1280×720 BGR → JPEG (quality 90) → base64 → /v1/chat/completions
|
n_predict |
128 (50 字程度の日本語キャプション、~60-100 tokens) |
| 単独 inference |
~1262 ms (Step 4 mtmd-cli) / ~1300 ms (Step 7b llama-server) |
| 並走 inference | ~1294 ms (Step 5、YOLO 同居時)、+2.5% の劣化のみ |
--reasoning off 必須。Reasoning モデルなのでデフォルト (auto) では <think> タグに n_predict を全消費し、回答が空になります。同じ GGUF を mtmd-cli で使うと空 <think></think> の挙動になるので両ランタイムで違うのは要注意。
VlmServerWorker は llama-server の /v1/chat/completions レスポンスから:
-
choices[0].message.contentをキャプション本文として取得 -
<think>...</think>を正規表現で除去 (保険) -
timings.prompt_ms / predicted_ms / *_per_secondとusage.prompt_tokens / completion_tokensをVlmTimingに詰める
4.3 Step 5: YOLO + VLM 同居の Go/No-Go
YOLO alone YOLO+VLM (fp32) YOLO+VLM (fp16)
fps 30.1 27.9 27.9
p50 latency (ms) 11.07 11.78 8.05
p99 latency (ms) 11.80 88.67 112.32
VLM median inf (ms) — 1294 1151
VLM eval_tps — 48.1 53.6
benchmark-concurrent --frames 600 の出力。fp16 が VLM 側の余裕を増やす ("YOLO が早く終わるので VLM が触れる窓が広がる") のがこのデータから読み取れる重要な発見です。p99 spike (~100 ms) は VLM の eval phase でのコンテキストスイッチ起因で、bbox 描画上は約 3 frame の stutter として現れる程度。
5. WebRTC 配信 (src/server/)
5.1 Video Track (webrtc_track.py)
class ShmVideoTrack(VideoStreamTrack):
async def recv(self) -> VideoFrame:
pts, time_base = await self.next_timestamp() # aiortc が 30fps を pacing
# SHM lazy attach (capture-run が後から起動しても自動接続)
# SHM read → np.copyto → av.VideoFrame.from_ndarray(format='bgr24')
# 失敗時は last_frame キャッシュ、TTL 1s で黒フォールバック
- aiortc は CPU エンコード (VP8 デフォルト)。1280×720@30fps なら Ryzen AI MAX+ 395 で余裕
- ROCm VCN ハードウェアエンコーダは aiortc 非対応なので使わない
-
next_timestamp()の sleep が 30 fps cadence を担保
5.2 シグナリング (app.py)
POST /offer で SDP 交換。20 行程度の最小実装:
@app.post("/offer")
async def offer(payload: SdpPayload):
pc = RTCPeerConnection(configuration=RTCConfiguration(iceServers=[]))
pc.addTrack(ShmVideoTrack(...))
await pc.setRemoteDescription(RTCSessionDescription(sdp=payload.sdp, type=payload.type))
answer = await pc.createAnswer()
await pc.setLocalDescription(answer)
return {"sdp": pc.localDescription.sdp, "type": pc.localDescription.type}
同一 LAN 想定で STUN / TURN なし。ホストキャンディデートだけで繋がります。config.yaml > server.ice_servers を空配列にしてあるので必要なら STUN を追加可能。
5.3 WS broadcast (ws_broadcaster.py, yolo_runner.py, vlm_runner.py)
-
WsBroadcaster: クライアント集合 + asyncio Lock + JSON broadcast。送信失敗のクライアントを自動 drop -
YoloRunner: daemon thread。SHM read → predict →_latest = {...}を thread-safe slot で更新 -
_broadcast_bbox_loop: 30 fps の async task、frame_seqで dedup して/ws/bboxに push -
VlmRunner: 同型、cadence 2 秒。llama-server health check → SHM attach → loop。ts_nsで dedup -
_broadcast_caption_loop: 0.5 fps cadence
5.4 フロントエンド (src/web/)
-
<video>(WebRTC track)、<canvas>(bbox)、半透明<div>(caption) の 3 層 -
<canvas>はwidth=1280 height=720固定、CSS でビデオに被せる。bbox 座標が CAL 正規化フレーム空間そのままなので 1 段スケールで描画 -
overlay.js/caption.jsともに WebSocket disconnect 時は exponential backoff で再接続 (上限 5 秒)
6. 起動・終了スクリプト
start_all.sh
tmux session llava に 3 windows:
-
capture←uv run capture-run -
serve←uv run serve(FastAPI + YoloRunner + VlmRunner) -
vlm←~/llama.cpp/build/bin/llama-server ... --reasoning off
ROCm 環境変数を per-pane で export するので ~/.bashrc に書き忘れていても確実に効きます。http://localhost:8080/ がレスポンスを返すまで curl で 30 秒ポーリングしてから Chrome (or chromium / xdg-open) を起動。
stop_all.sh
各 window に Ctrl-C 送信 → 5 秒待機 → tmux kill-session。万一の残留プロセスは pgrep -f "src.server.app|capture.main|llama-server" で検出して SIGINT → SIGKILL の 2 段階で後始末。
7. 実装中に判明した落とし穴 (再発防止メモ)
7.1 Capture / SHM
- SHM seqlock の retry は sleep 必須: タイトループだとライターの 500 µs 窓を捕まえられない (3.3 節参照)
-
multiprocessing.shared_memory.SharedMemoryの resource_tracker パッチ: 二重 unlink 警告を抑制 (3.4 節) -
shm.read()の戻り値は(frame, meta)であって(ts, frame)ではない。benchmark_concurrent.py初版でts, frame = gotと書いてValueError: array truth value ambiguousを踏んだ -
cv2.VideoCapture.read()は USB 抜き取り時にブロックする: 別スレッドで read、main thread はタイムアウト監視 (CaptureReader)
7.2 YOLO
- dedup の有無でベースラインが ~3 倍違う: GPU 律速 (97.8 fps) と pipeline 律速 (30.1 fps) を混同しないこと
- fp16 が並走時に VLM を救う: 単独 YOLO fps はカメラレートで頭打ちなのに、fp16 にすると並走時の VLM eval_tps が +12% 改善
7.3 VLM (llama.cpp)
-
llama-mtmd-cliには--no-display-promptフラグが無い: stdout に prompt がエコーされる → Python 側で先頭 strip -
stderr に非 UTF-8 バイトが混じる: モデルロード進捗の制御文字。
subprocess.run(..., errors='replace')で救済 -
llama_perf_*ログのprompt eval timeとeval timeを素朴に正規表現すると両方 prompt 行に当たる:(?<!prompt )eval timeの negative lookbehind が必要 - *
llama-serverで--reasoning auto(default) は -Reasoning モデルだと thinking が n_predict を食いつぶして content が空になる:--reasoning offを必須化
7.4 WebRTC / Frontend
-
chrome キャッシュ:
caption.jsを更新したのに反映されない時は Ctrl-Shift-R でハードリロード -
ICE gathering 待たずに
/offerを投げると ICE candidate が SDP に乗らない:iceGatheringState === 'complete'を await -
status 行の
+/-符号: ベンチスクリプトで「fps が下がった」を+71.5%と表示するなど混乱の元 → 「+ = 改善 / - = 劣化」に統一
8. 関連ドキュメント
-
HANDOFFJ.md— Claude.ai で行った設計検討の引き継ぎ文書 (本実装の元設計) -
READMEJ.md— git clone から動作までのセットアップ手順 -
docs/01_pipeline_architecture.svg/docs/02_camera_abstraction_layer.svg— 設計図 -
docs/LLaVA設計図.pptx— Chrome 上での画面レイアウト原案