この記事における主張
「REST APIで扱うリソースが6つを超え始めると、自動E2Eテスト時間の長時間化の傾向にあるので自動テストの見直しを始めたほうが良い。APIであれば30本、テストケース数であれば1,500ケース、ソースコードの行数であれば30,000行である。」
経緯
ある日、私は散歩をしていた。そのとき、ぼんやりと、自分が管理しているサーバーの自動テストについて考えていた。現状特段に問題はなかったが、最近はAPIの数も増えてきて、自動テストを実施する時間が長時間化しつつあり、そこに懸念を感じていた。その時、
「なんとかして自動テストを高速化しなくてはなぁ」
と思ったが、一方で、
「実は、そんなことは無理なんじゃないか?すべての自動テストには少なからず時間がかかるんだから、実時間で行える自動テストの数に上限があるのではないか?」
ということを思いついた。
そこで、簡単なREST APIを数理モデル化し、自動テストのテストケース数の上限を求める。ということを試みた。
REST APIの模式化
今回、REST APIとしてモデル化するのはCRUDである。CRUDとは、
- Create: リソースの作成(POST /users)
- Read: リソースの読み取り(GET /users/:id)
- Update: リソースの更新(PUT /users/:id)
- Delete: リソースの削除(DELETE /users/:id)
という形式である。また、ここにListというパターンも追加する。Listとは
- List: リソースの一覧取得(GET /users)
といういわゆるリソースを一覧できる機能である。もしくは、queryなどのパラメーター引数で検索を行ったりするエントリポイントとして利用されることもある。
REST APIは色々なものがあるが、リソースに対して、この5種類の操作が定義されていることが多い。そのため、1リソースにつき5種類のAPIが必要である。 と仮定する。
テストケースの模式化
この章では、1つのAPIに対してどれくらいのテストケースが必要かを議論したい。ここでは、代表的なHTTPステータスを用いる
| HTTPステータス | 意味 |
|---|---|
| 200 | 成功 |
| 400 | 入力エラー |
| 401 | 認証エラー |
| 403 | 権限エラー |
| 404 | リソースが存在しない |
自分がREST APIのテストをするときも概ねこれくらいのテストケースを基本として行っている。本来は、他にもHTTPステータスがあるが、例えば、X(Twitter)のREST APIの例を確認してみる。
XのREST APIにはv1.1とv2という2つのバージョンが存在するが、その2つに共通するような(共通するような一般的な)HTTPステータスは9種類である。そのうち、2種類は障害に関するもの(500,503)である。ほかには、多数の接続を拒否する429、streamに関するステータスである409ということであり、おおむね一般的なAPIとして5種類のHTTPステータスを返しており、これによりテストケースを5つは必要である。ということが分かる。
テストケースの依存関係と基本の立式
ここで以下のように定義する。
\begin{align}
&t_{test}: テストを行うためにかかるAPIのレスポンス時間 \\
&C_{1}:1番目のリソースのCreateのテストにかかる時間 \\
&R_{1}:1番目のリソースのReadのテストにかかる時間 \\
&U_{1}:1番目のリソースのUpdateのテストにかかる時間 \\
&D_{1}:1番目のリソースのDeleteのテストにかかる時間 \\
&L_{1}:1番目のリソースのListのテストにかかる時間 \\
\end{align}
ここで、APIの依存関係に注目する。

当たり前であるが、リソースの読み取り(Read)のテストを行いたい時、事前にリソースを作成(Create)しておかなければならない。これは、他のUpdate,Delete,Listでも同じである。その部分を立式する。
\begin{align}
&C_{1}=t_{test} \\\
&R_{1}=C_{1}+t_{test} \\
&U_{1}=C_{1}+t_{test} \\
&D_{1}=C_{1}+t_{test} \\
&L_{1}=C_{1}+t_{test} \\
\end{align}
ここで、APIのレスポンス時間>>テストに関するAsssertにかかる時間として、レスポンス時間以外は無視するような近似を行っている。
リソースにかかわる全体のテスト時間を定義する
\begin{align}
&A_{1}:1番目のリソースにかかわる総テスト時間 \\
&A_{1}=5(C_1+R_1+U_1+D_1+L_1) \\
\end{align}
「テストケースの模式化」で議論したように1つのAPIにつき5つのテストケースが必要であることがわかった。そのため、以上のような立式を行っている。ただし、ここには一定の近似が入っている。例えば、Createに関する404のテストというものは、基本的には存在しない。ここでは簡便のためにそれぞれのAPIに対してテストケースは5つ固定としている。
リソース階層を意識した立式
ブログのAPIを考える。そうした場合、最初に「ユーザー登録」があり、そのあとに「記事の作成」を行う。このようにリソース間には階層構造が存在する。これらを意識すると以下のような依存関係がある。

先の例でいえば、ユーザー登録にC1だけ時間がかかるとすると、その次の、記事の作成には、それに加えて、記事の作成のAPIを呼び出すだけ時間がかかる。これを考慮すると、以下のように立式できる。
\begin{align}
&C_{i}=C_{i-1}+t_{test} \\\
&R_{i}=C_{i}+t_{test} \\
&U_{i}=C_{i}+t_{test} \\
&D_{i}=C_{i}+t_{test} \\
&L_{i}=C_{i}+t_{test} \\
&A_{i}=5(C_i+R_i+U_i+D_i+L_i) \\
\end{align}
このようにi番目の階層にかかるテスト時間を立式できた。ここでは、深さ方向の議論しか行わない。例えば、Xであれば、「ユーザーをフォローする」「ユーザーをリストに追加する」という概念が存在する。これは、事前に「ユーザーの作成」という概念が存在すればよく、それぞれが並列の概念になっている。この場合、ただ線形に値が増えていくだけであり、ボトルネックになりにくいためここでは議論しない。
式変形と総和
ここまででリソースの階層ごとのテスト時間が議論できた。
\begin{align}
&A_{i}=5(C_i+R_i+U_i+D_i+L_i) \\
\end{align}
今回知りたいのは、テスト全部に対するテスト時間であるため、これを解く。
\begin{align}
\sum_{i=1}^n A_{i} &= \sum_{i=1}^n 5(C_i+R_i+U_i+D_i+L_i) \\
&= \sum_{i=1}^n 5(C_i+(C_i+t_{test})+(C_i+t_{test})+(C_i+t_{test})+(C_i+t_{test})) \\
&= \sum_{i=1}^n 5(5C_i+4t_{test}) \\
&= \sum_{i=1}^n 25C_i+4nt_{test} \\
&= 25t_{test}\sum_{i=1}^n i+4nt_{test} \\
\therefore \sum_{i=1}^n A_{i} &= \frac{25t_{test}n(n+1)}{2} + 4nt_{test} \\
\end{align}
これで全体のテスト時間を算出する数式が求まった。
また、テストケース数に関しては、以下のように算出できる
\begin{align}
&N_{E2E}:E2Eテストケース数 \\
&N_{E2E} = 25n
\end{align}
これは簡単で1つのリソース数につき、5つのAPIが必要である。また、それぞれのAPIにつき5つのテストケースを想定しているため、上式のようになる。
条件設定と可視化
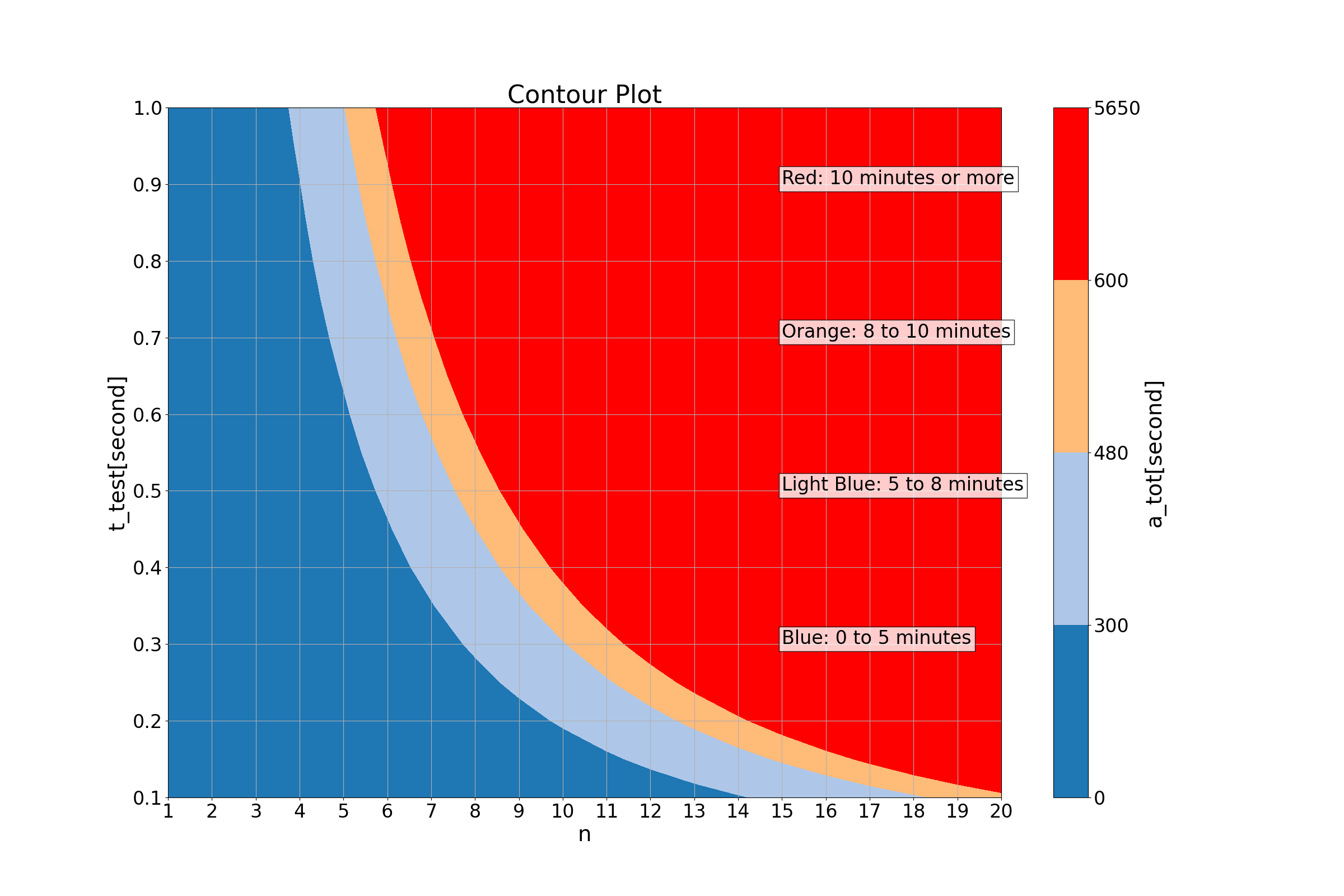
ここでは計算結果の可視化を行う。リソースの数nは1~20まで、REST APIのレスポンス時間t_testは0.1~1.0まで計算を行った。そして、それぞれのテストケースの総実行時間(a_tot)を色分けしてグラフを描いたのが以下である。
シミュレーションのコード
import sympy as sp
import matplotlib.pyplot as plt
import numpy as np
t_test = sp.Symbol('t_test')
n = sp.Symbol('n')
a_tot = 25*t_test * n * (n+1)/2 + 20 * t_test *n
assert a_tot.subs(n, 1) == 45 * t_test
assert a_tot.subs(n, 2) == 115 * t_test
t_values = np.arange(0.1, 1.05, 0.05)
n_values = np.arange(1, 21, 1)
T, N = np.meshgrid(t_values, n_values, indexing='ij')
results = np.zeros(T.shape)
for i in range(T.shape[0]):
for j in range(T.shape[1]):
results[i, j] = a_tot.subs({t_test: T[i, j], n: N[i, j]})
# Define the levels for the contour plot
levels = [0, 5*60 , 8*60, 10*60, np.max(results)]
print(sp.simplify(sp.expand(a_tot)))
# Create contour plot with a more subdued color palette and a more red top level
plt.figure(figsize=(24, 16)) # Increase the figure size
contour = plt.contourf(N, T, results, levels=levels, colors=["#1f77b4", "#aec7e8", "#ffbb78", "#ff0000"])
cbar = plt.colorbar(contour, label='a_tot')
cbar.ax.tick_params(labelsize=24) # Increase the font size of the colorbar labels
cbar.set_label('a_tot[second]', fontsize=28) # Increase the font size of the colorbar label
plt.xlabel('n', fontsize=28)
plt.ylabel('t_test[second]', fontsize=28)
plt.title('Contour Plot', fontsize=32)
plt.grid(True) # Add grid
plt.xticks(np.arange(1, 21, 1), fontsize=24) # Set x-axis to display integers
plt.yticks(np.arange(0.1, 1.1, 0.1), fontsize=24) # Set y-axis to display 0.1 increments
# Add annotations
annotations = [
("Red: 10 minutes or more", (15, 0.9)),
("Orange: 8 to 10 minutes", (15, 0.7)),
("Light Blue: 5 to 8 minutes", (15, 0.5)),
("Blue: 0 to 5 minutes", (15, 0.3))
]
for text, pos in annotations:
plt.text(pos[0], pos[1], text, fontsize=24, color='black', bbox=dict(facecolor='white', alpha=0.8))
plt.show()
plt.savefig('contour_plot.png')
ここで、エクストリームプログラミングという書籍がある。いわゆるアジャイルの文脈で、XPと呼ばれる技法の本である。

ここに「10分ビルド」というプラクティスがある。
自動的にシステム全体をビルドして、すべてのテストを10分以内に実行させること。ビルドに10分以上かかるようだと使用頻度が減り、フィードバックの機会が失われてしまう。ビルドが短縮できれば、途中でコーヒーを飲むこともない。
ここでは、10分以内にビルドを含めたテストを行うことを推奨している。 そのため、
赤:10分以上
橙:8~10分
水色:5~8分
青:0~5分
という色付けを行っている。
このグラフの見方であるが、これはある程度、各々の環境による部分もあるので、それを参考に考えていただきたい。個人的な経験則では、REST APIのレスポンス時間は100~200ms程度であると考えている。しかし、開発環境やテスト環境では、本番よりスペックの悪いマシンを使っていることがあるだろう。また、他にもテスト特有のセットアップが必要だったり、開発環境でテストを行う場合、本番環境では分離して構築しているDBなどを立ち上げているため性能が劣化している場合もある。そのため、300~400ms程度かかっていても仕方がないと考えている。そう考えた場合、400ms(0.4sec)でn=7のときに、テスト時間が5分を超え始めるラインになってくる。ここで今議論しているのは、いわゆるE2Eテストの時間のみであり、他の単体テストや結合テスト、あるいはソフトウェアのビルドに関しては議論の外である。そのため、このあたりがテストの目安になるのではないか。というわけで、最初に示した、
「REST APIで扱うリソースが6つを超え始めると、自動E2Eテスト時間の長時間化の傾向にあるので自動テストの見直しを始めたほうが良い。APIであれば30本、テストケース数であれば1,500ケース、ソースコードの行数であれば30,000行である。」
という主張の前半部分である。1つのリソースにつき5本のAPIを想定しているため、6つのリソースを取り扱うときはAPIが30本になる。
テストケースの規模とソースコード規模の算出
この章ではどれくらいのテストケースの規模、ソースコードの規模になると、自動テストの見直しをすべきか。という指針を与える。
GoogleTestingBlogによると、Googleでは、
E2Eテスト:結合テスト:ユニットテスト = 1:2:7

であることを推奨している。ここからE2Eテストケースと全体のテスト数の関係が分かる。
\begin{align}
N_{tests}&:全体のテストケース数 \\
N_{tests}&=10N_{E2E} \\
&=10 \times 25n \\
&= 250n \\
\therefore N_{tests}&=1500
\end{align}
単純に全体のテストケースはE2Eテストケースの10倍になる。そのため、テストケースを基準とした場合、1,500ケースが見直しの基準となる。
IPAから「ソフトウェア開発分析データ集2022」という資料が公開されている。その中にある「SLOC 規模あたりのテストケース数:全開発種別」を引用する。
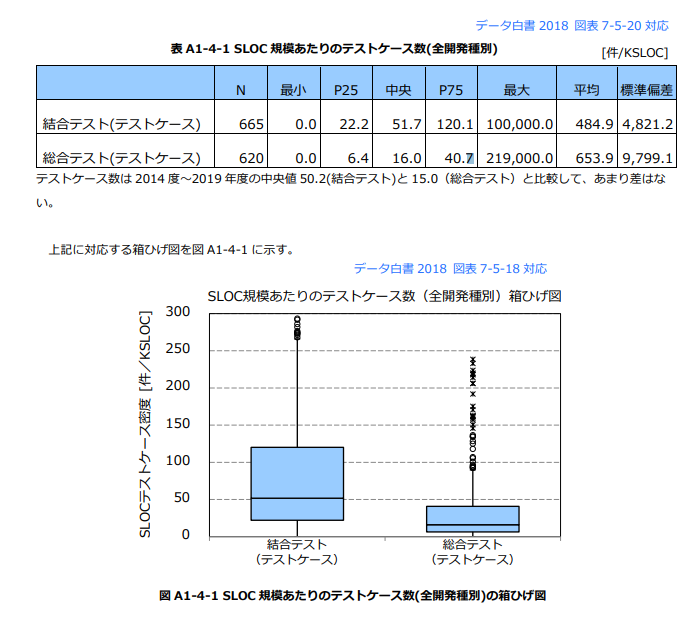
ここでは、結合テストの中央値、1KSLOCあたり51.7件のテストケースという値を用いて議論する。このようなケースの場合、おおむね平均値を用いて議論することが多い。しかし、箱ひげ図を見るとわかるようにケース数の多い少数のサンプルにより平均値が押し上げられている。そのため、平均値が分布を表す代表値として好ましくないので、中央値を用いた。
また、総合テストではなく結合テストで議論しているのは、IPAの調査方法が理由となっている。IPAの調査方法では総合テストは2種類に分かれている。
結合テスト
開発者は、ソフトウェアユニット及びソフトウェアコンポーネントを結合して、ソフトウェア品目にするための計画を作成し、ソフトウェア品目を完成させる。また、結合及びテストを行う。完成したソフトウェア品目と合わせてハードウェア品目、手作業や他システム等とあわせてシステムに結合、要件を満たしているかをテスト、システム適格性確認テスト実施可能状態であることを確認する。必要に応じて利用者文書等の更新を行う。テストの評価と共同レビューを実施する。総合テスト(ベンダ確認)
開発者は、ソフトウェア品目の適格性確認要求事項およびシステムに関して指定された適格性確認要求事項に従って、適格性確認テストおよび評価を行う。必要に応じて利用者文書等の更新を行う。また、監査の実施と支援をする。総合テスト(ユーザ確認)
開発者は、契約の中で指定された実環境にソフトウェア製品を導入するための計画を作成し、導入する。開発者は、取得者によるソフトウェア製品の受け入れレビュー及びテストを支援する。また、契約で指定するとおりに、取得者に対し初期の継続的な教育訓練及び支援を提供する。
また、データの親資料であるソフトウェア開発 データ白書2018-2019には
※本節の図表内の表記で、「総合テスト」は「総合テスト(ベンダ確認)」の工程を指すものとする。
と記載があり、この総合テスト(ベンダ確認)が文章中のE2Eテストの定義と一致しないと考えたため、結合テストを用いて議論した。
ここで本論に戻り、結合テストの中央値、1KSLOCあたり51.7件のテストケースであると考える。
\begin{align}
&1000[SLOC]/51.7[ケース] \\
& \approx 19.34[SLOC/ケース]
\end{align}
ここでは単体テスト・結合テスト・E2Eテストは、行数当たりのテストケースの密度が同一であることを仮定している。ここからE2Eテストケースの数からコード規模全体を算出すると
\begin{align}
ソースコード規模[SLOC] &= 19.34[SLOC/ケース] \times N_{tests}[ケース] \\
&= 19.34 \times 10N_{E2E} [SLOC]\\
&= 193.4N_{E2E} [SLOC] \\
\therefore ソースコード規模[SLOC] &= 29,010[SLOC]
\end{align}
したがって、おおむね30,000行程度で自動テストの見直しを行うのが良い。
私の感覚として1つのCRUD+LのAPIを作ったとき、おおむね3,000~4,000[LOC]という認識がある。したがって、6つのAPIを作ったとき、単純には18,000~24,000[LOC]という計算になり、少々推定値が大きいかもしれないが、そこまで的外れでもない。という感想である。
これが最初の主張の
「REST APIで扱うリソースが6つを超え始めると、自動E2Eテスト時間の長時間化の傾向にあるので自動テストの見直しを始めたほうが良い。APIであれば30本、テストケース数であれば1,500ケース、ソースコードの行数であれば30,000行である。」
最後の部分である、「ソースコードの行数であれば30,000行である」の理由である。
考察・感想
サーバーの管理者となり、網羅的なE2Eテストを全体として書く。ということをやってきた。その結果、「思ったより小規模の段階でテスト時間が長期化してしまう」という感触があった。それは、なぜだろうか。というところが言語化されたように思う。
今回のモデル化は確かに現実に即していない部分もある。取り扱ったモデルとして、深く階層構造を作るようなモデルであった。例えば、ECサイトを考えた場合、
「ユーザー登録」→「店舗登録」→「商品登録」→「商品コメント」→「商品コメント評価」
という5階層程度であり、それ以上はなかなか存在しないケースであると思われる。
ただここで考慮すべきポイントも明確になった。このようにREST APIの階層を深くしていくたびに、そのE2EテストにかかわるHTTPのレスポンス時間が階層ごとに重くなってくる。そして、それが全体の総テスト時間では、階層nに対しn^2で効いてくる。そのため、直感に反して、少しテストケースを追加しただけなのに、テスト時間が急増する。という感覚値に陥るのだと考えられる。
過去に、scpredictというサイトを作った。IPAの資料を基に、ソースコードの行数から工数・工期を求めることができる。

30,000行という規模は、5人×300日=1500人日、75人月の工数で開発すると、開発工数の妥当性が58%となる。これはIPAの調査したデータから工数の分布を求めたとき、全体の58%以下のプロジェクトが30,00行のコードを1500人日未満で工数未満で開発をしている。ざっくりと理解すると、開発するとき、日本レベルで見ればどれくらい開発工数に余裕のあるプロジェクトか?を示している。58%以下のプロジェクトがこれより少ない工数で開発しているので、割と妥当な範囲の工数、もしくは少し余裕のある工数であると設定している。これを2025年1月1日から開発すると2026年3月6日までに終わる可能性が56%である。一般的に知られているように工数における人日は人と日数は交換可能ではない。その関係を調査したデータがIPAにあったため、工数から工期を求めるモデルを作り、工期の確率分布を推定している。
この推論を正しいとするならば、5人で開発し始め、14ヵ月経ったあたりというのは、割としんどさのある時期ではないだろうか。最初は開発の興奮のテンション感があり、リリースしていくにつれ、機能が増えていく。しかし、そのうちテストの実行時間が長くなったり、そもそもテストの実行が失敗し始めたり、デプロイ時間が長くなり始めたり。新規で機能開発はしたいが、テスト周りや保守運用系の重さがきつくなってきてイライラし始めてテコ入れをしたい。初期に作った粗雑な自動テストやCDが目につき始める時期ではないだろうか。もちろん人数にもよるが、こう聞いてみると割合リアリティのあるソースコード規模ではないだろうか。
私はどれかの条件に該当すれば、自動テスト全体を見直すのが良いと考えている。
- ビルドと自動テスト合わせた時間が10分以上
- 扱っているリソースが6つ以上
- APIが30本以上
- テストケースが1,500ケース以上
- E2Eテストケースが150ケース以上
- ソースコードが30,000行以上
これはあくまできっかけである。いわゆるコードの臭いのような、そろそろ自動テストの長期化の危険性を感じる始めるためのカナリアである。見直した先で何をすべきか。というものは難しい。「CIなどの自動テスト環境のサーバースペックを上げ、レスポンス時間の短縮を目指す。」「DBのスキーマを見直し、レスポンス時間の短縮を図る。」「テスト時のサーバーの初期化を並列化し高速化する。」「APIサーバーの分割を考える。」といったことが考えられる。しかし、改善したとしても、このテスト時間の呪縛というのは成長し続ける限り存在し続ける。そのため、継続的な見直しが必要である。
宣伝
「ソフトウェアデザイン 2025年1月号 」に寄稿しています!!

「Web APIテスト 実践ガイド」ということで、私が「第3章 実践的なWeb APIテストの考え方」を書かせてもらいました。機能テスト・パフォーマンステスト・セキュリティテストの実践的な入門を書きましたので、ご興味のある方がご一読いただければと思います!!