概要
今回は,BigQueryを用いてデータの平均値や標準偏差,最大値最小値などの要約統計量を算出します。また,算出する際にWINDOW句を利用することで,書きやすく読みやすいクエリにする為の術を学んでいこうと思います。
今回のやること一覧
1.データ全体,週ごとの要約統計量を算出する
2.同じ内容をWINDOW句を使って書いてみる
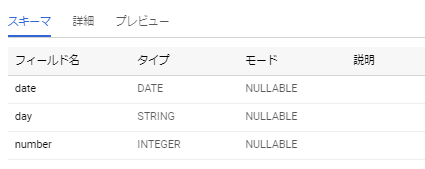
使用テーブル:number_of_people_monthly
| date | day | number |
|---|---|---|
| 2019-04-01 | Monday | 200 |
| 2019-04-02 | Tuesday | 10000 |
| 2019-04-03 | Wednesday | 2000 |
| 2019-04-04 | Thursday | 4000 |
| 2019-04-05 | Friday | 500 |
| 2019-04-06 | Saturday | 600 |
| ........................ | ........................ | ........................ |
| 2019-04-25 | Thursday | 630 |
| 2019-04-26 | Friday | 338 |
| 2019-04-27 | Saturday | 924 |
| 2019-04-28 | Sunday | 914 |
| 2019-04-29 | Monday | 546 |
| 2019-04-30 | Tuesday | 324 |
 |
1.データ全体,週ごとの要約統計量を算出する
あるデータを得たときに,平均値や最大値,最小値などの要約統計量を算出するとそのデータの特性が文字通り要約され,どの様なデータなのかが捉えやすくなり,大変便利です。今回はデータの平均値,最大値,最小値,中央値,分散,標準偏差を求めていきましょう。
基本的にはそれぞれに対応する関数が備わっていますのでそれを利用すればいいですが,中央値だけは対応する関数がありませんので,「PERCENTILE_CONT」という関数を利用して算出します。
この関数は,データ全体を昇順に並べ,最初の値を「0」,最後の値を「1」とした時に,0~1の値に位置するデータを教えてくれます。
例えばデータが9個あった場合には0.125は昇順で2番目の値,0.5は5番目の値,という感じです。
さらに,データの数が奇数の場合,つまりちょうど0.5の位置に値がない場合にも,その前後の値からその位置に来るであろう値を自動で算出しくれるのです!便利!
それでは,実際にクエリを書いてみましょう。まずはデータ全体の要約統計量を算出します。
SELECT
-- PERCENTILE_CONTにはOVER()が必須な為,必要のない他の関数にもつける
ROUND (AVG (number) OVER (), 2) AS average,
MAX (number) OVER () AS max,
MIN (number) OVER () AS min,
-- PERCENTILE_CONT()内でカラムとデータの位置を指定する
-- 今回はnumberの0.5に位置するデータが知りたい
PERCENTILE_CONT (number, 0.5) OVER () AS median,
-- 標準偏差を算出する関数
ROUND (STDDEV (number) OVER (), 2) AS stddeviation,
-- 分散を算出する関数
ROUND (VARIANCE (number) OVER (), 2) AS variance
FROM
`qiita.number_of_people_monthly`
-- 何も入れていないOVER()を付けた為,まったく同じ内容の行がデータ個数分出力される
-- 今回は1つあれば十分なので,LIMITで出力される行数を指定
LIMIT 1;
これを実行すると…
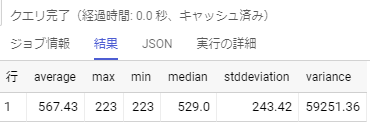
こんな感じです。
「median」は529になっています。今回使用したデータの15番目と16番目はそれぞれ「523」と「535」だった為,足して2で割れば同じ値になりますよね。大丈夫そうです。
続いて週ごとの要約統計量も算出しましょう。
これは前のクエリで何も入れなかったOVER()内で,週ごとに区切るように指定してやればいいですね。
SELECT
*
FROM
(
SELECT
-- BigQueryのEXTRACT関数で週ごとに区切るための番号(その日付がその年の第何週目か)を付与
EXTRACT (week FROM date) AS week,
-- PARTITION BYで「どのカラムの内容で区切るか」を指定 今回は上述のEXTRACT関数で付与した週番号ごとに区切って処理をしてもらう
ROUND (AVG (number) OVER (PARTITION BY (EXTRACT (week FROM date))), 2) AS average,
MAX (number) OVER (PARTITION BY (EXTRACT (week FROM date))) AS max,
MIN (number) OVER (PARTITION BY (EXTRACT (week FROM date))) AS min,
PERCENTILE_CONT (number, 0.5) OVER (PARTITION BY (EXTRACT (week FROM date))) AS median,
ROUND (STDDEV (number) OVER (PARTITION BY (EXTRACT (week FROM date))), 2) AS stddeviation,
ROUND (VARIANCE (number) OVER (PARTITION BY (EXTRACT (week FROM date))), 2) AS variance
FROM
`qiita.number_of_people_monthly`
) AS t1
-- このクエリでも同じ内容の行が,今度は各週の日数分出力されてしまうので,週につき1つだけ出力されるようにする
GROUP BY
week,average, max, min, median, stddeviation, variance
ORDER BY
week;
実行結果は...
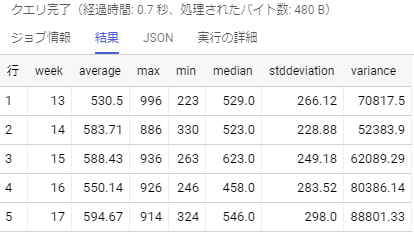
こんな感じで,週ごとの要約統計量が計5行出力されました。
しかし,上記のクエリを見ると分かりますが,各行のOVER()内は同じ内容が何度も繰り返し書かれている上に,カッコがいくつも重なっているので,見づらくなっていますよね。
また,今回はPARTITION BYしか使わなかったですが,ORDER BY,Window Flame句を入れた場合や,要約統計量として最頻値や四分位範囲なども加えた場合には,同じ内容を何度も書くのは大変煩わしい作業になっていきますし,ミスが増えてしまう可能性も高まります。
そこで,クエリを見やすく,書きやすくするために,次の項では分析関数に搭載されている「WINDOW句」を紹介したいと思います。
2.同じ内容をWINDOW句を使って書いてみる
BigQueryの分析関数には,OVER()内を省略できる「WINDOW句」という機能が搭載されています。これを使えば,分析関数を複数行並べて書くようなクエリも,すっきりと見やすくすることが出来ます。
以下公式ドキュメントより引用:
WINDOW 句は名前付きウィンドウのリストを定義します。その window_name は SELECT リストの分析関数で参照できます。これは、複数の分析関数に同じ window_frame_clause を使用する場合に便利です。
上で書いた週ごとの要約統計量を算出するクエリを,WINDOW句を使って書いてみると,こんな感じになります。
SELECT
*
FROM
(
SELECT
EXTRACT (week FROM date) AS week,
-- OVER以下は()を使わず後述のWINDOW句で設定した名前を指定する
ROUND (AVG (number) OVER part_week, 2) AS average,
MAX (number) OVER part_week AS max,
MIN (number) OVER part_week AS min,
PERCENTILE_CONT (number, 0.5) OVER part_week AS median,
ROUND (STDDEV (number) OVER part_week, 2) AS stddeviation,
ROUND (VARIANCE (number) OVER part_week, 2) AS variance
FROM
`qiita.number_of_people_monthly`
-- WINDOW句はFROM句の後に
-- 先に別名を設定し,その後分析関数で用いる予定のOVER()内を記述する
-- これで,SELECT句内では別名を記述するだけでOVER()が処理されるようになる
WINDOW
part_week AS (PARTITION BY (EXTRACT (week FROM date)))
) AS t1
GROUP BY
week, average, max, min, median, stddeviation, variance
ORDER BY
week;
実行結果は…
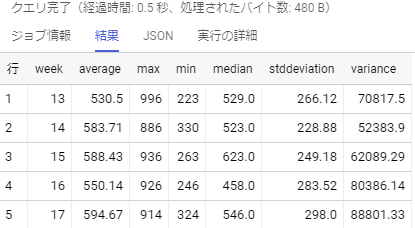
前項で出力した,週ごとの要約統計量の結果と同じになっていますね。大丈夫そうです。
そして,出力結果は同じでも,クエリをみるとやはりWINDOW句を使った方が1行1行の文量も少なく,スッキリしているのでとても見やすいです。
また,今回は全ての分析関数で同じOVER()を用いましたが,例えばWINDOW句で「window_name AS PARTITION BY date」と指定した後にSELECT文で「〇〇() OVER (window_name ORDER BY day)」という様に,WINDOW句で指定した別名とORDER BYやWindow Flame句を組み合わせて使うことも出来るので,OVER()が同じでなかったとしても,やはり使うと楽になる部分が多いかと思います。
まとめ
要約統計量は,データの特徴を捉えることができ,データの数が膨大である際や,未知のデータと向き合う際などにも大変便利です。
また,上述したように,WINDOW句はOVER()が同じでなくても使える,見やすくもなり書きやすくもなるとても便利な機能ですので,積極的に使っていきましょう。
参考サイト
https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators?hl=ja#aggregate-analytic-functions
https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators?hl=ja#percentile_cont
https://cloud.google.com/bigquery/docs/reference/standard-sql/analytic-function-concepts?hl=ja#window-clause
https://cloud.google.com/bigquery/docs/reference/standard-sql/query-syntax?hl=ja#sql-syntax