英検の大問1は、短文穴埋め問題になっています。例えば、こういう問題です。
My sister usually plays tennis ( ) Saturdays.
1. by 2. on 3. with 4. at
Bob ( ) five friends to his party.
1. made 2. visited 3. invited 4. spoke
文の中の隠された部分に入るものを、選択肢の中から答える問題です。文法的な判断もあれば、文脈から意味の通りが良い単語を選ぶ問題もあります。5級から1級まですべての難易度で出題される形式です。
この問題形式は、BERT (Bidirectional Encoder Representations from Transformers)の学習アルゴリズム(のうちの1つ)とよく似ています。ということは、事前学習済みのBERTモデルで英検の問題は解けるのではないか、ということで実際に解いてみました。
* BERTの代表的な学習方法の1つに Masked Language Modelというものがあります。これは、実在する文章の一部をわざと隠したものを用意して、それをモデルに推定させるというものです。このタスクに適合していく過程で、モデルは前後の文脈を理解するようになっていくというのが手法の意図です。英検の穴埋め問題とよく似ているので、良いBERTモデルなら英検の問題にも対応できそうだ、という予想です。
実行環境はKaggleのノートブックです。また、同じコードはGistにも上げています。
事前学習済みBERTモデルの読み込み
huggingface/transformers ライブラリの、fill-maskパイプラインを利用します。デフォルトで、事前学習済みのRobertaモデルがロードされます。
from transformers import pipeline
model = pipeline("fill-mask")
# test
model(
"HuggingFace is creating a {} that the community uses to solve NLP tasks.".format(
model.tokenizer.mask_token))
# [{'sequence': 'HuggingFace is creating a tool that the community uses to solve NLP tasks.',
# 'score': 0.17927570641040802,
# 'token': 3944,
# 'token_str': ' tool'},
# {'sequence': 'HuggingFace is creating a framework that the community uses to solve NLP #tasks.',
# 'score': 0.11349428445100784,
# 'token': 7208,
# 'token_str': ' framework'},
# {'sequence': 'HuggingFace is creating a library that the community uses to solve NLP #tasks.',
# ...
パイプラインの仕様確認をしています。
-
mask_tokenを含んだ文字列を与えると、その穴埋め候補を出力します。 - スコアの高い順に5件出力されますが、この個数は
top_kオプションで指定できます。 -
token_strを見ると、単語の最初に空白を含んでいることがわかります。これは、空白なしで前のトークンと接続するような接尾語と区別するためのようです。 - デフォルトでは既定のボキャブラリ全体から最もスコアの高いものを選びますが、候補を
targetsオプションで指定することも可能です。
英検問題のデータ化
問題を、問題文 (text)、選択肢 (choices)、正答 (answer) からなる名前付きタプルで表現します。公開されている過去問 から、2021年第1回の問題を各級から10問取得しました。下記は5級の問題です。
from collections import namedtuple
Problem = namedtuple("Problem", "text choices answer")
eiken5 = [
Problem("A: What is your {}? B: Kazumi Suzuki.",
["hour", "club", "date", "name"], "name")
,Problem("I know Judy. She can {} French very well.",
["see", "drink", "speak", "open"], "speak")
,Problem("A: Are your baseball shoes in your room, Mike? B: No, Mom. They're in my {} at school.",
["window", "shop", "locker", "door"], "locker")
,Problem("My sister usually plays tennis {} Saturdays.",
["by", "on", "with", "at"], "on")
,Problem("My mother likes {}. She has many pretty ones in the garden.",
["sports", "movies", "schools", "flowers"], "flowers")
,Problem("Let's begin today's class. Open your textbooks to {} 22.",
["chalk", "ground", "page", "minute"], "page")
,Problem("Today is Wednesday. Tomorrow is {}.",
["Monday", "Tuesday", "Thursday", "Friday"], "Thursday")
,Problem("I usually read magazines {} home.",
["of", "on", "with", "at"], "at")
,Problem("A: It's ten o'clock, Jimmy. {} to bed. B: All right, Mom.",
["Go", "Sleep", "Do", "Sit"], "Go")
,Problem("A: Do you live {} Tokyo? B: Yes. It's a big city.",
["after", "with", "on", "in"], "in")
]
選択肢なしで解く
まずは、選択肢なしで解いてみます。ここでは、問題文をfill-maskパイプラインに当てはめて、上位5件に正答が含まれていれば正解とみなします。
import pandas as pd
def solve_without_choices(problems, top_k=5):
inputs = [p.text.format(model.tokenizer.mask_token) for p in problems]
res = model(inputs, top_k=top_k)
out = []
for p, r in zip(problems, res):
# suggested answers and the scores
suggested = [s["token_str"].strip() for s in r]
scores = [s["score"] for s in r]
suggested_scores = ",".join("%s(%.3f)" % (w,s) for w, s in zip(suggested, scores))
# location of answer
if p.answer in suggested:
position = suggested.index(p.answer) + 1
else:
position = -1
out.append((p.text, suggested_scores, position))
out = pd.DataFrame(out, columns=["problem", "scores", "answer_position"])
out["correct"] = (out["answer_position"] > 0)
return out
solve_without_choices(eiken5)
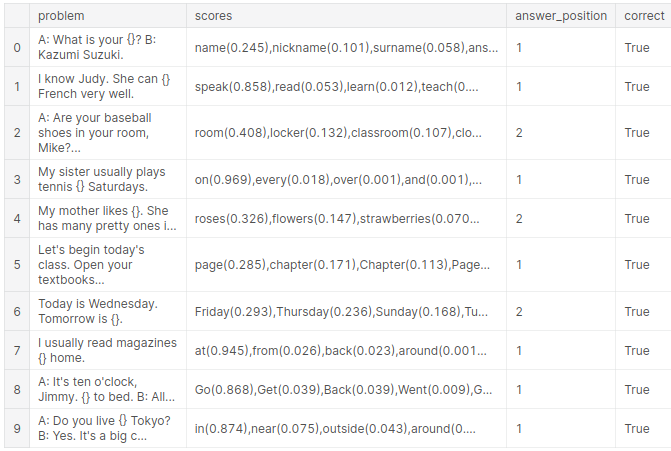
結果です。選択肢を与えていないにもかかわらず、第1・2候補あたりに正答が来ています。ただし、曜日を尋ねる問題で水曜日の翌日について「Friday」が第1候補に来ているのは惜しいです(上位5件に正答の「Thursday」も入っているので正解扱いにしています)。
選択肢つきで解く
次に、選択肢を与えてその中のベストを選ぶようにします。これは、選択肢を targetsオプションに指定することで可能です。実装の中で、選択肢の単語のはじめにスペースを加えることで、前のトークンとは独立の単語として扱うことを指定しています(スペースをつけないとSuffix扱いになります)。
def solve_with_choices(problems):
out = []
for p in problems:
text = p.text.format(model.tokenizer.mask_token)
targets = [" " + c for c in p.choices]
res = model(text, targets=targets)
words = [s["token_str"].strip() for s in res]
scores = [s["score"] for s in res]
suggested_scores = ",".join("%s(%.3f)" % (w,s) for w, s in zip(words, scores))
# location of answer
if p.answer in words:
position = words.index(p.answer) + 1
else:
position = -1
out.append((p.text, suggested_scores, position))
out = pd.DataFrame(out, columns=["problem", "scores", "answer_position"])
out["correct"] = (out.answer_position == 1)
return out
solve_with_choices(eiken5)
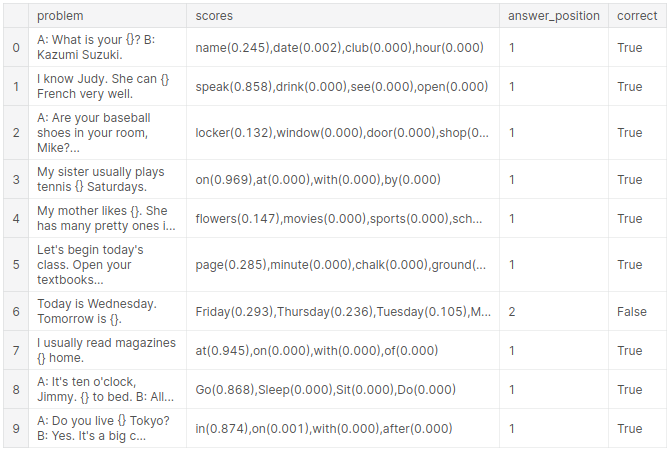
選択肢を与えると、1つを除いて正答を1番にあげるようになりました。
やはり水曜日の翌日をこたえる問題は「Friday」が選ばれてしまい残念ながら不正解となりました。
級が低いうちは完璧ではないもの概ね正解が得られるのですが、難しくなるとだんだん選択肢の単語が既定の辞書に含まれないケースが増えてきます。そういう場合、この方式では判定できなくなってしまいます。
例えば、こちらは準1級の問題です。
p = Problem(
"Some say the best way to overcome a {} is to expose oneself to what one fears. For example, people who are afraid of mice should try holding one.",
["temptation", "barricade", "phobia", "famine"], "phobia")
solve_with_choices([p])
# The specified target token ` barricade` does not exist in the model vocabulary. Replacing with `Ġbarric`.
# The specified target token ` phobia` does not exist in the model vocabulary. Replacing with `Ġph`.
「( )を克服するには、実際に恐れている対象に身をさらすとよい。」という問題で、答えは "phobia (恐怖症)" なのですが、これが辞書に登録されていないため正解を得ることができません。
1級では、10問中5問で正答が辞書に含まれていませんでした。
eiken1 = [
Problem("Cell phones have become a permanent {} in modern society. Most perople could not imagine living without one.",
["clasp", "stint", "fixture", "rupture"], "fixture")
,Problem("Colin did not have enough money to pay for the car all at onece, so he paid it off in {} of $800 a month for two years.",
["dispositions", "installments", "enactments", "speculations"], "installments")
,Problem("When she asked her boss for a raise, Melanie's {} tone of voice made it obvious how nervous she was.",
["garish", "jovial", "pompous", "diffident"], "diffident")
,Problem("The religious sect established a {} in a rural area where its followers could live together and share everything. No private property was allowed.",
["dirge", "prelude", "repository", "commune"], "commune")
,Problem("The famous reporter was fired for {} another journalist's work. His article was almost exactly the same as that of the other journalist.",
["alleviating", "plagiarizing", "inoculating", "beleaguering"], "plagiarizing")
,Problem("Now that the local steel factory has closed down, the streets of the once-busy town are lined with {} businesses. Most owners have abandoned their stores.",
["rhetorical", "volatile", "defunct", "aspiring"], "defunct")
,Problem("The ambassador's failure to attend the ceremony held in honor of the king was considered an {} by his host nation and made already bad relations worse.",
["elucidation", "affront", "impasse", "ultimatum"], "affront")
,Problem("US border guards managed to {} the escaped prisoner as he tried to cross into Canada. He was returned to jail immediately.",
["apprehend", "pillage", "exalt", "acclimate"], "apprehend")
,Problem("Anthony enjoyed his first day at his new job. The atmosphere was {}, and his colleagues did their best to make him feel welcome.",
["congenial", "delirious", "measly", "implausible"], "congenial")
,Problem(("A: I just learned I've been {} to second violin in the school orchestra. I knew I should've practiced more."
"B: Well, if you work hard, I'm sure you can get your previous position back."),
["relegated", "jeopardized", "reiterated", "stowed"], "relegated")
]
solve_with_choices(eiken1)
辞書に含まれていれば正解できているのですが、知らない場合は判定不能になってしまいます。

Perplexityの比較で解く
未登録の単語に対応するために、Perplexity指標の比較によるアプローチをとります。Perplexityは、自然言語処理においてよくモデルの精度指標としてよく用いられるものです(困惑が少ないモデルは文章をよく理解している、という解釈)。
ある文のPerplexityスコアを計算すると、そのトークンの並びが発生する確率(を変換したもの)になります(ただし、変換のため発生確率が高いほどスコアは小さい)。つまり、その文の自然さ(≒発生確率の高さ)の評価と解釈することができそうです。そこで、各選択肢を代入した文のPerplexityをそれぞれ評価して、スコアの最も低いものを選択すれば、モデルの考える最も適切な選択肢を得ることができます。
BERTモデルの中には、文のPerplexityを計算できるものがあります(参考)。これを利用して、同じ英検の問題を解きます。
なお、ここで使うのはPerplexity計算に対応しているGPT2モデルなので、上のfill-maskタスクで使用しているものとは違うモデルです。
import torch
from transformers import GPT2LMHeadModel, GPT2TokenizerFast
device = "cuda"
model_id = "gpt2-large"
model2 = GPT2LMHeadModel.from_pretrained(model_id).to(device)
tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
def solve_with_choices2(problems):
out = []
for p in problems:
texts = [p.text.format(c) for c in p.choices]
res = [] # store the perplexity score for each text
for t in texts:
tmp = tokenizer(t, return_tensors='pt')
input_ids = tmp.input_ids.to(device)
with torch.no_grad():
res.append(model2(input_ids, labels=input_ids)[0].item())
res = list(zip(p.choices, res))
res.sort(key=lambda a: a[1])
scores = ",".join("%s(%.3f)" % a for a in res)
answer_position = [s[0] for s in res].index(p.answer) + 1
out.append((p.text, scores, answer_position))
out = pd.DataFrame(out, columns=["problem", "scores", "answer_position"])
out["correct"] = (out.answer_position==1)
return out
solve_with_choices(eiken1)
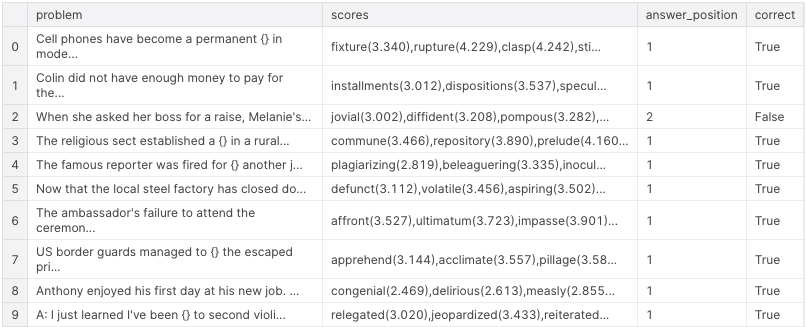
1級の問題の結果です。1つを除いて正しく判定することができました。
ちなみに、間違えた問題はこのようなものです。
When she asked her boss for a raise, Melanie's ( ) tone of voice made it obvious how nervous she was.
1. garish 2. jovial 3. pompous 4. diffident
後の文でメラニーはナーバスだった、となっていることから4番のdiffident(自信のない)が正解ですが、モデル的にはjovial(陽気な)の方が合うのではないかと判定しています。後につづく"tone of voice"とつながりが良いと見ているのかもしれません。
総合結果
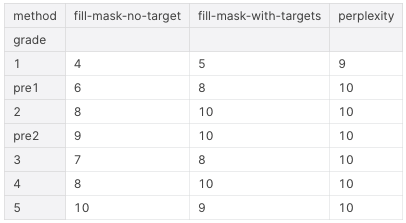
最終結果(正解数)です。単純に Masked Language Modelを使って穴埋めをする方法は、ある程度まで有効なのですが、選択肢がボキャブラリーに含まれない場合に対応できないという弱点があります。これは、特に1級のように単語の難易度が高い場合に顕著でした。一方で、文のPerplexityスコアを比較することで、より「自然」なものを選ぶ方式は、級を通じて概ね機能しているように見えます(70問中69問正解)。