英語で技術書を読もう:Fundamentals of Data Engineering 第20回 での報告資料です。輪読するのは Reis & Housley, Fundamentals of Data Engineering、 今回の担当箇所は、Chapter 8 の Improving Query Performance です("Queries on Streaming Data" の手前まで)。
クエリ性能改善ポイント
この章では、以下の6点が挙げられている。
- 結合方法とスキーマの最適化
- 実行計画のチェック
- 全走査の回避
- コミット処理の扱いの理解
- 古いデータの整理
- キャッシュの活用
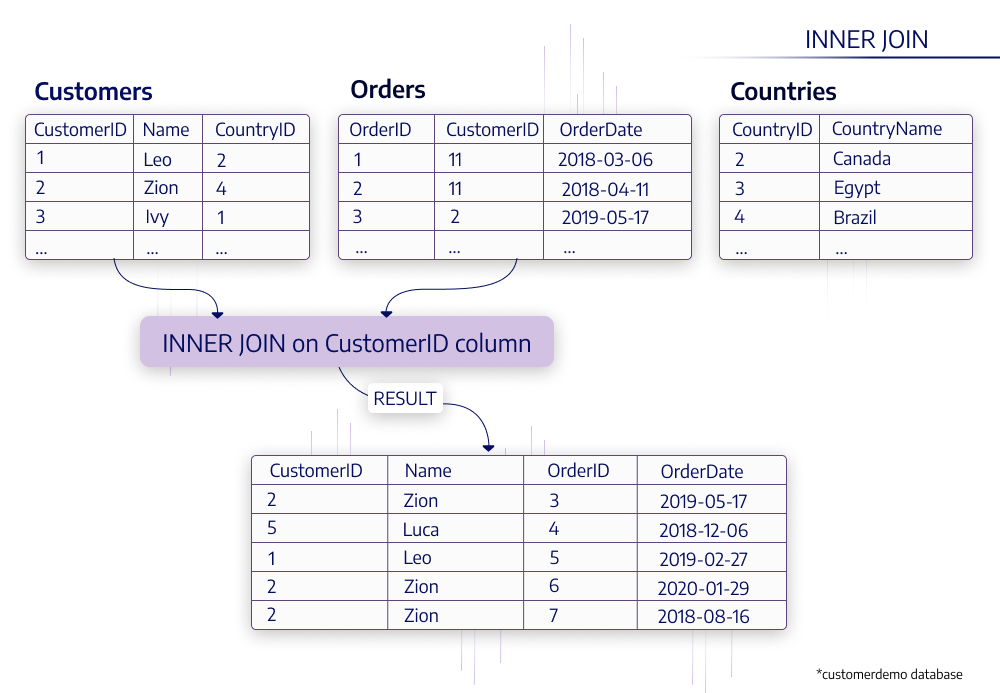
結合方法とスキーマの最適化
複数テーブルの結合は重めの処理なので、特に頻繁に行われる処理については対策しておくのがおすすめ
対策1: 事前結合
よく結合するテーブルがあるなら、前もって結合して1つのテーブルにしてしまえば良い、という対策。
結果としてデータの正規化が崩れて横に長いテーブルを保持することになるが、代わりに結合処理を省略できる。
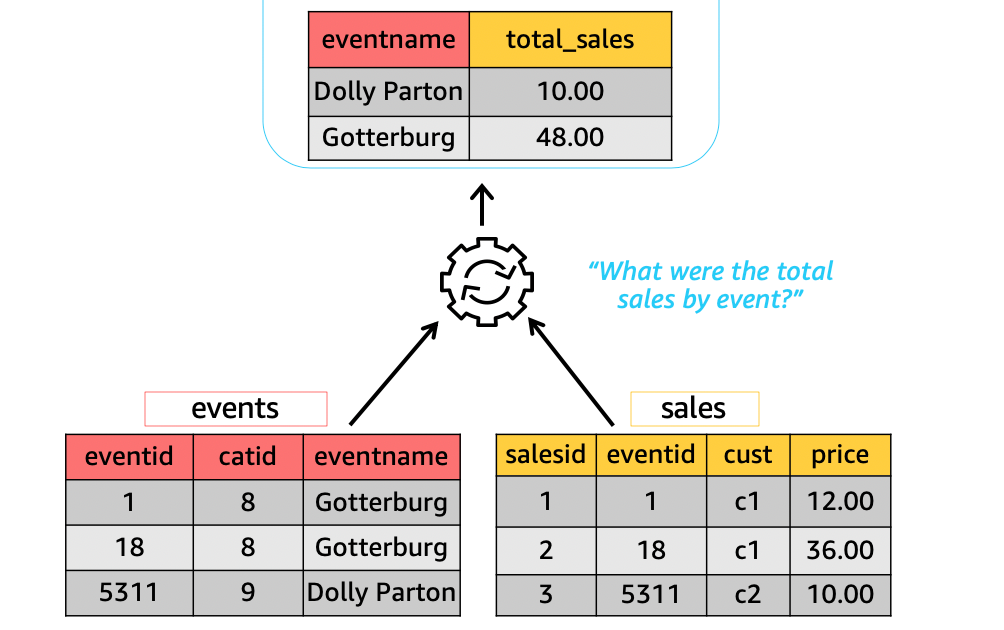
対策2:Materialized View
類似の方策としては、結合前のテーブルを維持しつつ、よくある結合処理を Materialized View として定義して、ユーザーにそれを使うよう促す、という手もある。
Materialized View: あるクエリをビューとして定義し、その結果を保持しておくもの。そのクエリが依存するテーブルに変更があった場合のみ再計算が行われ、そうでなければ保存した結果を再利用する。
対策3:インデックス
結合処理のキーになる変数を効率的に探索できると処理が効率化する場合があるので、よく結合キーに使われる変数にインデックスを貼っておくと良い。また、いくつかのDBシステムでは、変数の計算結果に対するインデックスをサポートしている。たとえば、
CREATE INDEX ( lower(city_name) )
のようにすると、lower(city_name) で結合したりフィルタしたりするときに利用される。
*「計算結果へのインデックス」についてはあえて取り上げるほどの話題かな、と思いました。
対策4:CTE (Common Table Expression)
入り組んだクエリを書く時に、サブクエリをネストさせる代わりに、CTE (Common table expression) を利用すると理解しやすくなる(でもこれ自体はパフォーマンス改善にはならないのでは?)。
たとえば、顧客ごとの訪問回数の分布を計算する時に
SELECT num_visists, COUNT(*) AS num_customers FROM ( SELECT customer, COUNT(*) AS num_visits FROM visits GROUP BY customer ) GROUP BY num_visitsのようにネストさせる代わりに、次のように書ける。この
WITH部分をCTEといいます。WITH visits_by_customer AS ( SELECT customer, COUNT(*) AS num_visits FROM visits GROUP BY customer ) SELECT num_visists, COUNT(*) AS num_customers FROM visits_by_customer GROUP BY num_visits
CTEは一般に中間テーブルを作成するよりも性能が優れる場合が多い。
実行計画のチェック
クエリの挙動を確認するためにEXPLAIN 文を使ってクエリの実行計画を確認する(特に、インデックスやキャッシュの利用が意図通りかなど)。
その他に、実行時に確認すべきこととして
- ディスク、メモリ、ネットワークの利用状況
- データの読込と計算処理の時間配分
- 実行時間、レコード数、データ走査量、データシャッフルの量
- 競合するクエリのリソース消費
- 同時実行クエリ数と利用可能な接続数
全走査の回避
大規模データの分析の場合に、データの全走査はなるべく避けたい。
列方向の限定
特に列志向テーブルの場合、抽出する列数を限定する(SELECT * はなるべく使わない)。
行方向の限定
- Clustering: レコードをある変数で並べ替えて格納する。すると、その変数での探索が効率化する
- Partitioning: レコードをある変数の値ごとに保存領域を変えて格納する。するとその変数での探索時に走査すべき量が削減される
- インデックス: 行志向テーブルの場合にある変数(または組み合わせ)に対してインデックスを作成する。するとその変数での探索が効率的になる。
コミット処理の扱いの理解
データベースに対する変更処理に対しては、コミットという概念がある。
トランザクション:データベースに対して行われる一連の処理のかたまり。
コミット:一連の処理が行った後にそれらの結果を反映させる処理のこと。コミット前の状態変化はデータに反映されない。
ACID特性: トランザクション・データベースの持つべき性質
- Atomicity (原子性):トランザクションが最小単位として扱われること。途中結果を反映しない。すべて実行されるか、すべて実行されないか。
- Consistency (一貫性):事前定義された条件に合致する場合のみ実行されること。
- Isolation (独立性):複数のトランザクションが同時に実行される時に、互いに干渉しあわないこと。
- Durability (永続性):障害時にもデータの復元が可能であること。
送金の例
参考: ACID特性とは?
- Aさんの口座残高が30万円以上であるか確認
- Aさんの口座残高を30万円減らし
- Bさんの口座残高を30万円増やす
という処理を考えると、途中のステップで止まってしまうとつじつまが合わなくなってしまうので1〜3を合わせてひとつの単位(トランザクション)として処理する必要がある → Atomicity.
また、同時に次のトランザクションが発生するとすると考えてみる。
- Aさんの口座残高が20万円以上であるか確認
- Aさんの口座残高を20万円減らし
- Cさんの口座残高を20万円増やす
もともとAさんの口座残高が40万円だった場合、両方が完全に同時に実行されると最終的にAさんの口座残高が足りなくなる問題が発生しうる。それを避ける仕組み(ロックをかけて順番待ちなど)が必要 → Isolation
*Consistency, Durability については、こういう例ではぴったりはまらなかったので割愛します。
各データベースでの扱い
PostgreSQL
- 書き込み時に行ロックがかかる(読込み、書込みともに)。
- 大量データの分析用途には最適化されていない。
BigQuery
- 読込み時には、最新のコミット済のスナップショットを読み込む。
- クエリ実行中の変更はコミットされるまで反映されない。
MongoDB
- 大量の書込み性能が高い
- トラフィックが多すぎて処理できない場合に、一部データを勝手に捨てる仕様
- IoTアプリなど、必ずしも全データを保持する必要がない場合に有用
- 金融取引など、全データが必要なケースには不適合
古いデータの整理
データは、コミットごとに追加されていき徐々にシステム内に古い情報が蓄積するので、これらは必要に応じて削除する (vacuum) 必要がある。
Snowflakeの場合
- ユーザーは明示にVacuum処理をしない。
- ユーザーは過去のスナップショットの保持期間を設定し、それに応じてシステムが古い情報を削除する
BigQueryの場合
- 保持期間として、7日間の固定幅を適用
Databricksの場合
- 手動で削除するまで無限に蓄積していく
Amazon Redshiftの場合
- ディスクの設定により制御、自動でVacuum処理が行われる
- ユーザーによる手動Vacuumも可能
PostgreSQL, MySQL の場合
トランザクション処理が積み重なると、次第にディスクを圧迫するので、エンジニアによるVacuum処理の理解が求められる。
キャッシュの活用
多くのOLAPデータベースでは、クエリ結果がキャッシュされる。
あるクエリが実行されるとその結果が返されると同時に、それがキャッシュに保存される。同じクエリがもう1度投げられた場合、それがキャッシュに存在すれば、同じ処理は実行されずに保存された結果が用いられる。