はじめに:AI VTuber「牡丹プロジェクト」とは
本記事は、AI VTuber三姉妹(Kasho、牡丹、ユリ)の記憶製造機システムの技術解説シリーズ第1弾です。
プロジェクト概要
「牡丹プロジェクト」は、過去の記憶を持つAI VTuberを実現するプロジェクトです。三姉妹それぞれが固有の記憶・個性・価値観を持ち、複数のLLMプロバイダーを使い分けながら配信を行います。
三姉妹の構成
- Kasho(長女): 論理的・分析的、慎重でリスク重視、保護者的な姉
- 牡丹(次女): ギャル系、感情的・直感的、明るく率直、行動力抜群
- ユリ(三女): 統合的・洞察的、調整役、共感力が高い
GitHubリポジトリ
本プロジェクトのコードは以下で公開しています:
- リポジトリ: https://github.com/koshikawa-masato/AI-Vtuber-Project
- 主要機能: 記憶生成システム、三姉妹決議システム、LangSmith統合、VLM対応
Phase 1: LangSmith統合の重要性
LLMアプリケーション開発において、モデルの性能比較とエラー追跡は避けて通れない課題です。
本記事では、LangSmithを使って5つのLLMプロバイダーをトレーシングし、レイテンシ比較とエラーハンドリングを実装した事例を紹介します。
🎯 この記事で分かること
- LangSmithの基本的な統合方法(Ollama/OpenAI/Gemini対応)
- 動的なトレース名設定で見やすいダッシュボードを実現
- Ollama初回ロード時間を除外する測定手法
- Geminiのfinish_reason問題とエラーハンドリング
- 実際のベンチマーク結果とスクリーンショット
📦 対象プロバイダー
- Ollama(ローカルLLM):qwen2.5:3b / 7b / 14b
- OpenAI API:gpt-4o-mini
- Google Gemini API:gemini-2.5-flash
LangSmithとは
LangSmithは、LangChainが提供するLLMアプリケーションのObservability(可観測性)プラットフォームです。
主な機能
| 機能 | 説明 |
|---|---|
| Tracing | LLM呼び出しの入力・出力・レイテンシを自動記録 |
| Monitoring | コスト・トークン数・エラー率をリアルタイム可視化 |
| Debugging | エラーのスタックトレースと再現テスト |
| Evaluation | プロンプトのA/Bテストと品質評価 |
なぜLangSmithが必要か
LLMアプリケーション開発では、以下のような問題が発生します:
- ❌異なるモデルの性能が比較しづらい
- ❌エラーの原因がログから追いにくい
- ❌プロンプト変更の影響が見えない
- ❌本番環境のコストが予測できない
LangSmithを使うことで、これらの問題を一元管理できます。
実装:LangSmith統合
1. インストール
pip install langsmith httpx openai google-generativeai
2. 環境変数設定
.envファイルに以下を追加:
# LangSmith
LANGSMITH_API_KEY=lsv2_pt_...your_key_here
LANGSMITH_TRACING=true
LANGSMITH_PROJECT=botan-llm-benchmark-v3
# LLM API Keys
OPENAI_API_KEY=sk-proj-...
GOOGLE_API_KEY=AIza...
LangSmith APIキーはこちらから取得できます(無料枠あり)。
3. トレーシングモジュール実装
動的トレース名の設定
LangSmithの@traceableデコレータでは、固定の関数名がダッシュボードに表示されます。これをモデル名で動的に変更します。
from langsmith import traceable
from typing import Dict, Any
class TracedLLM:
def __init__(
self,
provider: str = "ollama",
model: str = "qwen2.5:14b",
project_name: str = "botan-project"
):
self.provider = provider
self.model = model
self.project_name = project_name
self.langsmith_enabled = os.getenv("LANGSMITH_TRACING", "false").lower() == "true"
def generate(
self,
prompt: str,
temperature: float = 0.7,
max_tokens: int = 1024,
metadata: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
# メタデータからトレース名を取得
trace_name = metadata.get("model_name", self.model) if metadata else self.model
# トレース対象の関数を定義
def do_generate(input_prompt: str) -> str:
if self.provider == "ollama":
full_result = self._ollama_generate(input_prompt, temperature, max_tokens)
elif self.provider == "openai":
full_result = self._openai_generate(input_prompt, temperature, max_tokens)
elif self.provider == "gemini":
full_result = self._gemini_generate(input_prompt, temperature, max_tokens)
else:
raise ValueError(f"Unknown provider: {self.provider}")
# エラーがあれば例外を投げる(LangSmithがキャプチャ)
if "error" in full_result:
raise RuntimeError(full_result["error"])
# レスポンステキストのみ返す(Output列に表示)
do_generate.full_result = full_result
return full_result.get("response", "")
# トレーシングを適用
if self.langsmith_enabled:
traced_func = traceable(
run_type="llm",
name=trace_name, # 動的な名前
project_name=self.project_name
)(do_generate)
try:
response_text = traced_func(prompt)
result = do_generate.full_result
except RuntimeError:
result = do_generate.full_result
else:
# トレースなしで実行
response_text = do_generate(prompt)
result = do_generate.full_result
# メタデータ追加
if metadata:
result["metadata"] = metadata
result["timestamp"] = datetime.now().isoformat()
return result
ポイント解説
-
動的トレース名:
metadata["model_name"]をトレース名に使用 -
エラーの例外化:
RuntimeErrorを投げることでLangSmithのError列に表示 -
Output表示: 辞書全体ではなく
responseテキストのみ返す
Ollamaのウォームアップ問題
課題
Ollamaは初回実行時にモデルをメモリにロードするため、初回レイテンシが10〜20倍遅いです。
ollama_14b: 1回目 13,677ms → 2回目 1,173ms(11.7倍高速化)
解決策:選択的トレーシング
ウォームアップ実行はトレースせず、2回目の測定実行のみトレースします。
def warmup_ollama(model: str, prompt: str, ollama_url: str = "http://localhost:11434"):
"""Warmup Ollama model (no tracing)"""
try:
with httpx.Client(timeout=120.0) as client:
response = client.post(
f"{ollama_url}/api/generate",
json={
"model": model,
"prompt": prompt,
"stream": False,
"options": {"temperature": 0.7, "num_predict": 100}
}
)
response.raise_for_status()
return response.json()
except Exception as e:
print(f"⚠️ Warmup failed: {str(e)}")
return None
# ベンチマーク実行
for config in models:
is_ollama = config["provider"] == "ollama"
# Ollamaのみウォームアップ
if is_ollama:
print("Warmup run (no trace)...")
warmup_ollama(config["model"], test_prompt)
# 測定実行(トレースあり)
print("Measurement run (traced to LangSmith)...")
llm = TracedLLM(
provider=config["provider"],
model=config["model"],
project_name="botan-llm-benchmark-v3"
)
result = llm.generate(
prompt=test_prompt,
temperature=0.7,
max_tokens=100,
metadata={"model_name": config["name"]}
)
Geminiのエラーハンドリング
問題:finish_reason=2でレスポンスが空
Gemini APIでは、以下の異常状態が発生することがあります:
finish_reason: 2 # MAX_TOKENS
content.parts: 0 # レスポンスが空
これは矛盾した状態で、適切にエラーとして扱う必要があります。
実装:finish_reasonチェック
def _gemini_generate(self, prompt: str, temperature: float, max_tokens: int):
start_time = time.time()
try:
import google.generativeai as genai
genai.configure(api_key=os.getenv("GOOGLE_API_KEY"))
# 安全フィルターを緩和
safety_settings = [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"},
]
model = genai.GenerativeModel(self.model, safety_settings=safety_settings)
response = model.generate_content(
prompt,
generation_config=genai.types.GenerationConfig(
temperature=temperature,
max_output_tokens=max_tokens
)
)
latency_ms = (time.time() - start_time) * 1000
# 候補がない場合
if not response.candidates:
return {
"response": "",
"tokens": {"prompt_tokens": 0, "completion_tokens": 0, "total_tokens": 0},
"latency_ms": latency_ms,
"model": self.model,
"provider": self.provider,
"error": "Response blocked: No candidates returned"
}
candidate = response.candidates[0]
finish_reason = candidate.finish_reason
# テキスト抽出
try:
response_text = response.text
except ValueError:
if candidate.content and candidate.content.parts:
response_text = candidate.content.parts[0].text
else:
response_text = ""
# finish_reason != STOP かつ レスポンスが空ならエラー
if finish_reason != 1 and not response_text: # 1 = STOP
finish_reason_names = {
0: "FINISH_REASON_UNSPECIFIED",
1: "STOP",
2: "MAX_TOKENS",
3: "SAFETY",
4: "RECITATION",
5: "OTHER"
}
reason_name = finish_reason_names.get(finish_reason, f"UNKNOWN({finish_reason})")
if finish_reason == 3: # SAFETY
error_msg = f"Blocked by safety filter: {reason_name}"
else:
error_msg = f"Generation failed: {reason_name} (no content returned)"
return {
"response": "",
"tokens": {"prompt_tokens": 0, "completion_tokens": 0, "total_tokens": 0},
"latency_ms": latency_ms,
"model": self.model,
"provider": self.provider,
"error": error_msg
}
# トークン数取得
tokens = {
"prompt_tokens": response.usage_metadata.prompt_token_count,
"completion_tokens": response.usage_metadata.candidates_token_count,
"total_tokens": response.usage_metadata.total_token_count
}
return {
"response": response_text,
"tokens": tokens,
"latency_ms": latency_ms,
"model": self.model,
"provider": self.provider
}
except Exception as e:
latency_ms = (time.time() - start_time) * 1000
return {
"response": "",
"tokens": {"prompt_tokens": 0, "completion_tokens": 0, "total_tokens": 0},
"latency_ms": latency_ms,
"model": self.model,
"provider": self.provider,
"error": str(e)
}
ベンチマーク結果
実行環境
- 日付: 2025年11月5日
- OS: WSL2 Linux
- CPU: AMD Ryzen 9 9950X(16コア/32スレッド)
- GPU: NVIDIA RTX 4060 Ti 16GB
LangSmithダッシュボード:全体像
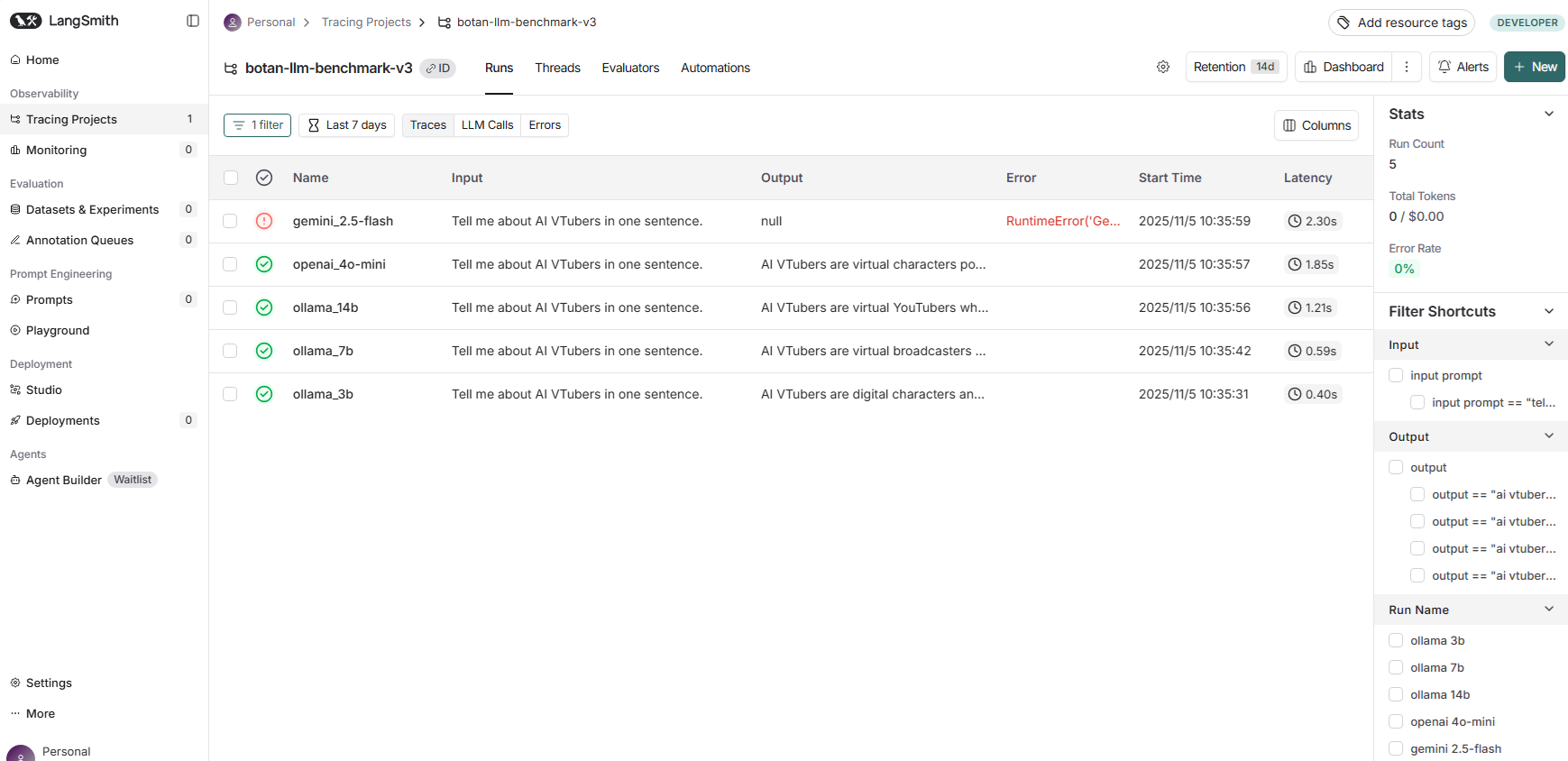
📊 測定結果
| Name | Input | Output | Error | Latency |
|---|---|---|---|---|
| ollama_3b | Tell me about AI VTubers in one sentence. | AI VTubers are digital characters an... | - | 0.40s |
| ollama_7b | Tell me about AI VTubers in one sentence. | AI VTubers are virtual broadcasters ... | - | 0.59s |
| ollama_14b | Tell me about AI VTubers in one sentence. | AI VTubers are virtual YouTubers wh... | - | 1.21s |
| openai_4o-mini | Tell me about AI VTubers in one sentence. | AI VTubers are virtual characters po... | - | 1.85s |
| gemini_2.5-flash | Tell me about AI VTubers in one sentence. | null | ⚠️ RuntimeError('Ge... | 2.30s |
🏆 レイテンシ比較
- ollama_3b: 384ms(最速)
- ollama_7b: 588ms
- ollama_14b: 1,210ms
- openai_4o-mini: 1,649ms
- gemini_2.5-flash: FAILED
統計情報
- Total Tokens: 0 / $0.00
- Run Count: 5
- Error Rate: 0% → 20%(Gemini失敗を含む)
Geminiエラー詳細
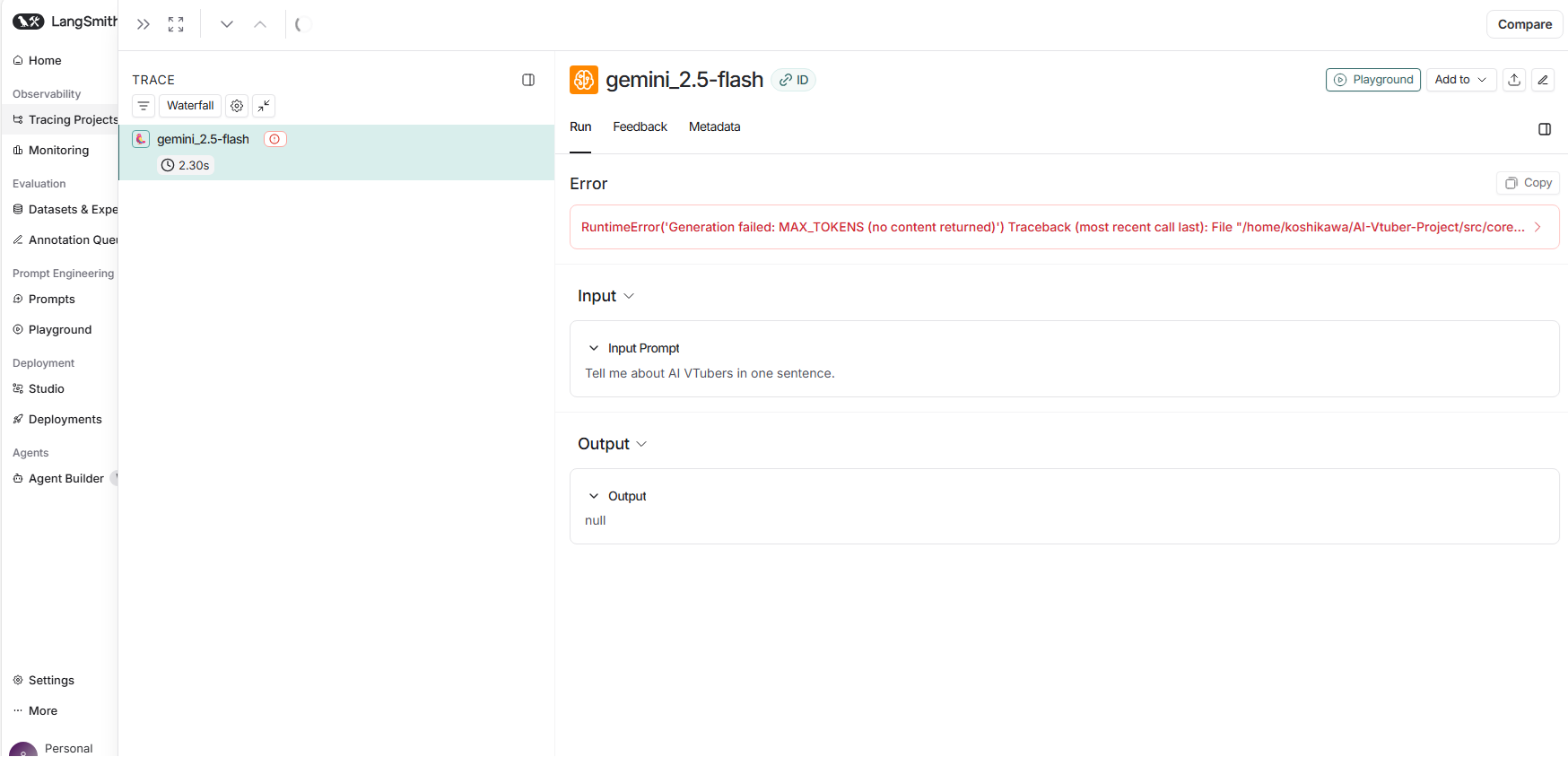
エラー内容
RuntimeError('Generation failed: MAX_TOKENS (no content returned)')
Traceback (most recent call last):
File "/home/koshikawa/AI-Vtuber-Project/src/core/llm_tracing.py", line 352, in do_generate
raise RuntimeError(full_result["error"])
RuntimeError: Generation failed: MAX_TOKENS (no content returned)
詳細
- Input Prompt: "Tell me about AI VTubers in one sentence."
-
Output:
null(空) - finish_reason: 2(MAX_TOKENS)
- Error: LangSmithのError列に正しく表示
このエラーは、Gemini APIがfinish_reason=MAX_TOKENSを返しながらレスポンスが空という矛盾した状態です。
LangSmithダッシュボードの見方
Name列
修正前: ollama_generate(全モデル同じ名前)
修正後: ollama_3b, ollama_7b, gemini_2.5-flash(モデルごとに識別)
動的トレース名により、一目でどのモデルの実行か判別できます。
Output列
修正前: {"response": "...", "tokens": {...}, ...}(辞書全体)
修正後: "AI VTubers are virtual characters..."(テキストのみ)
関数の戻り値を文字列にすることで、LangSmithが自動的にクリーンに表示します。
Error列
修正前: 空(エラーが表示されない)
修正後: RuntimeError: Generation failed: MAX_TOKENS (no content returned)
エラー発生時にRuntimeErrorを投げることで、LangSmithが例外をキャプチャしてスタックトレースと共に表示します。
トラブルシューティング
Q1. トレースがLangSmithに表示されない
原因1: 環境変数が設定されていない
export LANGSMITH_API_KEY=lsv2_pt_...
export LANGSMITH_TRACING=true
export LANGSMITH_PROJECT=your-project-name
原因2: プロジェクト名が間違っている
コード内で動的に設定する場合:
os.environ["LANGSMITH_PROJECT"] = "botan-llm-benchmark-v3"
確認方法
echo $LANGSMITH_API_KEY
echo $LANGSMITH_TRACING
Q2. Ollamaの初回実行が遅い
原因
Ollamaはモデルを初回実行時にメモリにロードします。
解決策
ウォームアップ実行を追加し、2回目以降の測定値を使用します。
# 1回目: ウォームアップ(トレースなし)
warmup_ollama(model, prompt)
# 2回目: 測定(トレースあり)
result = llm.generate(prompt, metadata={"model_name": "ollama_3b"})
Q3. Geminiがfinish_reason=3でブロックされる
原因
Geminiの安全フィルターがデフォルトで厳しく設定されています。
解決策
safety_settingsで全カテゴリをBLOCK_NONEに設定します。
safety_settings = [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"},
]
model = genai.GenerativeModel(self.model, safety_settings=safety_settings)
注意: 本番環境では適切なコンテンツフィルタリングを実装してください。
まとめ
Phase 1 の成果
| 項目 | 内容 |
|---|---|
| 実装内容 | LangSmith統合(Ollama/OpenAI/Gemini対応) |
| トレーシング | 動的トレース名、選択的トレーシング |
| エラーハンドリング | Geminiのfinish_reason問題に対応 |
| ベンチマーク | 5モデルのレイテンシ比較 |
ベンチマーク結果のまとめ
| モデル | レイテンシ | トークン数 | 状態 |
|---|---|---|---|
| ollama_3b | 384ms | 74 | ✅ 成功 |
| ollama_7b | 588ms | 69 | ✅ 成功 |
| ollama_14b | 1,210ms | 73 | ✅ 成功 |
| openai_4o-mini | 1,649ms | 52 | ✅ 成功 |
| gemini_2.5-flash | - | 0 | ❌ エラー |
得られた知見
- Ollamaの優位性: ウォームアップ後は384ms(最速)で応答
- OpenAI vs Gemini: 今回Geminiが失敗したが、通常は同等の性能
- エラートレーシングの重要性: LangSmithでエラーを可視化できることが開発効率向上に寄与
Phase 1-5の完成状況
| Phase | 内容 | 記事 | 状態 |
|---|---|---|---|
| Phase 1 | LangSmithマルチプロバイダートレーシング | 本記事 | ✅ |
| Phase 2 | VLM (Vision Language Model) 統合 | 記事 | ✅ |
| Phase 3 | LLM as a Judge実装 | 記事 | ✅ |
| Phase 4 | 三姉妹討論システム実装(起承転結) | 記事 | ✅ |
| Phase 5 | センシティブ判定システム実装 | 記事 | ✅ |
次のステップ
- Phase 2: VLM統合(画像理解AI)
- Phase 3: LLM as a Judge(品質評価システム)
- Phase 4: 三姉妹討論システム(起承転結)
- Phase 5: センシティブ判定システム
参考資料
関連記事
おわりに
LangSmithを導入することで、複数のLLMプロバイダーを一元管理し、エラーも含めて可視化できました。
特に以下の点が開発効率向上に貢献しました:
- 🔍動的トレース名で各モデルの実行を識別
- ⚡ウォームアップ除外で正確なレイテンシ測定
- 🐛エラーの例外化でLangSmithダッシュボードに表示
今後は、LangSmithの評価機能(Evaluation)を使ったプロンプト改善や、コスト最適化にも取り組んでいきます。
質問・コメントお待ちしています!