畳み込みレイヤーが10層というとても小さな畳み込みニューラルネットワーク(CNN)でCIFAR-10のValidation accuracyを9割達成しました。ただ結構ギリギリでした。
きっかけ
前回の投稿であまり調べずに「CIFAR-10ぐらいのデータ数ならそこまで深いモデルは普通いらない」と言ってしまったら、「嘘でしょ」みたいな反応をされてしまったので、「小さいモデルでCIFAR-10のValidation Accuracy9割ぐらい出しておかないとまずいよなぁ」と考えた次第です。達成できましたがかなりギリギリでした。
CNNの深さについて
Kerasの組み込みモデル一覧の深さを見ると、組み込みモデルの中でVGG16、19が一番浅いモデルであると言えます。ただ、Kerasの深さの定義はConv以外の層(例:Pooling)も含むので、Conv+Denseだけの数を見ると文字通りVGG16は16層で、VGG19は19層です。今回のモデルの深さの定義はConv+Denseの数とします(BatchNormやPoolingの数は含まない)。
より新しいモデルとしては、ResNet-50はショートカット構造を含むものの50層、DenseNetは層のスタッキングを含みますが一番軽いもので121層と、新しいモデルになるにつれてどんどん深くなっていく傾向があります。当然深くなればなるほど分類性能は良くなるので、CNNを作っている人はモデルを深くしたがります。
ただ、これにはCNNの主戦場がCIFARではなくImageNetであることに気をつける必要がありそうです。有名なCNNのモデルの論文を見ても大抵ImageNetのデータセットに対する言及はありますし、データ数がCIFARとImageNetでは桁が違います。CIFARが5万なのに対して、ImageNetは1400万以上もありますので、何百層という深いモデルを作ってもそれに見合ったデータ数が得られ、オーバーフィッティングを起こしにくいといえるでしょう。転移学習する場合はまた違うかもしれませんが、1から訓練させる場合は頭の片隅に置いておいてもいいと思います。
VGG16より古いモデルとして、ディープラーニングを力を知らしめた「AlexNet」というモデルがあります。こちらは5層の畳み込み層と3層の全結合層からなるので、AlexNetは8層であると言えます。AlexNetではLocal Response Normalizationという現在ではあまり用いられない独特のテクニックを用いることで、CIFAR-10に対するエラー率11%(精度89%)を達成しています1。
今回作るモデルは、9層の畳み込みと1層の出力層からなる10層のモデルです。BatchNormといったAlexNetにはなかったテクニックを使うことで、Validation Accuracy9割を達成できました。
モデル
以下のようなモデルを作りました。paddingは入れていません。Conv1x1→Conv3x3→Conv5x5を1セットとして、3セット繰り返します。1セット目と2セット目の間だけダウンサンプリングのMaxPoolingを入れています。3セット終わったら全結合化し、即softmaxとします。畳み込み層が3×3=9層、全結合層が出力層の1層となり、計10層のモデルです。
ドロップアウトは各セットの終わりに1回ずつ入れ、ドロップアウトの値は0.25としました。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 64) 256
_________________________________________________________________
batch_normalization_1 (Batch (None, 32, 32, 64) 256
_________________________________________________________________
activation_1 (Activation) (None, 32, 32, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 30, 30, 64) 36928
_________________________________________________________________
batch_normalization_2 (Batch (None, 30, 30, 64) 256
_________________________________________________________________
activation_2 (Activation) (None, 30, 30, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 26, 26, 64) 102464
_________________________________________________________________
batch_normalization_3 (Batch (None, 26, 26, 64) 256
_________________________________________________________________
activation_3 (Activation) (None, 26, 26, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 26, 26, 64) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 64) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 13, 13, 128) 8320
_________________________________________________________________
batch_normalization_4 (Batch (None, 13, 13, 128) 512
_________________________________________________________________
activation_4 (Activation) (None, 13, 13, 128) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 11, 11, 128) 147584
_________________________________________________________________
batch_normalization_5 (Batch (None, 11, 11, 128) 512
_________________________________________________________________
activation_5 (Activation) (None, 11, 11, 128) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 7, 7, 128) 409728
_________________________________________________________________
batch_normalization_6 (Batch (None, 7, 7, 128) 512
_________________________________________________________________
activation_6 (Activation) (None, 7, 7, 128) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 7, 7, 128) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 7, 7, 256) 33024
_________________________________________________________________
batch_normalization_7 (Batch (None, 7, 7, 256) 1024
_________________________________________________________________
activation_7 (Activation) (None, 7, 7, 256) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 5, 5, 256) 590080
_________________________________________________________________
batch_normalization_8 (Batch (None, 5, 5, 256) 1024
_________________________________________________________________
activation_8 (Activation) (None, 5, 5, 256) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 1, 1, 256) 1638656
_________________________________________________________________
batch_normalization_9 (Batch (None, 1, 1, 256) 1024
_________________________________________________________________
activation_9 (Activation) (None, 1, 1, 256) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 1, 1, 256) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 2570
=================================================================
Total params: 2,974,986
Trainable params: 2,972,298
Non-trainable params: 2,688
________________________________________________________________
コード全体はこちらにあります:https://gist.github.com/koshian2/3d99ff54715de586f3ac050b32fa1402
結果
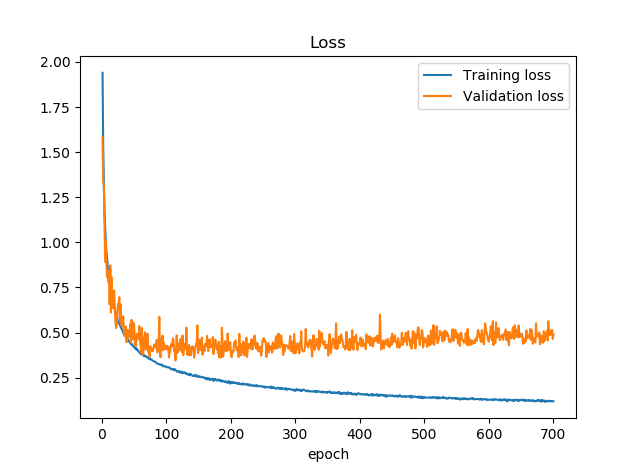
上記のコードを700epoch実行した結果がこちらです。Training/Validation Lossから。ValidationデータはCIFAR-10のテストデータをValidationとしました。
続いて精度はこちら。
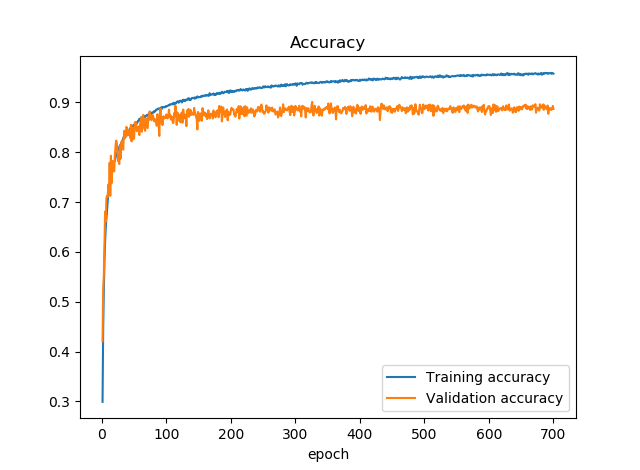
Training accuracyが0.96ぐらい出ているのに対して、Validation accuracyが9割越えないかぐらいで推移しています。もう少し拡大してみましょう。
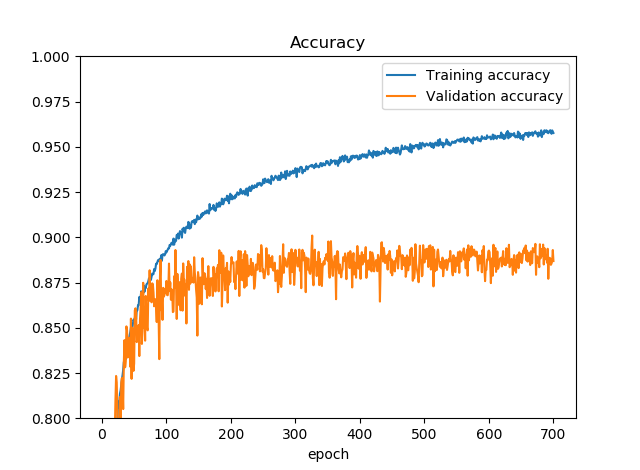
300epoch付近で一瞬Validation Accuracyが0.9を越えているように見えます。さらに拡大します。0.9に補助線を引きました。
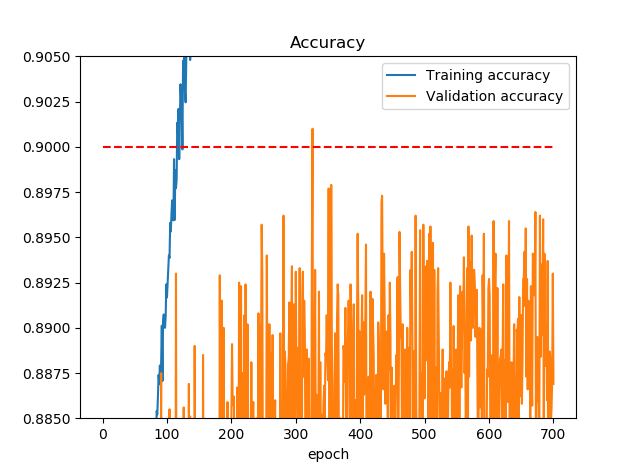
確かに越えています。ログでは
Epoch 326/700
391/390 [==============================] - 54s 138ms/step - loss: 0.1731 - acc: 0.9401 - val_loss: 0.3669 - val_acc: 0.9010
「val_acc: 0.9010」。一瞬ではありますが見事、Validation Accuracy9割越えを達成しました。Validation Accuracy88%からはほぼガチャなので、Google Colabの制限時間12時間ぎりぎり回しました。
ボツになったアイディア
9割越えになるまでにいろいろ試してみたアイディアです。
(1) Conv:5x5→3x3→1x1の順に畳み込み、ドロップアウトなし、水増し(Data Augmentation)なし
9割越えたモデルでは1x1→3x3→5x5とカーネル数が少ない順に畳み込みをしましたが、はじめはカーネルが大きい順に畳み込みをしました。はじめはドロップアウトなし、水増しなしで行いました。
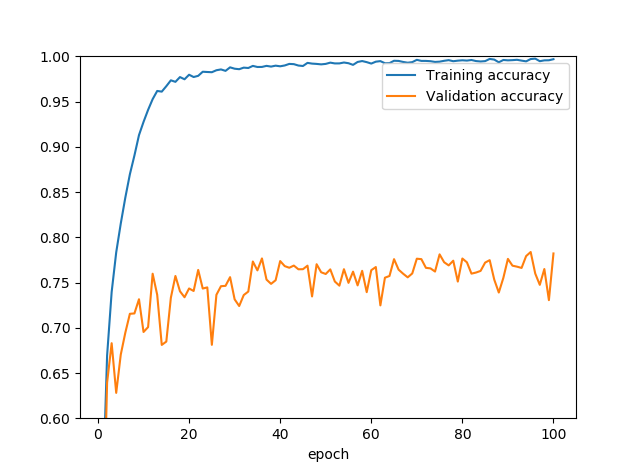
Trainingのほうは100%近いのですが、Validation Accuracyが75%前後。25%もオーバーフィッティングしています。
(2) (1)に水増しを加える
(1)のConv:5x5→3x3→1x1の順に畳み込み、ドロップアウトなしに水増し(Data Augmentation)を加えました。
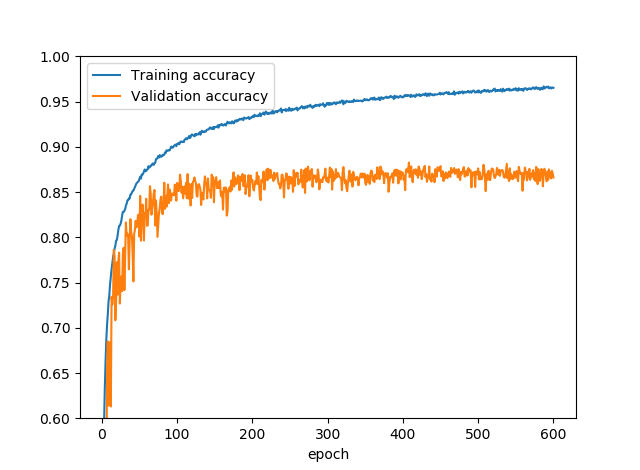
これで(Validation)精度が85%近くなりました(約10%の上昇)。水増しのコードは次のとおりです。
datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
このときはチャンネルシフトを入れませんでした。このモデルの場合10層とモデルが小さかったので、ドロップアウトよりも水増しのほうが精度の上昇とオーバーフィッティングの解決を両立できたように感じられました。
ドロップアウトは結果的にモデルを小さくするのに対して、水増しは擬似的ながらデータ数を増やす(離散的なデータをより連続的にする効果があるので)、このような小さなモデルに対しては、水増しのほうがより”攻め”のオーバーフィッティング解決策であると思いました。
(3) (2)にドロップアウト20%を加える
(2)にドロップアウト20%を加えました。ドロップアウトのタイミングは完成版と同じです。
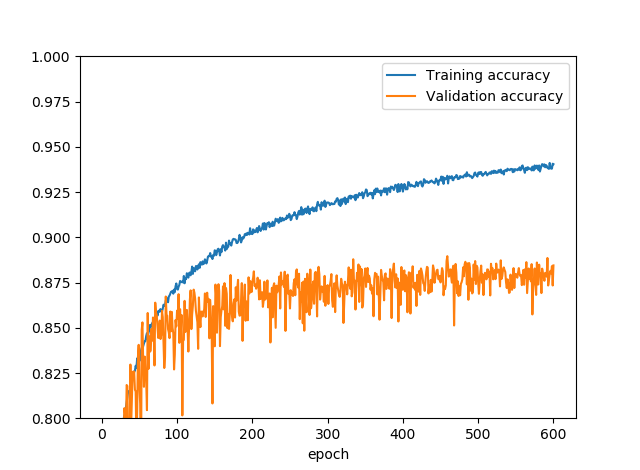
2.5%程度精度を押し上げましたが、これでもまだ9割には足りません。確かこれと同時に水増しのチャンネルシフトを入れたような気がしますが、ちゃんと記録してなかったので失念しました。すみません。
(4) (3)のドロップアウトを50%にする
(3)がまだオーバーフィッティングしていたので、ドロップアウトの値を全て50%にしました。
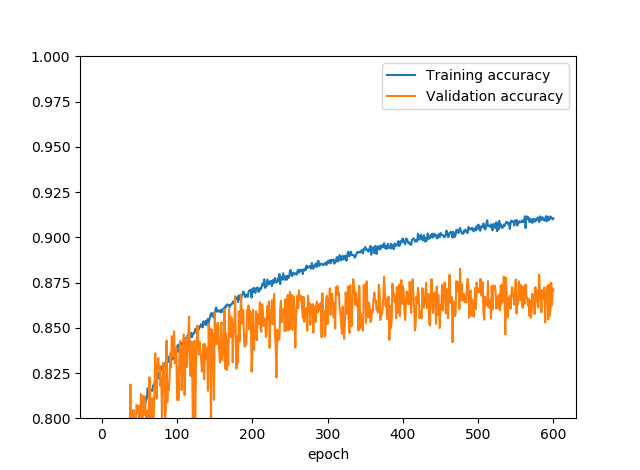
確かにオーバーフィッティングは解消されたのですが、ドロップアウトが強すぎてモデルが小さくなってしまい、精度が下がっちゃいましたね。今回の場合、ドロップアウトは味付け程度で使わないとダメでしょう。
(5) (3)の畳み込みの順番を1x1→3x3→5x5にする
DenseNetの論文を読んでいたら、1x1→3x3の順で畳み込みをしていたので、「あれ、カーネルが小さい順に畳み込みしたほうがいいの?」と思い試してみました。
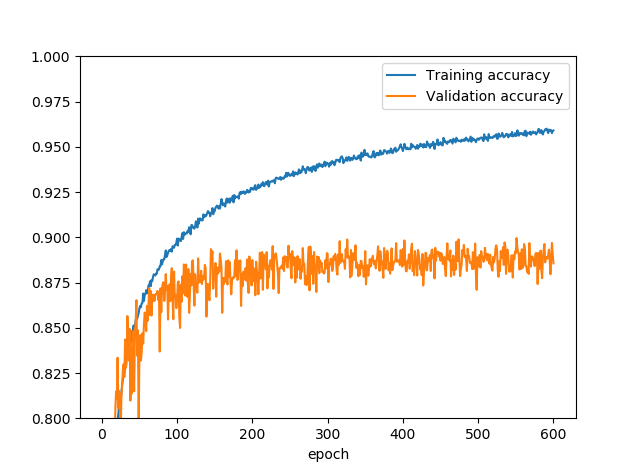
降順で畳み込みするより、昇順で畳み込みしたほうが精度が1~2%良かったです。確かにこれはDenseNetの論文の通りです(DenseNetのようなスタッキング構造は実装していません)。精度0.8996という非常に惜しい値が出て、9割が射程圏内に入ってきました。
(6) (5)のドロップアウトを20%→25%にする
これが先程示した完成版です。(5)の段階であともうちょっとだったので、ドロップアウトのパラメーターを気持ち増やして味付けをしました。これで88~89%のValidation Accuracyのガチャをしたところ、運良く700epoch中1回9割越えができました。
まとめ
- 10層のCNNでもCIFAR-10のValidation Accuracyをかろうじて9割達成できた
- Data Augmentation強い。今回の場合、ドロップアウトよりも全然こっちのほうが効いた。
- でもやっぱり小さなモデルはチューニング頼りになってつらい。計算リソースが許せば大きいモデルのほうが楽。
以上です。とりあえずこんな小さなモデルでもCIFAR-10で9割いけた!ということが示せてほっとしました。