2021年のディープラーニング論文を1人で読むAdvent Calendar22日目の記事です。今日読む論文は「不均衡データの対策」その2です。不均衡対策はこのアドベントカレンダーの18日目に「Influence-balanced loss(IBLoss)」を紹介しましたが、ほぼ同じ著者です(ソウル大学校+NAVER AI Lab)。不均衡データの問題点は今回省略するので、問題のアウトラインが知りたい方は18日目の記事を参照してください。
IBLossが損失関数(サンプル単位で重みを付け直してロス計算)のアプローチでしたが、これはデータレベルのアプローチで、オーバーサンプリングとCutMixを組み合わせます。単純明快ながら強力な性能を示します。今年の12/1にarXivに投稿されたできたてホヤホヤの論文です(本記事執筆時点では、どこのカンファにも出ていないです)。コードは現在擬似コードのみですが、CutMixの延長なので論文読んだだけで実装できる方と多いと思います。
- タイトル:The Majority Can Help The Minority: Context-rich Minority Oversampling for Long-tailed Classification
- URL:https://arxiv.org/abs/2112.00412
- 出典:Seulki Park, Youngkyu Hong, Byeongho Heo, Sangdoo Yun, Jin Young Choi; arXiv:2112.00412 [cs.CV]
- コード:(これから公開)
オーバーサンプリングしてCutMixすればいい
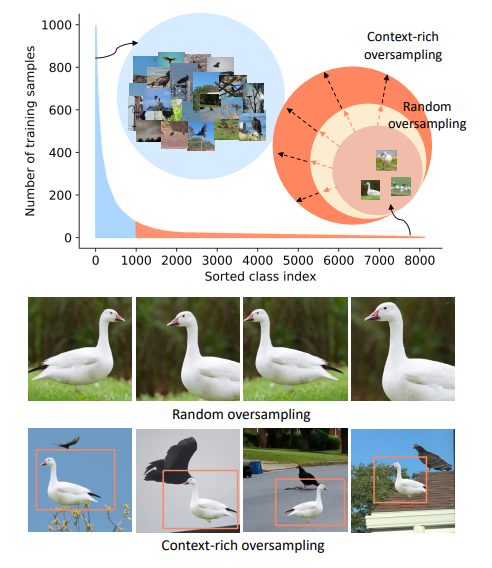
例えば、このガチョウが少数クラスのデータとしましょう。従来のオーバーサンプリングはただガチョウのデータをData Augmentationを通じて複製するだけでした(Random Oversampling)。本手法(CMO)は、
- CutMixの背景側は普通にサンプリング(バッチを流すだけ)
- CutMixの前景側(貼り付ける側)をオーバーサンプリング(クラスあたりのサンプル数の逆数に応じた割合でサンプリング)
とします。これだけです。
擬似コード
擬似コードでは次の通りです。

$x, y$は画像とラベルです。オーバーサンプリングしないデータセットを$D_{i=1}^N$、オーバーサンプリングするデータセットを$\tilde{D}_{i=1}^N\sim Q$とします(擬似コードは文字がかぶって見づらいかもしれない)
- 背景の$(x_i^b, y_i^b)$は$D_{i=1}^N$からサンプリング
- 前景の$(x_i^f, y_i^f)$は$\tilde{D}_{i=1}^N$からサンプリング(オーバーサンプリングする)
- 7行目~9行目はCutMix(一瞬MixUpっぽく見えるが、$\mathbf{M}$がCutMixのマスク)
もっと詳細なコード
論文のAppendixに載ってました。あくまでPyTorchっぽい擬似コードです。
# original loader: data loader from original data distribution
# weighted loader: data loader from minor-class-weighted distribution
# model: any backbone network such as ResNet or multi-branch networks (RIDE)
# loss: any loss such as CE, LDAM, balanced softmax, RIDE loss
for epoch in Epochs:
# load a batch for background images from original data dist.
for x b, y b in original loader:
# load a batch for foreground from minor-class-weighted dist.
x f, y f = next(weighted loader)
# get coordinate for random binary mask
lambda = np.random.uniform(0,1)
cx = np.random.randint(W) # W: width of images
cy = np.random.randint(H) # H: height of images
bbx1 = np.clip(cx - int(W * np.sqrt(1. - lambda))//2,0,W)
bbx2 = np.clip(cx + int(W * np.sqrt(1. - lambda))//2,0,W)
bby1 = np.clip(cy - int(H * np.sqrt(1. - lambda))//2,0,H)
bby2 = np.clip(cy + int(H * np.sqrt(1. - lambda))//2,0,H)
# get minor-oversampled images
x b[:, :, bbx1:bbx2, bby1:bby2] = x f[:, :, bbx1:bbx2, bby1:bby2]
lambda = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (W * H))# adjust lambda
# output (x f is attached to x b)
output = model(x b)
# loss
losses = loss(output, y b) * lambda + loss(output, y f) * (1. - lambda)
# optimization step
losses.backward()
optimizer.step()
オーバーサンプリングはクラスあたりのサンプル数の逆数
前景側のオーバーサンプリング$Q$のやり方に工夫があります。サンプルの抽出確率はクラス単位で決めます。全部で$C$クラスあるとしましょう。累乗の係数を$r$、クラス$C=k$のときの、クラス単位の抽出確率を$q(r, k)$とすると、
$$q(r, k)=\frac{1/n_k^r}{\sum_{k'=1}^c 1/n_{k'}^r}$$
ここで$n_k^r$は$n_k$の$r$乗を示します。実験では$r=1$が良かったとのことです。
他の抽出確率の検討
$r=1$、$r=1/2$、$n_k^r$のかわりに、データセット全体のサンプル数$N$、$\beta=(N-1)/N$とし、
$$E(k)=\frac{(1-\beta^{n_k})}{(1-\beta)}$$
とする方法です。CIFAR-100-LTという不均衡(ロングテール)にしたCIFAR-100を使って調べた結果が次の通りです。不均衡係数は100です。ちなみに不均衡係数$\rho=\max_k{{n_k}}/\min_k{{n_k}}$です。
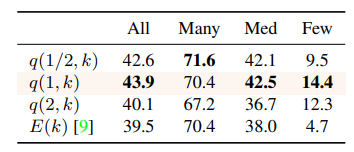
クラスあたりのサンプル数が「100、25、5」であるデータセットに対する抽出確率は以下の通りです。
| クラス名 | A | B | C |
|---|---|---|---|
| サンプル数 | 100 | 25 | 5 |
| q(1/2, k) | 13.4% | 26.8% | 59.9% |
| q(1, k) | 4.0% | 16.0% | 80.0% |
| q(2, k) | 0.2% | 3.8% | 95.9% |
| E(k) | 5.5% | 16.8% | 77.8% |
$q(r, k)$の場合は、$r$が小さいと偏りがマイルドになります。$r=2$のように大きくしすぎると逆効果であることがわかります。$r$はハイパラなので、CVでちゃんと調べてもいいですし、面倒だったら$r=1$で決め打ちしても良さそうです。
実験
CIFAR-100-LT
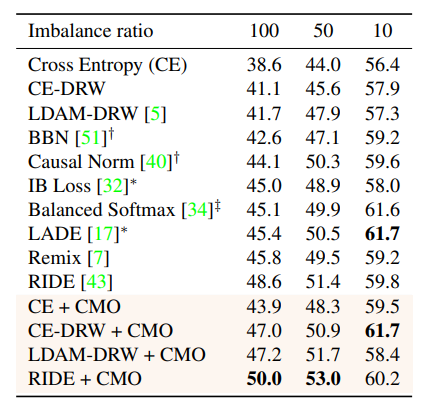
CE単独→CE+CMOで5~7%のゲイン(値はおそらくmacro accuracy)。同一著者のIB Lossがもうあんな雲の下に(ICCV2021の論文だったのに!)。ここ最近不均衡データ対策の研究が盛んなのかもしれません。この表から不均衡対策のサーベイができそうですね。
あくまでCMOはデータレベルのアプローチなので、損失関数ベースのやり方と併用できます。お好きなロスをご自由に使ってくださいというスタンスです。
ちなみにサンプリング方法を変更しても、先行研究に対し一貫した優位性を見せています。同じくCIFAR-100-LTです。この著者強すぎでは?
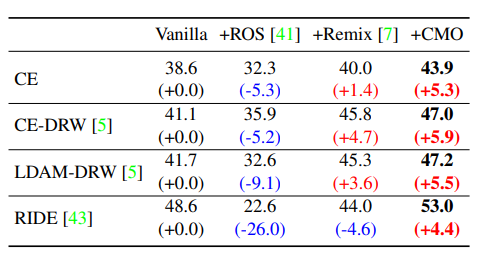
ImageNet-LT
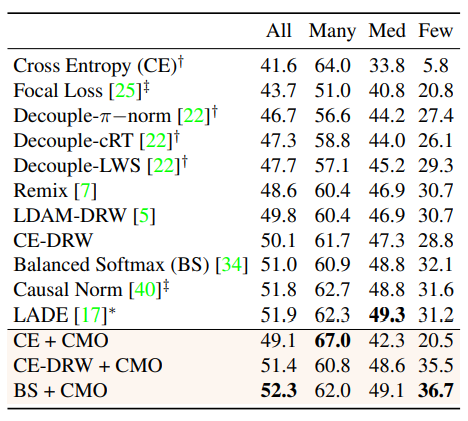
CutMix自体に正則化効果があるため、Fewなクラスはもちろんのこと、Manyなクラスでも精度が上がるという虫のいい話すら起こりえます。Balanced Softmaxあたりが良さそう(IB Lossを著者自ら切り捨てるスタイル、好き)
iNaturalist 2018
Longtailなデータセットの定番。モデルを大きくしてもCMOは強い

CMOじゃなくてCutMixが効いてるだけでしょ?
→そんなことはない。ちゃんとCMOが効いている
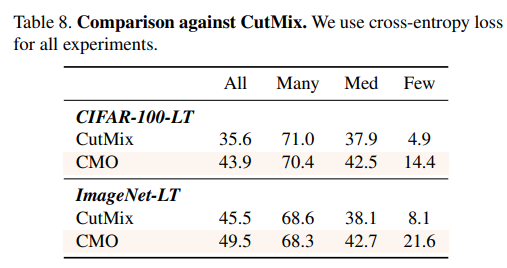
むしろ前景と背景で異なる分布からサンプリングするのが重要。
別に前景を偏ってサンプリングしなくてもいいでしょ?
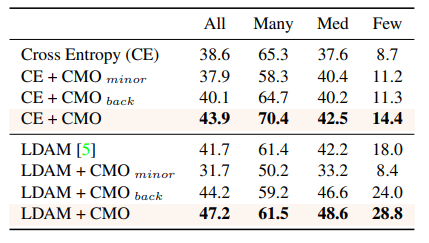
- $CMO_{minor}$:前景と背景を両方オーバーサンプリング(偏ったサンプリング)
- $CMO_{back}$:背景をオーバーサンプリングし、前景は通常
結局、前景をオーバーサンプリングしたほうが一貫して精度が出る(相当違う)。CIFAR-100で検証。$CMO_{back}$が悪化した理由は、CutMixの背景画像は、前景のオブジェクトと重なっている可能性が高いため、少数クラスの情報が失われたから。
Data Augmentation変えたらもっと良くなるでしょ?
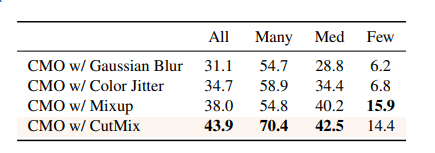
CutMixがほとんどのケースで良かった。ぼかしやJitterのようなピクセルレベルの変換はあまり効かない。MixUpは2枚の画像の合成はするが、サンプルの役割を区別しないため、コンテクストやパッチの情報源が制限される。CutMixは多様な画像を生成可能。
まとめと感想
この論文では「前景を少数クラスから偏ってとるようにオーバーサンプリングし、背景は通常サンプリングでCutMixすれば、不均衡対策としてSoTA」という単純明快な結論を出しています。実験結果もかなり頑強で、他の不均衡対策した損失関数の選択は好みあれど、CMOの優位性は一貫しています。「すぐできる対策」としてはこれ以上ないぐらい簡単だと思います。
不均衡対策の論文が最近の流行りみたいで、この論文を読むだけで相当先行研究載っています。CMOはあくまでサンプリング方法で、ロス選択は先行研究が使えるので、不均衡対策のサーベイとして読むといい感じになりそうです。ここ最近急に不均衡対策が結果を伴った成果を出すようになった気がします。
なお、この論文は「NAVER AI Lab」のインターンの成果物とのことです。インターンでこんな激強論文出してくるのやばすぎますね。個人的にこの著者お気に入りです。
告知
このアドベントカレンダーが本になりました!
https://koshian2.booth.pm/items/3595424
Amazonでも扱いあります詳しくは👉 https://shikoan.com