画像や音声分類の汎化性能を向上させる目的で開発されたBetween-class Learning(BC-learning)というData Augmentationの効果をKerasで確かめます。「2つの画像を混ぜる」というアプローチを取るData Augmentationです。**10層CNNでCIFAR-10に対して94.59%**という素晴らしい性能を確認することができました。
BC-Learningとは?
2つの画像を混ぜるというData Augmetation。これにより、決定境界がより平滑化され、オーバーフィッティングが解消され、ValidationやTestでの汎化性能が向上する。
BC-learningのもともとの着想は音声認識からでした。人間でも、例えば英会話で2つの音を同時に聞くことで学習効率が向上する、というのは耳にします。2つの画像を混ぜても人間には特に意味はないかと思われますが、音声も画像もCNNにとっては入力を波形データのように取り扱っているため、「画像を混ぜても機械にとっては意味があるよ」というのがBC-Learningの主張です。
ちなみにBC-Learningを作ったのは日本人で、東京大学と理研の方の論文です。Chainerのオフィシャルな実装が公開されています。
論文:Yuji Tokozume, Yoshitaka Ushiku, Tatsuya Harada. Between-class Learning for Image Classification. https://arxiv.org/abs/1711.10284
オフシャル実装:https://github.com/mil-tokyo/bc_learning_image
Mixupとの違い
「2つの画像を混ぜる」というData Augmentationには、Mixupのほうが有名かと思います。論文が出たのも同じ2017年で、Mixupが2017年10月、BC-Learningが2017年11月なので時期的にはかなり近いです。
ただし、MixupとBC-Learningにはいくつか明確な違いがあります。
1.BC-Learningは異なるクラスの画像を混ぜる
Mixupはただ2枚の異なる画像を混ぜるだけなのに対して、BC-Learningは異なるクラスの異なる2枚の画像を混ぜます。論文では「2つのクラスのサンプルを混ぜることでFisher’s criterionが向上し、正則化効果が得られる」とあるので、意識的に異なるクラスを混ぜたほうがいいのではないかなと思います。
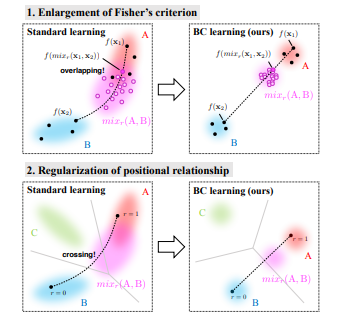
Fisher’s criterionというのは専門的で難しいですが、異なるクラスの画像を混ぜて中間のクラスを作り出すことで、第3のクラスの決定境界がそこに割り込まないようにする。図に中では交差した(crossing)な境界を作り出さない、つまりオーバーフィッティングしにくくするという程度で理解で十分ではないでしょうか。このように尖った(局所的な)決定境界になってしまうことが、オーバーフィッティングなのですから。Fisher’s criterionというのはあくまでこれを定量的に説明するための手段にすぎないのではないかと思います。
2.損失関数にKL-Divergenceを使う
これは明確にMixupと異なるところです。KL-Divergenceというとぎょっとするかもしれませんが、Kerasではコンパイル時に、
model.compile("adam", "kullback_leibler_divergence")
のように「categorical_crossentropy」を置き換えればいいだけなので、特に実装上難しくはありません。
直感的な理解としては、Crossentropyが「2つの確率の値を近づける」のに対して、KL-Divergenceは「2つの分布を近づける」ということなので、ラベルの値にノイズが入っている状態つまり、
$$ry_1+(1-r)y_2 $$
のような状態では、ノイズに引きづられるような値に近づけるよりも、線形補間された分布に対して最適化するほうがより良いであろうということだと思います(ここは論文に書いてあったことではないので、違っていたらすみません)。
3. ベータ分布ではなく、一様分布を使う
Mixupはベータ分布でしたが、BC-Learningは一様分布を使います。ただし、一様分布はベータ分布$Be(a,b)$で$a=b=1$という特殊な場合なので、「BC-LearningはMixupの特殊な場合」ということもできます。
https://keisan.casio.jp/exec/system/1161228837
4. 音声に対してはもう少し複雑な補間をする
画像に対してはMixupと同じ線形補間でしたが、音声に対してはもうちょっと複雑な補間を提唱しています。具体的には、
\frac{px_1+(1-p)x_2}{\sqrt{(p^2+(1-p)^2)}} \\
where\quad p=\frac{1}{1+10^{\frac{G_1-G_2}{20}}\cdot\frac{1-r}{r}}
とします。なぜなら、音のエネルギーは振幅の2乗に比例するからだそうです。$r$は同じく$U(0,1)$の一様分布で、$G_1, G_2$は2つの音声のデシベル[dB]を表します。ラベルのonehotベクトルは画像のときと同じく線形補間で良いと思います。
今回は音声での補間はやらずに、ただ単に画像の問題として効果を確かめます。
BCーLearningのジェネレーター
Mixupのようにバッチを取って、インデックスをシャッフルしたバッチと合成するでもいいと思いますが、今回は「異なるクラス」を混ぜるという点に着目してそこの保証をするようにしました。ジェネレーターの部分は以下のようになります。
def bclearning_generator(X, y, batch_size, sample_steps):
assert batch_size >= sample_steps
assert batch_size % sample_steps == 0
X_cache, y_cache = [], []
labels = np.sum(np.arange(y.shape[1]).reshape(1,-1) * y, axis=-1)
while True:
indices = np.random.permutation(X.shape[0])
for i in range(X.shape[0]//sample_steps):
current_indices = indices[i*sample_steps:(i+1)*sample_steps]
current_images = X[current_indices]
current_labels = labels[current_indices]
current_onehots = y[current_indices]
for j in range(batch_size//sample_steps):
for k in range(sample_steps):
diff_indices = np.where(current_labels != current_labels[k])[0]
mix_ind = np.random.choice(diff_indices)
rnd = np.random.rand()
if rnd < 0.5: rnd = 1.0 - rnd # 主画像を偏らさないために必要
mix_img = rnd * current_images[k] + (1.0-rnd) * current_images[mix_ind]
mix_onehot = rnd * current_onehots[k] + (1.0-rnd) * current_onehots[mix_ind]
X_cache.append(mix_img)
y_cache.append(mix_onehot)
X_batch = np.asarray(X_cache, dtype=np.float32) / 255.0
y_batch = np.asarray(y_cache, dtype=np.float32)
X_cache, y_cache = [], []
yield X_batch, y_batch
ここではstep_sizeとbatch_sizeという2つのパラメーターをつけました。batch_sizeは文字通りニューラルネットワークに渡すミニバッチサイズで、step_sizeは1回のバッチごとに使う起点となる画像です。例えば、batch_sizeが1024で、step_sizeが128なら、128枚の画像を起点として、起点とは異なる8枚の画像をノイズとして付加するというものです。
試しにこれでプロットすると次のようになります。BC-Learningあり版

注意してみないとわかりづらいですが、ガラスの映り込みみたいな他の画像がかすんで入っているのがわかるでしょうか?ちなみにBC-Learningの乱数を1で固定するとBC-Learningなしと同じになって、

2つを比較して見ればもう分かりやすいですね。BC-Learningありのほうが明らかにくすんでいます。人間的にはくすんでいるようにしか見えないが、実は2つの画像が混ざっているサンプルを作って訓練に使うことで、汎化性能が向上するという理屈です。
実験
論文で行われていた実験
論文では「11Layer-Network」という11層のCNNを使って検証していました。
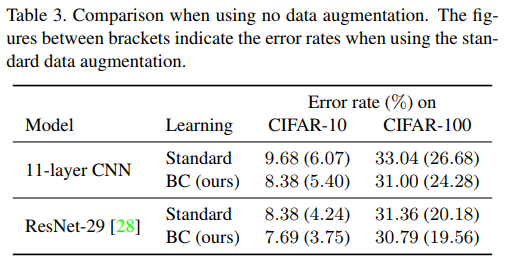
()内はHorizontal flip+上下左右4ピクセルのシフトを追加するという「Standard Data Augmentation」を入れた場合です。()の左側はStandard Data Augmentationを入れないケースです。つまり、BC-Learning以外のData Augmentationを入れないと、11-LayerのCNNでエラー率は**8.38%**ということになります。
11Layer-Networkの構成です。
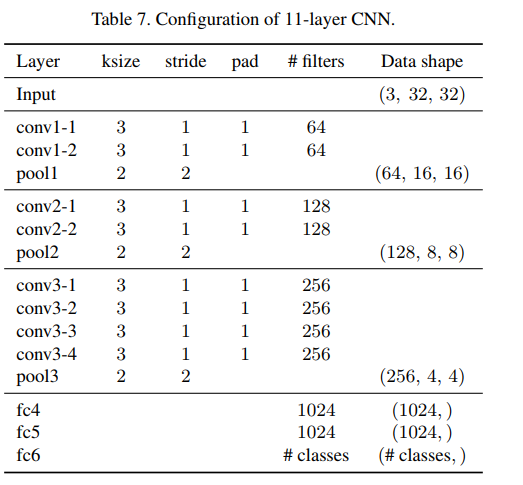
自分がよく作っている10層のCNNとかなり似た構成で、64チャンネルから256チャンネルにチャンネルは倍に、解像度は半分になっていくVGGライクの構造です。全結合化はFlattenを使っています。PoolingはMaxPoolingを使用しています。また、1024のFCにはそれぞれ50%のドロップアウトが入っています。
他にも以下のような条件が追加されています。
- 250エポック訓練。開始時の学習率は0.1、オプティマイザーはNesterovのモメンタム。
- 100エポック、150エポック、200エポックで学習率を1/10にする
- バッチサイズは128
- 5e-4のWeight Decayを追加
- 訓練はGPUで、Chainerを使用
再現する実験
はじめは論文で使われていた11Layer-Networkで再現しようとしたら、ChainerとTensorFlowで学習率のスケールが違うようで、うまく学習率の減衰が機能しませんでした。また、TPUで訓練しようとして、バッチサイズを1024と大きめにしたらValidation精度が0.9手前からほとんど上がらなくなってしまいました。ただしバッチサイズを論文通りに128にしたらTPUのKerasでも同じくらいの精度は再現できました。
以下のモデルで行いました。データはCIFAR-10を使います。
from tensorflow.keras import layers
from tensorflow.keras.models import Model
def conv_bn_relu(input, ch):
x = layers.Conv2D(ch, 3, padding="same")(input)
x = layers.BatchNormalization()(x)
return layers.Activation("relu")(x)
def create_network():
input = layers.Input((32,32,3))
x = input
for i in range(3):
x = conv_bn_relu(x, 64)
x = layers.AveragePooling2D(2)(x)
for i in range(3):
x = conv_bn_relu(x, 128)
x = layers.AveragePooling2D(2)(x)
for i in range(3):
x = conv_bn_relu(x, 256)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(10, activation="softmax")(x)
return Model(input, x)
ほとんど同じようなモデルですが、1024のFCは多分いらないと思うので切ってしまいました。また、オリジナルと以下のような違いがあります。
- 250エポック訓練させるのは同じ。オプティマイザーはAdamを使い、初期学習率は1e-3(デフォルト)
- 学習率の調整はいい感じにできなかったので、ずっと初期学習率のまま訓練させた。挙動を見ているとShake-ShakeみたいなCosine Decayもいいかもしれない。
- バッチサイズは128。最初はステップサイズも128。(これは後々変更)
- Weight Decayも追加しない
- BC-Learning以外のData Augmentationは段階に応じて適用
- 訓練はTPUで、Tensorflow/Kerasを使用
11LayersでStandard DataAugmentationなしで8.38%なので、精度91%超えを目指します。
結果
サマリー
| case | BC-Learning | Batch size | Step size | LR-Decay | Standard DA | Test acc |
|---|---|---|---|---|---|---|
| 0 | No | 128 | - | No | No | 0.8935 |
| 1 | Yes | 128 | 128 | No | No | 0.9118 |
| 2 | Yes | 1024 | 128 | No | No | 0.9074 |
| 3 | Yes | 1024 | 1024 | No | No | 0.8985 |
| 4 | Yes | 128 | 128 | Yes | No | 0.9173 |
| 5 | Yes | 128 | 128 | Yes | Yes | 0.9459 |
基本的にはバッチサイズが1024では論文並の精度は再現できませんでした。Batch sizeを1024にして、step sizeを128にするとある程度はよくなりますが、128-128の組み合わせを凌駕することはできませんでした。逆に言えば、論文通りにバッチサイズを128にするとその通りの精度が再現できます。
ケース1:BC-Learningだけ
1のケースのエラー率推移をプロットします。
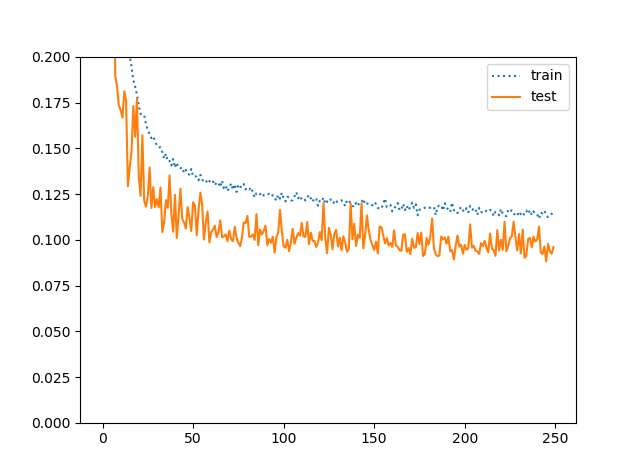
テスト精度のほうが高いという現象が起こります。これはRICAPでもありましたし、一様分布のように強めの正則化だからだと思います。
ケース4:BC-Learning+学習率減衰
ケース1を見ると100epochあたりから学習率を落とせそうな気がしますよね。そこで、100、150、200で学習率を1/5にしてみます(ケース4)。
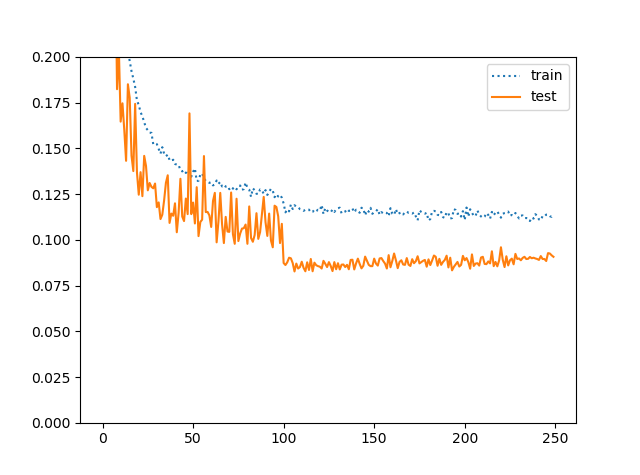
精度は**91.18%→91.73%**に向上して、ちょっとよくなりました。エラー率換算すると8.27%なので、論文よりも小さなネットワークで論文を超える精度は出せたということになります。
ケース3:BC-LearningのBatchSize=1024(失敗例)
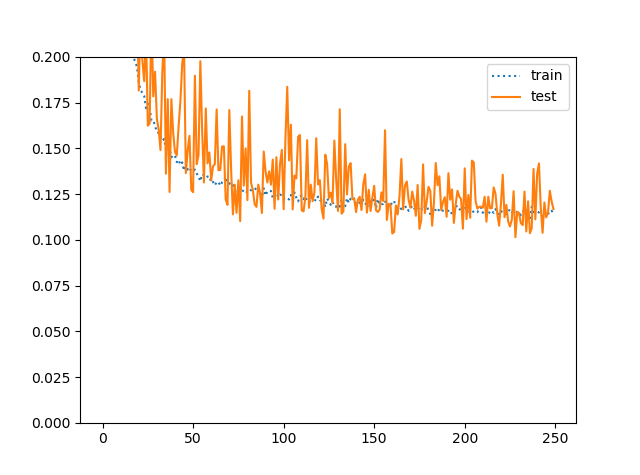
これはバッチサイズを大きくして失敗した例です。正則化効果が弱くなっている?
ケース5:BC-Learning+学習率減衰+Standard Augmentation
ケース4でここまでうまくいくと、Standard Augmentationを追加するとどれぐらい精度が伸びるのか気になりますよね。ちなみに論文では11Layer-CNNでエラー率5.4%だったので、精度は95%に迫ることができるということになります。本当にそんな値出せるのでしょうか?
Standard Augmentationをかませるにはちょっとジェネレーターを改良します。具体的には、BC-LearningのジェネレーターのベースをImageDataGeneratorにします。例えば「base_gen」というImageDataGeneratorがあったとして、
base_gen = ImageDataGenerator(horizontal_flip=True, width_shift_range=4.0/32.0,
height_shift_range=4.0/32.0).flow(X_train, y_train, step_size)
これをBC-Learningのジェネレーターに渡します(継承するとかでもOKです)。
def bclearning_generator(base_generator, batch_size, sample_steps, n_steps):
assert batch_size >= sample_steps
assert batch_size % sample_steps == 0
X_cache, y_cache = [], []
while True:
for i in range(n_steps):
while True:
current_images, current_onehots = next(base_generator)
if current_images.shape[0] == sample_steps and current_onehots.shape[0] == sample_steps:
break
current_labels = np.sum(np.arange(current_onehots.shape[1]) * current_onehots, axis=-1)
for j in range(batch_size//sample_steps):
for k in range(sample_steps):
diff_indices = np.where(current_labels != current_labels[k])[0]
mix_ind = np.random.choice(diff_indices)
rnd = np.random.rand()
if rnd < 0.5: rnd = 1.0 - rnd # 主画像を偏らさないために必要
mix_img = rnd * current_images[k] + (1.0-rnd) * current_images[mix_ind]
mix_onehot = rnd * current_onehots[k] + (1.0-rnd) * current_onehots[mix_ind]
X_cache.append(mix_img)
y_cache.append(mix_onehot)
X_batch = np.asarray(X_cache, dtype=np.float32) / 255.0
y_batch = np.asarray(y_cache, dtype=np.float32)
X_cache, y_cache = [], []
yield X_batch, y_batch
これでStandard AugmentationとBC-Learningを共存させることができました。ImageDataGeneratorはサンプルの端数分(例えば5万個のデータなら、128のミニバッチ数で切り出すと、80=50000 mod 128なので80個)返してくることがあります。このような端数分のバッチはエラーになるので捨ててしまいます。
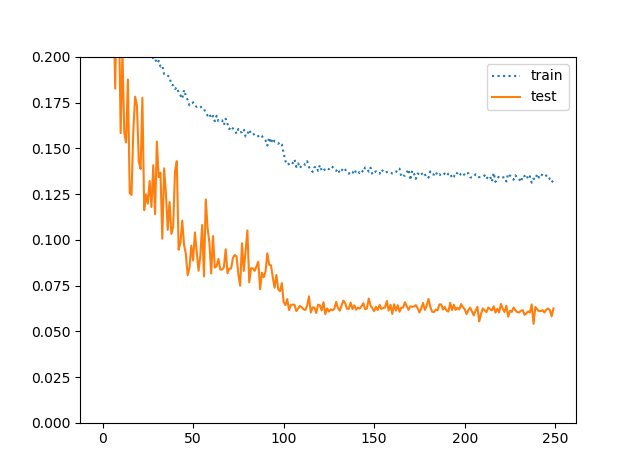
結果は10層CNNであるにもかかわらず、94.59%という驚異的な性能を出しました。エラー率では5.41%なので、ほぼ論文と同じ値ということになります。自分は10層CNNでここまでの値を出したことは見たことありませんし、Mobile-Netの転移学習並の性能は出ていると言えるでしょう。
正則化を強くするほど、Train-Testの逆乖離が拡大しているのが面白いですね。
議論
BC-Learningが思ったより強かったということですが、似たようなData AugmentationであるMixupが画像分類においてどの程度の精度を出しているかということを考えます。
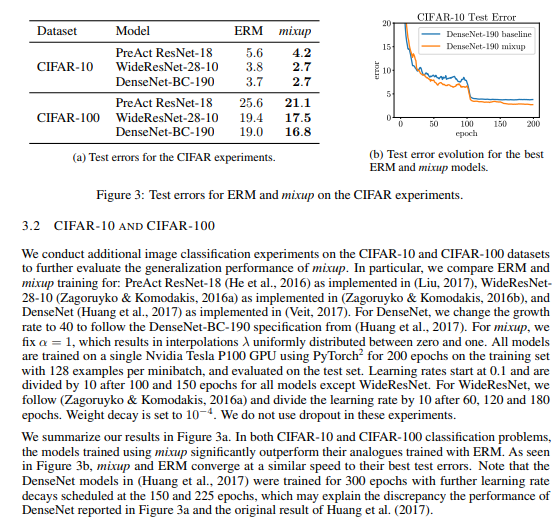
これはMixupの論文からです。MixupのCIFAR-10はだいたい訓練方法がBC-Learningと同じですね。ただMixupのほうはWideResNet28やDenseNet190というかなり高価なCNNを使っているので、一概には比較できないかなと思います。ただ結果はMixupもかなりすごいです。
個人的に気になったのは1024というような「大きなバッチ」に対してMixupまたはBC-Learningが使えるかということだったのですが、残念ながらMixupの論文でも大きなバッチに対してCIFAR-10の検証は行われていませんでした。しかし、MixupのImageNetの検証を見るとバッチサイズを1024にしているため、Mixup/BC-Learningが大きなバッチに対して使えないというわけではないと思います。あくまでチューニングの必要があるだけで。
先程も述べたように、一様分布はベータ分布の特別な場合なので、基本的にはBC-Learningのスタイルで訓練して、分布だけベータ分布にしてパラメーターを変更するというのが大きなバッチに対する可能性がある方法ではないかと思います。もしかすると、学習率の調整だけで通用できるかもしれません。それは調べがいがあることではないかと思います。
追記:大きなバッチに対してもできました→https://qiita.com/koshian2/items/06fb7e53d368bb2dd892
今回使用したケース4、ケース5のコードは以下の通りです。
ケース4:https://gist.github.com/koshian2/dce95978bd2cb6effaea788de9bc6515
ケース5:https://gist.github.com/koshian2/c8fac3fdd6e0200749b51680b01c6e44
(追記)どこでMixするかという話
これはあくまで論文の受け売りなのですが、論文ではネットワークの中でBC-Learningのような線形補間をするかというのを考えていました。まさにShake-Shakeの発想ですね。それによると、
- 入力層に近いような低レベルのレイヤーでのMixはData Augmentation同様に効く
- 出力層に近いような高レベルのレイヤーでのMixは少しだけ効果がある
- 中間層のレイヤーでのMixはパフォーマンスを劣化させる
つまり、低レベルのレイヤーでの活性化関数は音のような「波形データ」として機能しているのではないかと仮定できる。低レベルの層での出力は空間情報がある程度保持されておりBC-Learningは機能するが、中間層では空間情報と意味的な情報が同時に混在しているため、中間層での線形補間は意味がないのではないか、と考えられる。
とのことでした。これはなかなか面白い話ですね。