TPUを使えばある程度のモデルは動いてしまうのですが、このVariational Auto Encoder(VAE)だけはうまく動かせなかったのです。VAEは数ヶ月前から何回かやって、数日かかってもエラー多発で挫折してしまい、正直沼でした。ただ、発想の転換をしたらTPUでもVAEを動かすことができました。その方法を解説します。
2つのモデルに分けるのがよくない
よくあるGPUのVAEでは、訓練用と推論用に2つのモデルを用意し、重み共有レイヤーを使って推論時にデコーダーの部分だけ取り出すようにします。訓練時にはEncoder+Decoder、推論時にはDecoderだけ取り出す。そしてDecoderは重み共有という具合です。
しかし、この重み共有レイヤーのある2つのモデルというのが、TPUが苦手で沼る(思ったとおりの挙動がされない)ことが多いです。「それなら訓練用も推論用も1つのモデルで定義して、ネットワークの配線構造で内部的にあたかも2つのモデルがあるように再現するというのがまだ手っ取り早いのでは」というアイディアを思いついたため、ブレイクスルーができました。
こんなモデル
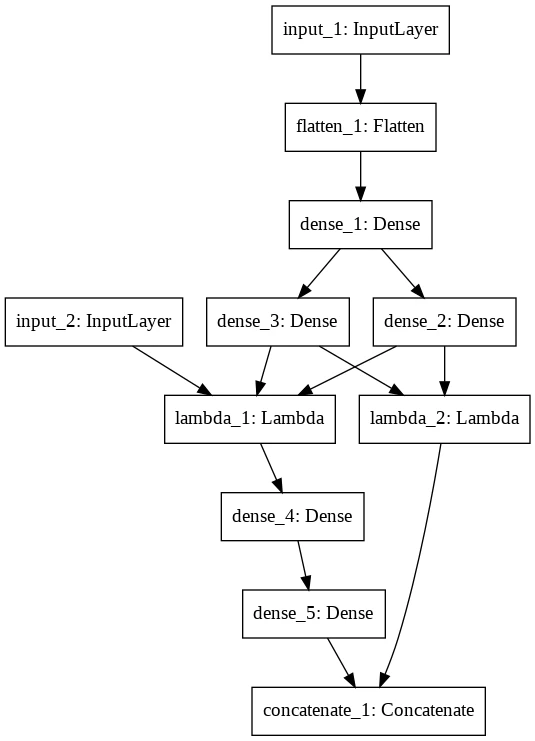
「input_1」は入力画像を入れるレイヤーです。「input_2」は推論用の乱数を入れるレイヤーです。VAEはその構造からEncoderの出力→Decoderの入力時に、「reparameterization trick」という変数変換をやっています。「dense_2」と「dense_3」がreparameterization trickで使われる、「mu」と「logvar」です。
ここからがポイントで、推論用の乱数であるinput_2と、reparameterization trickの部分をSkip-connectionで結び、乱数の入力は訓練時にはシャットアウトします。逆に推論時には、Encoder側のreparameterization trickの入力をシャットアウトし、乱数側の入力を採用します。つまり、乱数のSkip-connectionを加えるとともに、reparameterization trickの部分に訓練/テスト時のスイッチ構造を追加します。このようなスイッチ構造は、K.in_train_phase()という関数で再現できます。Dropoutのレイヤーがまさにこんなスイッチ構造ですよね。
さらに、損失関数の計算を簡単にするために、損失関数で使われるKL-ダイバージェンスをreparameterization trickの段階で計算して持っておくということをします。そして、出力層の後との間にKLダイバージェンスをSkip-Connectionでつなぎ、最後の列にConcatenateします。
つまり、最終的なモデルの出力は、MNISTなら0~783が画像で、784はKL-ダイバージェンスの値ということになります。推論時はフィルタリングで[:784]とかやれば画像の部分だけ取り出すことができます。これでVAEを1つのモデルとして定義することができました。
コード解説
もともとのVAEの実装はPyTorchのVAEの例を参考にしています。こちらのほうがわかりやすいので。
自分が書いたTPUでのVAEのコード全体こちらにあります。
Reparameterization trick
言葉で書くと難しいですがコードにするとそこまで難しくありません。通常のreparameterization trickでは、muとlogvarだけを入力として入れますが、今回は1つのモデルにするために推論用の乱数の入力を3番目の入力としています。これがSkip-Connection用です。
そして、学習フェーズに合わせて、訓練時にはoutput, 推論(テスト)時にはskip-connectionを返すようにします。
def reparameterize(inputs):
# Connect a random number entered from input with skip-connection and adopt it at the time of test
mu, logvar, skip = inputs[0], inputs[1], inputs[2]
std = K.exp(0.5*logvar)
eps = tf.random_normal(tf.shape(std))
output = eps * std + mu
return K.in_train_phase(output, skip)
ちなみに、「推論時にもReconstructionとSamplingの両方を見たいんじゃ~」という欲張りな方は、K.set_learning_phase()で学習フェーズを設定するといいでしょう。
KL-ダイバージェンス
VAEの損失関数には画素自体の損失の他に、KL-ダイバージェンスの項があります。これらはmuとlogvarだけで計算できてしまうので、事前に計算しておくと良いでしょう。事前計算することで、最後までmu, logvarを持っておく必要がなくなります。
def kld(inputs):
mu, logvar = inputs[0], inputs[1]
kld = -0.5 * K.sum(1 + logvar - mu **2 - K.exp(logvar), axis=-1, keepdims=True)
return kld
損失関数
KLダイバージェンスは中間層で計算済みなので、SkipConnectionからの入力をそのまま足せば良いだけです。
def loss_function(y_true, y_pred):
# 0-783 image, 784:kld
bce = K.sum(K.binary_crossentropy(y_true[:,:784], y_pred[:,:784]), axis=-1)
return bce + y_pred[:,784] # bce + kld
訓練の方法
訓練時には乱数の部分を全く使わないので、ダミーの値を入れておきます。np.zeros()とかでも入れておけばOKです。また、KLダイバージェンスの真の値も使わないので(sample_size, 1)のshapeでダミーの値を入れておきます。
dummy_rand = np.zeros((X_train.shape[0], 64))
y_train = np.concatenate((X_train.reshape(-1, 784), np.zeros((X_train.shape[0], 1))), axis=-1)
model.fit([X_train, dummy_rand], y_train, batch_size=1024, callbacks=[cb, hist], epochs=20)
推論の方法
次は推論(Sampling)の方法です。サンプリング時には、画像データ側を使わなくなるので、こちらをダミーにします。推論なのでyに相当する値は必要ありません。
dummy = np.zeros((64, 28, 28))
rand = np.random.randn(64, 64)
stacked_sampling = self.model.predict([dummy, rand])[:, :784].reshape(-1, 28, 28)
最後の1列はKLダイバージェンスの値で必要ないです。捨ててしまいましょう。
結果
100エポック動かした結果がこちら。隠れ層が少なすぎるので画質はお察しです。綺麗にしたかったらもっと隠れ層を増やしましょう(TPUが悪いというわけではありません)。

訂正:アホやってmuとlogvarに活性化関数入れてたせいで本来の画質が出ませんでした。
この方法のデメリットは、推論時にEncoderにおいて意味のない計算をしているために若干無駄があることです。しかし、TPUの計算は十分速く、データのロード側が問題になることが多いので、よほど深いモデルでもない限り大きな差にはならないのかなと思われます。