Perfumeが紅白歌合戦でディープラーニングについて言及して話題になりましたが、それに関連する技術がGoogleのブログで公開されていたので再現してみました1。本来はColud Vision APIを使ったとのことですが、精度や速度を犠牲にすれば、普通のPCかつ1人でも実装できてしまいます。その方法を書いていきます。
訂正:Googleが使ったではなく、正しくはライゾマティクスに使っていただいただとのことです。失礼いたしました2。タイトルも訂正いたしました。
元ネタ
こちらのブログに詳しく書かれています。
Perfume とライゾマティクスの新たな試みを支える Google の機械学習
https://cloudplatform-jp.googleblog.com/2018/06/NHK-Perfume-TECHNOLOGY-Reframe-Your-Photo-Google-TensorFlow.html
Reframe Visualizationとはこのようにミュージックビデオをキャプチャした画像を似ている同士でタイルするものです。

(Google Cloud Platform Japan Blogより)
問題は画像の”似ている”をどう判定するかです。ここにディープラーニングが使われています。記事によると「Reframe Visualization」の概略は、
「Perfume のすべてのミュージックビデオをフレーム画像として用意し、TensorFlow でディープラーニングによる画像認識を適用しました。その時に認識結果として得られる 2048 次元の特徴ベクトルを抽出し、t-SNE により 2 次元空間に次元削減しています。この手法により、画像に含まれる色や形、パターン等の『画像の特徴の近さ』が、2 次元空間上の距離の近さにマッピングされ、コラージュが生成されます」(浅井氏)
とのことです。一般人はチンプンカンプンかもしれませんが、実はそこまで難しいことはやっていなくて、ディープラーニングちょっとわかる方は「えっそれだけでいいの?」って思うかもしれません。
実はこれは「転移学習」の一種です。Cloud Visionもそうでしょうが、何らかの一般的な画像のデータ(例えばImageNet)で訓練されたニューラルネットワークのモデルを用意します。このネットワークを特徴量抽出機として使い、画像のピクセル値という低レベルのデータを、「どういったモノが映っているか」という高レベルのデータ(特徴量)にマッピングします。
例えば、画像はRGBというピクセルの数値を記録していますが、人間の目では画像になにが映っているか(例えば猫が映っているか、人が映っているか)を分類することができます。これを巨大なニューラルネットワークを使い、高い精度でコンピューターにやらせるのが、まさにディープラーニングがやっていることです。
転移学習とは、一般的な画像データで訓練させたモデルを使い、ある特定の(今回の場合はPerfumeの)画像の特徴量を抽出するということが相当します3。ちなみに後者については、Perfumeの画像を使い再訓練させても構わなく、むしろそのほうがよりキレイなタイル画像(特徴量抽出)ができるかと思います。ただ、再訓練させなくてもできることはできるので、この記事では再訓練させません。
再現手順
Googleが出した記事から、「Reframe Visualization」が多分こんな手順ではないかというのを推測し再現してみました。不適切画像の除外とか一切考えてないので若干漏れがあるかもしれませんがご了承ください。
- YouTubeから動画をダウンロードし、一定間隔(1秒など)でフレーム単位で静止画を切り出す
- ImageNetで訓練済みの畳み込みニューラルネットワーク(CNN)を用意する(潜在特徴量が2048次元なので、多分InceptionV3あたりでは?)
- このCNNに対して、静止画を入力として与え、2048次元の潜在特徴量を得る
- 2048次元の潜在特徴量を、Scikit-learnのt-SNEを使い、2次元に投射する
- t-SNEで投射した2次元の座標を出力の座標と対応させ、最も近いプロットをk-Nearest Neighbor(k=1)の要領で選ぶ
- 最近傍の画像をタイルして完成
大人の事情
実は大人の事情がありまして、これを再現する際に自分はPerfumeに一切許可を得ていません。機械学習では著作権法47条の7という例外はありますが、解析は良くても、動画のキャプチャを勝手にコラージュして公開するとなると問題が出てくる可能性があります。なので、今回はPerfumeの動画で再現しません。
代わりに使うのはこちら。北朝鮮のPerfume(?)こと「牡丹峰楽団」の動画を使います。
Moranbong Band & State Merited Chorus - Fly high our Party flag (높이 날려라 우리의 당기)

Moranbong Band - Let’s go to Mount Pektu (가리라 백두산으로)

北朝鮮の著作物は最高裁の判例により、日本では保護義務がない、つまりパブリックドメインとして使うことができます4。これで大人の事情による面倒事を回避できます。

牡丹峰楽団といえばNK-POPの代表格ですが、非常にレベルの高い演奏なのでぜひ聞いてみてください。チャンネルはこちら。
実装
リポジトリはこちらにあります:
https://github.com/koshian2/Reframe-Visualization
1.YouTubeからダウンロードして、画像を取得
PyTubeとffmpegを使います。ffmpegは別途バイナリのインストールが必要になります。
from nkpop import nkpop_list
from pytube import YouTube
import ffmpeg
import os, glob, tarfile
from tqdm import tqdm
def download_all():
if not os.path.exists("videos"):
os.mkdir("videos")
for path in tqdm(nkpop_list):
try:
yt = YouTube(path)
yt.streams.filter(fps=30, res="1080p", subtype="mp4").first().download("videos")
except:
continue
def convert_to_image():
cnt = 0
for path in tqdm(sorted(glob.glob("videos/*"))):
if not os.path.exists("images"):
os.mkdir("images")
stream = ffmpeg.input(path)
stream = ffmpeg.output(stream, f"images/{cnt:02d}_%05d.jpg",r=1 ,f="image2", q=4)
ffmpeg.run(stream)
cnt += 1
YouTubeには複数の画質、音声の含む含まない、FPS設定があるので、「1080p、30fps、動画のみ」で抽出しました。画質条件が一致しない場合はダウンロードをやめました。
PyTubeで動画をダウンロードしたあとは、ffmepgでフレーム単位で切り出します。ダウンロードした動画が結構多かったので、画像は1秒単位で切り出しました。これで23135枚の画像ができます。
切り出した画像に対してmetadata.pyでメタデータを作ります。
2.潜在特徴量の抽出
InceptionV3を使って画像の特徴量を得ます。
from keras.applications import InceptionV3
from keras.layers import GlobalAveragePooling2D
from keras.models import Model
from PIL import Image, ImageDraw
from sklearn.manifold import TSNE
import joblib
import numpy as np
from tqdm import tqdm
import cv2
def create_net():
inception = InceptionV3(include_top=False, weights="imagenet", input_shape=(299,299,3))
x = GlobalAveragePooling2D()(inception.output)
return Model(inception.inputs, x)
def generator(batch_size):
metadata = joblib.load("metadata.job.xz")
X_cache = []
while True:
for i, path in metadata.items():
with Image.open(path) as img:
width, height = img.size
img = img.convert("RGB")
left = (width - height) // 2
right = left + height
img = img.crop((left, 0, right, height)).resize((299,299), Image.BILINEAR)
img_array = np.asarray(img, dtype=np.uint8)
X_cache.append(img_array)
if len(X_cache) == batch_size:
X_batch = (np.asarray(X_cache) / 255.0).astype(np.float32)
X_cache = []
yield X_batch
def latent_values():
model = create_net()
# 23135 = 35 * 661
latent = model.predict_generator(generator(35), steps=661, max_queue_size=1, verbose=1)
joblib.dump(latent, "latent.job.xz", compress=3)
ここが一番のボトルネックです。23135枚の画像の特徴量を取るのにCPUだと5~7時間かかります。GPU使えばそこまで長くありませんが、ニューラルネットワークの推論自体が重いので、リアルタイムにやりたかったらCloud Visionなどもっと計算リソースが必要になります。
3. t-SNEで埋め込み
Sklearnのt-SNEは使うだけならそこまで難しくないのでこれでOKです。t-SNEの理論はこちらで書いたので必要な方はどうぞ。
def embedding():
data = joblib.load("latent.job.xz")
tsne = TSNE(n_components=2, perplexity=10.0)
embedded = tsne.fit_transform(data)
print(embedded.shape)
joblib.dump(embedded, "tsne.job.xz", compress=3)
perplexityは投射した点の集まり方の密さを表すものです。この値は5~50が理論値で、低いほうが点が密になりやすく、高いとゆるいプロットになります。今回は低めでチューニングしたほうがうまく行きやすかったです。
2次元への埋め込みをプロットすると次のようになります。
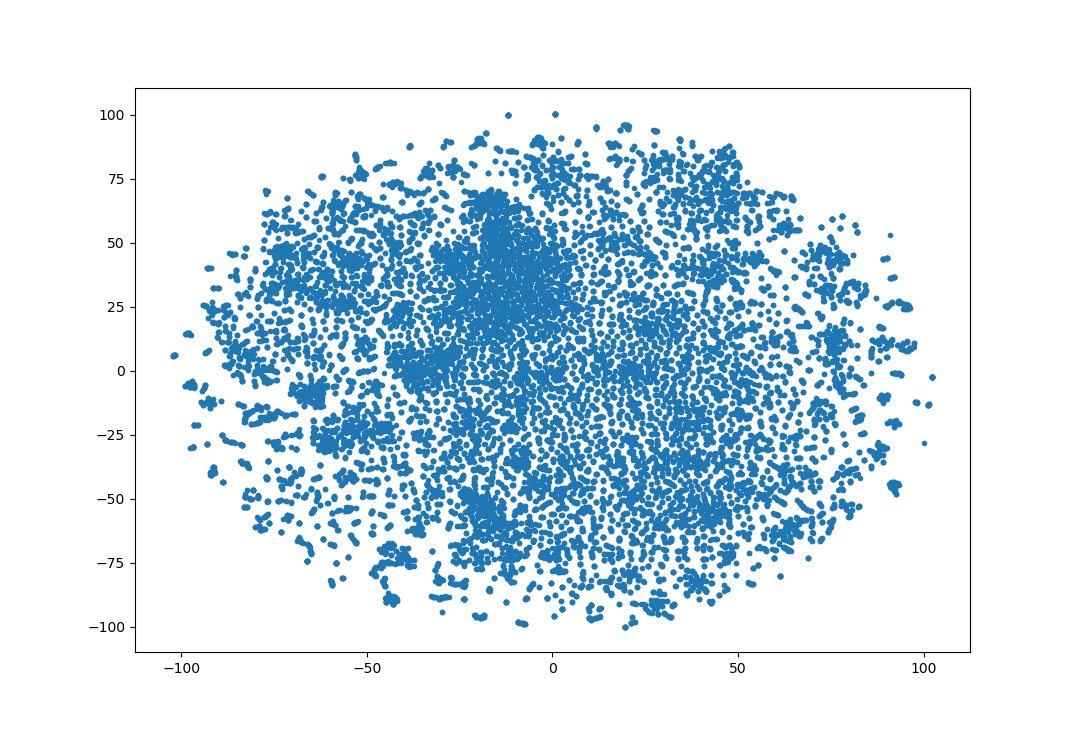
若干ぼやけていますが、似たような点に集中しているのがわかります。似たような点に集まっているのが似た画像というわけです。
t-SNEの計算は若干時間がかかり、CPUで30分ぐらい必要です。ただ、一回座標変換の計算をしてしまえば次回以降は高速化できるので、そこまで問題にはならないかと思います。
4. Nearest Neighbor
まず画像タイルの座標系を考えていきたいと思います。
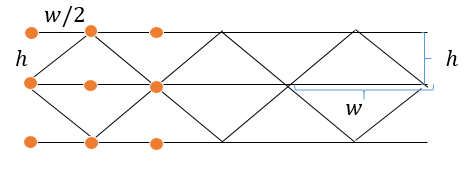
幅$w$, 高さ$h$の三角形があったときに上下互い違いにしてタイルすると、三角形の左上の座標は幅$w/2$、高さ$h$間隔で敷き詰められていきます。この左上の点から最も近い画像を選べばOK(三角形の中点で考えてもOK)です。やっていることはk=1のk-Nearest Neighbor法にほかなりません。
今回は横に60枚、縦に30枚画像を敷き詰めるものとします。
def find_nearest_neighbor():
# 60x30でプロット
data = joblib.load("tsne.job.xz")
min_x = min(data[:, 0])
max_x = max(data[:, 0])
min_y = min(data[:, 1])
max_y = max(data[:, 1])
pitch_x = (max_x - min_x) / 60.0
pitch_y = (max_y - min_y) / 30.0
index_mat = np.zeros((60, 30), dtype=np.int32)
for i in tqdm(range(60)):
for j in tqdm(range(30)):
pos_x = min_x + pitch_x * i
pos_y = min_y + pitch_y * j
positions = np.array([pos_x, pos_y]).reshape(1, -1)
dist = np.sum((data - positions) ** 2, axis=-1)
index = np.argmin(dist)
index_mat[i, j] = index
joblib.dump(index_mat, "indices.job.xz", compress=3)
5.画像タイル
個人的には一番ここが面倒でした。上下の三角形のマスク画像を作って、透過処理し、それらをペーストさせます。
def paste_images(file_path, is_upper_triangle, target_image, position):
with Image.new("L", (128, 128)) as mask:
draw = ImageDraw.Draw(mask)
if is_upper_triangle:
draw.polygon([(64, 0), (0, 128), (128, 128)], fill=255)
else:
draw.polygon([(0, 0), (128, 0), (64, 128)], fill=255)
with Image.open(file_path) as original:
width, height = original.size
left = (width - height) // 2
right = left + height
resized = original.crop((left, 0, right, height)).resize((128,128), Image.BILINEAR).convert("RGBA")
resized.putalpha(mask)
target_image.paste(resized, position, resized)
def merge_images():
metadata = joblib.load("metadata.job.xz")
neighbors = joblib.load("indices.job.xz")
with Image.new("RGBA", (64*60, 128*30)) as canvas:
for i in tqdm(range(neighbors.shape[0])):
for j in tqdm(range(neighbors.shape[1])):
paste_images(metadata[neighbors[i, j]], (i+j)%2==0, canvas, (-64+64*i, 128*j))
canvas.save("merged.png")
# 1分半ぐらいかかる
自分のPCでやったら、だいたい1分半ぐらいかかりました。ここもボトルネックなるかもしれません。高速にやりたいのなら性能の良いクラウド環境が必要だと思います。
完成
できたものはこちら

Googleが作ったものに比べるとかなりノイズが多いですが、それっぽくできているのがわかります。似た画像同士が近くに寄るようにプロットされています。中央のあたりがごちゃごちゃしているので、前処理で関係なさそうな画像を省いたり、ニューラルネットワークを再訓練(fine-tuning)させたりするともっと綺麗に出ると思います。
まとめ
ミュージックビデオだけではなく、一般的な画像や動画でもできる可視化手法なので応用性は高いと思います。発想としてはとてもわかりやすいです。
YouTubeとKerasとScikit-learnがあれば、Googleの手法も1台のPCで再現できてしまいます。まさに「突破せよ、最先端を」というわけですね。
Cutting Edge Breakthroughs(돌파하라 죄점던을) (CNC song)

コメント、ツッコミ等お待ちしております。
お詫び
コメントに一部不適切と思われる内容がありますが、以下のような経緯のやりとりがあったためです。読者の皆様に不快な思いをさせてしまったことをお詫びいたします。
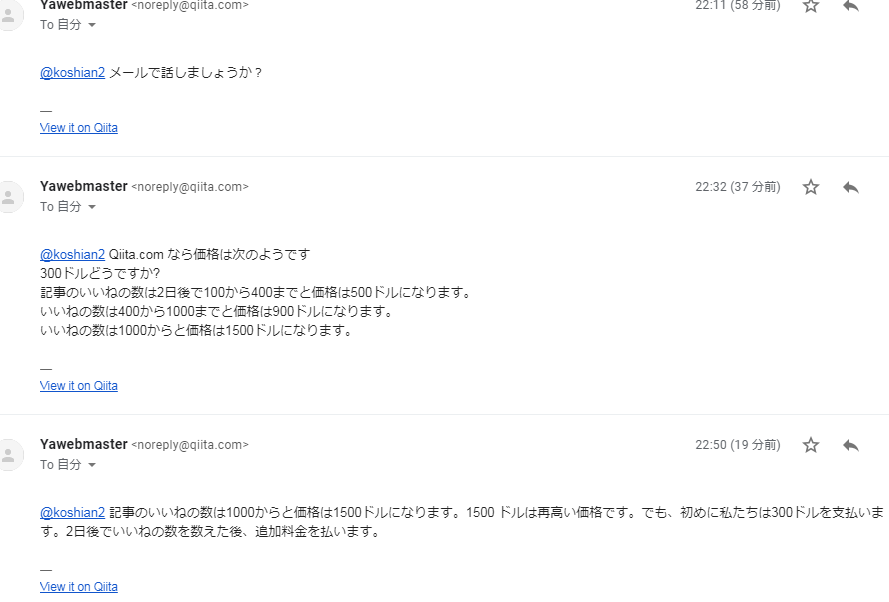
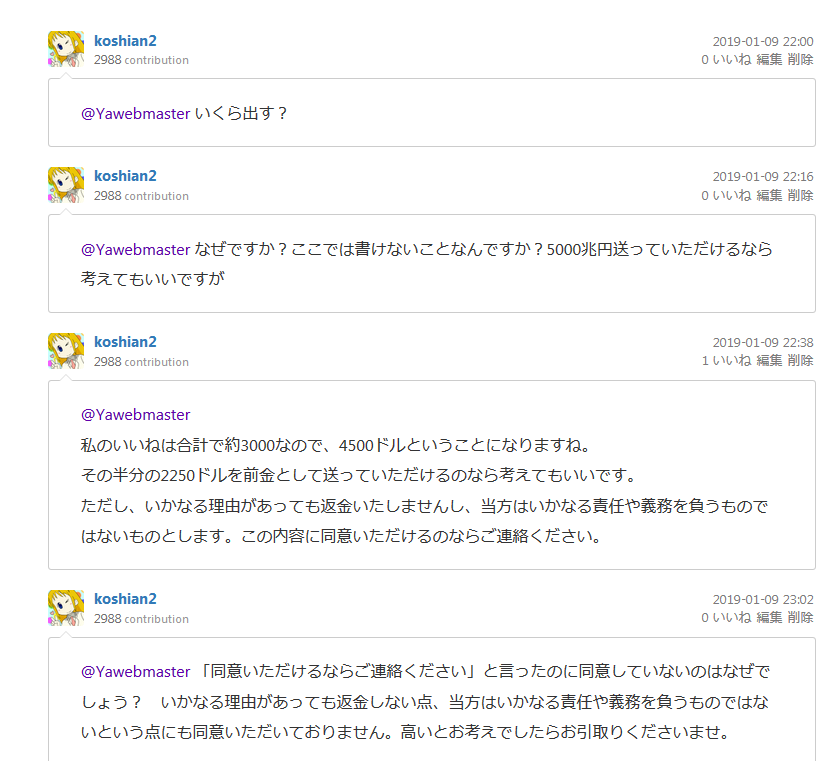
当該コメント(通知メールより転載)は自主的に削除したようです。なぜ削除したんでしょうね?ちなみにQiitaの記事を使った、広告・勧誘行為はQiitaの利用規約第8条3.(1)
(1)宣伝や商用を目的とした広告・勧誘その他の行為。ただし、当社が本サービス上で別途定める場合はその限りではありません。
に違反する行為です。当該ユーザーはCAPTCHAの突破業者の宣伝のようです。
-
2018年の紅白歌合戦で使われた技術とは別のものだそうです。https://twitter.com/daitomanabe/status/1080084411188621318 ↩
-
https://twitter.com/kazunori_279/status/1082752484400017408 ↩
-
分類と特徴量抽出の関係は、ニューラルネットワークが抽出と同時に、その特徴量を使って分類計算をしているのでほぼ同義と考えてOKです。 ↩
-
北朝鮮映画の著作権、日本では「保護義務なし」 最高裁 http://www.asahi.com/special/08001/TKY201112080593.html ↩