AnimeFace Character Datasetなる面白いものを見つけたので、これをKerasやGoogle Colabで使うことを目指します。今回はデータの整形が中心です。実践的なデータ分析の参考になれば幸いです。Colabに取り込んだ後、MixUpでData AugmentationしDenseNetで転移学習します。
ダウンロード
AnimeFace Character Datasetはこちらからダウンロードできます。AnimeFaceを使ってキャラクターの画像を輪郭抽出したもの、だそうです。
http://www.nurs.or.jp/~nagadomi/animeface-character-dataset/
564MBのzipファイルですが、以下のようなフォルダ構成になっています。
+ animeface-character-dataset
+ thumb
+ 000_hatsune_miku
- face_27_136_113.png
- face_93_104_36.png
- : :
+ 001_kinomoto_sakura
- face_98_196_139.png
- face_156_313_74.png
- : :
キャラクターごとに160x160のpng画像で、顔画像のみ切り取られています。かなり整形されたデータセットなのですが、一部余計なファイルが入っており、またtrainとtestが分割されていないので、Kerasで使うには若干不十分なのです。これを整形してColabで使えるようにLinuxフレンドリーなtarアーカイブで固めます。
Kerasで使うには、次のようなディレクトリ構造を目指します。
+ animeface-character-dataset
+ train
+ 000_hatsune_miku
+ 001_kinomoto_sakura
+ : :
+ test
+ 000_hatsune_miku
+ 001_kinomoto_sakura
+ : :
なかなか泥臭い作業ですが、これを書いていきましょう。
ファイルの展開
Zipアーカイブから必要なファイルのみ展開します。この処理はローカルで行います。
from zipfile import ZipFile
import os
from sklearn.model_selection import train_test_split
zipfile = "animeface-character-dataset.zip"
with ZipFile(zipfile) as zip:
ziplist = zip.infolist()
# 集計
def categorize(file_path):
paths = file_path.split('/')
if len(paths) != 4: return None
if paths[1] != "thumb": return None
if not paths[3].endswith(".png"): return None
return paths[2]
files = {}
for f in ziplist:
character = categorize(f.filename)
if character is None: continue
if not character in files: files[character] = []
files[character].append(f.filename)
n_pic = 0
for key, value in files.items():
print(key, len(value))
n_pic += len(value)
print("画像数合計:", n_pic)
# コピー
dir_name = "animeface-character-dataset"
if not os.path.exists(dir_name):
os.mkdir(dir_name)
def rename_copy(zip_obj, file, target_dir):
filepath = os.path.basename(file)
with open(os.path.join(target_dir, filepath), "wb") as fp:
fp.write(zip_obj.read(file))
with ZipFile(zipfile) as zip:
for key, value in files.items():
# train-test-split
train, test = train_test_split(value, test_size=0.3, random_state=4)
# Copy
train_dir = os.path.join(dir_name, "train", key)
test_dir = os.path.join(dir_name, "test", key)
if not os.path.exists(train_dir): os.makedirs(train_dir)
if not os.path.exists(test_dir): os.makedirs(test_dir)
for f in train:
rename_copy(zip, f, train_dir)
for f in test:
rename_copy(zip, f, test_dir)
合計176人のキャラクターの画像が14490枚集まっています。キャラごとの集計結果はこちらに上げました。
https://gist.github.com/koshian2/47b5b2bb18f2c20e84a82ca31dbbd5dc
これをキャラごとに7:3の訓練:テスト分割を行います。パスの配列をSklearnのtrain_test_splitで分割させると楽です(こういう使い方もできます)。
可視化してみよう
さてどのようなデータが入ってるか列挙してみましょう。どうせKerasを使うので、ImageDataGeneratorで列挙させてみます。
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
datagen = ImageDataGenerator(rescale=1/255.0)
X, y = datagen.flow_from_directory("animeface-character-dataset/train",
target_size=(160, 160), class_mode="categorical", batch_size=100).next()
plt.figure(figsize=(8, 8))
plt.subplots_adjust(left=0.05, right=0.95, top=0.95, bottom=0.05, hspace=0.05, wspace=0.05)
for i in range(100):
plt.subplot(10, 10, i+1, xticks=[], yticks=[])
plt.imshow(X[i])
plt.show()
データをランダムに100枚読み込むところがたった2~3行で書けてしまいました。最高ですね。

すげえ、誰が誰だかわからない
これの人間の誤差は何%ぐらいなのでしょうか?どのキャラが入っているかという事前知識があっても相当難しいと思います。
Tarファイルで固める
Google Colabで使いたいので、tarファイルで固めます。Zipでもいけると思いますが、圧縮率高そうなtar.xzでいきます。
import tarfile
with tarfile.open("animeface-character-dataset.tar.xz", "w:xz") as tar:
tar.add("animeface-character-dataset")
Google Driveにコピー→Google Colabで読み込ませる
ここがちょっと面倒です。Google Colabは12時間のインスタンス時間制限があるので、600MB近いファイルを毎回アップロードしているとそれだけで時間無駄にしてしまいます。Colabに直接アップロードしてもかなり時間かかるので、高速にデータを取り込むために少し工夫をしないといけません。
ただし、Google Driveはもともと大容量のファイルのUP/DOWNする前提で設計されているので、クライアント側のアップロード速度がボトルネックになるぐらいの速度でアップロードできます。自分の環境では600MBのファイルが10分ぐらいでアップロードできました。Google Driveだとファイルが永続化されますのでそのメリットもあります。
上記で作ったtar.xzファイルをGoogle Driveの適当なフォルダに上げておきます。リンク共有にする必要はありません。Driveへのアップロードはブラウザからできるので省略。
ColaboratoryからGoogle Driveのファイルを読み書きする
https://qiita.com/kakinaguru_zo/items/33dbe24276915124f545
この記事の「Colaboratoryへのファイルの取り込み」を参考にDrive→Colabへの転送を行います。この操作はインスタンスがリセットさせるたびに行う必要がありますが、Drive→Colab間はむちゃくちゃ転送速度速いので(600MBが数秒で落ちてくる)、一度Driveにあげちゃえば特に遅いところはないです。gitに上げるよりこっちのほうが速いと思います。Drive全体のマウントを紹介している記事もありますが、この記事のように必要なアーカイブのみダウンロードする方法でいいと思います。
Tarファイルを解凍
ここからはColab側での操作になります。
!tar -Jxvf animeface-character-dataset.tar.xz > /dev/null
解凍ログがうるさいので/dev/nullで捨てましょう。ちゃんと解凍できているか確認します。
!ls animeface-character-dataset/train
以下のように出力されればOKです。
000_hatsune_miku 090_minase_iori
001_kinomoto_sakura 091_komaki_manaka
002_suzumiya_haruhi 092_shindou_kei
003_fate_testarossa 093_yuuki_mikan
004_takamachi_nanoha 094_fuyou_kaede
: :
学習済みDenseNetからの転移学習
いざ、ディープラーニングで分類!といきたいところなのですが、この場合1クラスあたりに訓練画像が高々60~100枚なので1から訓練させるとものすごい時間がかかってうまく行きません1。そこで学習済みモデルから転移学習させます。訓練画像の内容は違えども結局は画像であることは変わりないので、輪郭抽出など前のレイヤーの特徴量抽出は共通なのです。そこを上手く活用したのが転移学習という画期的な方法です。
転移学習させるときは大抵VGG16/19を使うのですが、モデルが古い上(BatchNormがない)に、係数の容量の大半が不要な全結合層なので相当無駄が多いんですよね。なので、容量的な意味で軽そうなDenseNetでやります。学習済みモデルの一覧に詳しくはこちら。ResNet50やInceptionシリーズ、Xceptionなんかでやっても面白いと思いますよ。
DenseNetはボトルネックを挟みながらレイヤーを積み重ねていくという構造なので、モデルの構造上(L2正則化やドロップアウトを入れなくても)正則化効果があります。普通の転移学習だと全結合層前のレイヤー少しを訓練して終わりですが、今回はモデルの半分以上を訓練させます。ちなみに全部訓練させようとするとGPUメモリが溢れます(DenseNetはメモリ食い虫なので仕方ないです)。
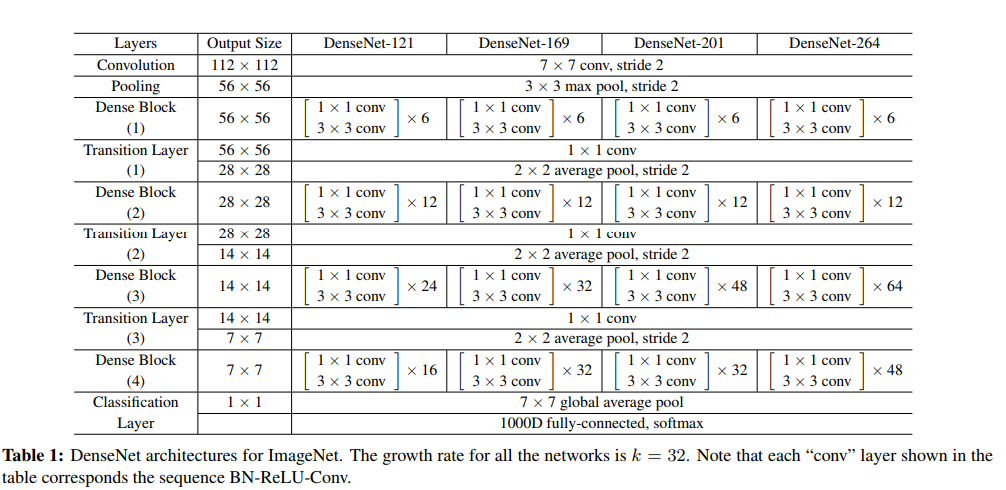
画像はDenseNetの論文より。DenseBlock(3)とDenseBlock(4)をファインチューニングします。6+12+24+16のうち24+16なので全体の2/3を再訓練ですね。でもColabのGPUを使えば1epoch2~4分でできるのでそこまで大変ではないですよ。
MixUpによるData Augmentation
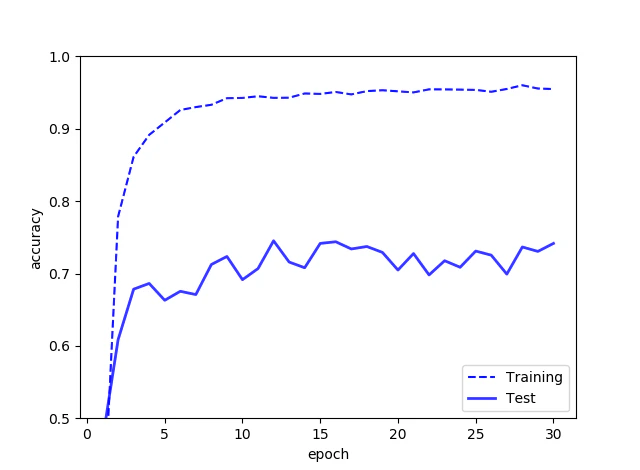
基本的にこのデータセット、クラス数の割にデータが足りなすぎるので、訓練精度99%に対してテスト精度50%ぐらいのオーバーフィッティングを起こします。オーバーフィッティングはデータ数で大きく改善されます。
一番は生の訓練データを集めてくることなのですがそこまでやる気力がないので、「データが足りない?ならば水増し(Data Augmentation)だ」でいきます。MixUpは元の論文がありますが、発想がすごい単純なので解説記事読んだほうが速いと思います。$X_1, X_2$という2つの画像があったとしたら、
$$X = \lambda X_1 + (1-\lambda) X_2 \qquad \lambda\sim Be(\alpha, \alpha)$$
これだけ。$Be(\cdot)$はベータ分布です。numpy.random.betaで出てくるのでそういうものだと思ってください。詳しいこと知りたい方はこちらを読んでください。ちなみにMixUpのαは0.2としました。
この他にDenseNetのConvレイヤーにWeightDecay0.01を入れ、従来のPaddingしてずらす、水平反転、回転などのData Augmentationも入れます。とにかく「これでもかこれでもか」と正則化を入れました。
コードはこちらから。
https://gist.github.com/koshian2/cb31c3dce9ba05dabbe72136afb0daeb
結果
30エポック訓練させ、**最大テスト精度は74.53%**でした。自分はさっきの画像見て75%正解できる自信がなかったので、想像よりも良かったです2。データが少ない割には健闘したと思います。
100%当てられたキャラ
せっかくなのでエラー分析しましょう。キャラ別に正解率を集計しました。まずはテストデータに対して100%当てられたキャラ。
| chara_name | n_sample | acc |
|---|---|---|
| 028_tainaka_ritsu | 86 | 1 |
| 084_okazaki_tomoya | 32 | 1 |
| 092_shindou_kei | 80 | 1 |
| 114_natsume_rin | 78 | 1 |
| 149_asakura_otome | 83 | 1 |
| 999_ito_chika | 51 | 1 |
テストデータに対して100%正解したのは、**田井中律(けいおん)、岡崎朋也(CLANNAD)、新藤景(ef)、棗鈴(リトバス)、朝倉音姫(D.C.II)、伊藤千佳(苺ましまろ)**となりました。n_sampleは訓練+テストデータの数です。実際に見てみましょう。上が訓練データ、下がテストデータです。


確かにキャラごとに特徴があり(田井中律ならおでこ、新藤景ならヘアバンド、伊藤千佳だったら丸い輪郭など)、trainとtestで似たような構図が多いですね。これなら当てられそうな感じはします。
ちなみにデータ数と精度に相関はあるかを見てみました。
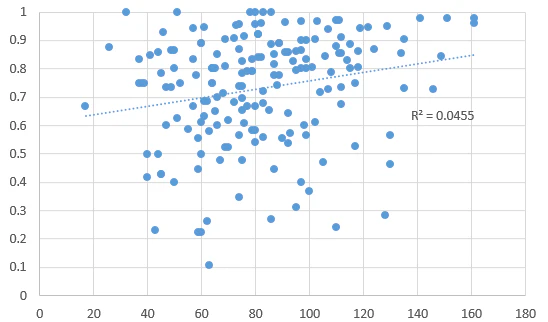
横軸が訓練+テストのデータ数、縦軸がテスト精度です。ほとんど関係はなさそうですね。
次に当てられなかったキャラを見てみましょう。
最も当てられなかったキャラ
| chara_name | n_sample | acc |
|---|---|---|
| 083_shirou_kamui | 63 | 0.105263158 |
| 191_shidou_hikaru | 59 | 0.222222222 |
| 198_nogizaka_haruka | 60 | 0.222222222 |
| 171_ikari_shinji | 43 | 0.230769231 |
| 014_hiiragi_kagami | 110 | 0.242424242 |
| 125_sakai_yuuji | 62 | 0.263157895 |
**最も当てられなかったキャラは、司狼神威(X)、獅堂光(魔法騎士レイアース)、乃木坂春香(乃木坂春香の秘密)、碇シンジ(新世紀エヴァンゲリオン)、柊かがみ(らき☆すた)、坂井悠二(灼眼のシャナ)**となりました。


一番上の司狼神威は背景と顔のタッチがまちまちでこれは当てられなくても仕方ないと思います。碇シンジ、坂井悠二、司狼神威を混ぜると人間でも間違えると思います。主人公キャラが髪型が似ていて、似たような顔だと間違えるんでしょうね。アニメキャラを見分けたいときは男キャラのデータを増やすといいかもしれません。
あと興味深いのは「柊かがみ」です。実はこのデータセットに双子の姉妹の「柊つかさ」の画像があり、これと間違えたのではないかという疑問が浮かびます。確かめてみましょう。
クラス番号14が柊かがみで、23番が柊つかさです。Ground truthが「柊かがみ」の推定を見てみましょう。
> print(pred_class[y_test==14])
[14 23 14 23 14 23 23 23 23 23 23 14 23 14 23 14 23 23 14 23 23 38 23 23
23 23 23 23 14 23 23 23 23]
やっぱり、柊つかさと間違えてますね。こういうことディープラーニングでわかるのとても興味深いです。1個だけ間違えている38は高良みゆき(同じらき☆すたのキャラです)です。ちなみにGround truthが「柊つかさ」の推定を見てみましょう。
> print(pred_class[y_test==23])
[23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 42 23 23 23 23
23 23 23 23 23 23 23 23 23]
つかさのほうはほとんど合っています。1個だけ間違えた42番は月村真由(ご愁傷さま二ノ宮くん)です。最後に柊かがみと柊つかさを市松模様状に並べてみました。

なるほどよくわからん
これを本気で見分けたかったらつかさとかがみのデータ相当必要そうですね。
人間でもよくわからないものはAIでもよくわからないんですね、ということで終わりにします。楽しいデータセットでした。皆さんも興味があったら遊んでみてください。自分もまた今度遊んでみます。
-
実は顔認証のアルゴリズムの使えばもっと簡単にできますが、ここではやりません ↩
-
CIFAR-10よりもクラス数の多い、CIFAR-100が100クラスで5万画像なので、1クラスあたりの画像は平均500枚です。この世界最高のスコアが2017年時点で84.80%なので、1クラスあたりの画像数が7~8倍差で少ないこのAnimeFaceデータセットで75%近く出ているのは、自分はかなり高いほうではないかなと考えます。ベンチマークはこちら https://benchmarks.ai/cifar-100 ↩