皆さんはビッグデータを扱うときどのような形式で保存していますか?ここでいうビッグデータとは数GB~数十GB(笑)のJSONです。MongoDBのようなNoSQLなデータベース使う?素晴らしいと思います。PostgreSQLでJSONを使う?とても良いと思います。
ここでは、データベースという枠組みから外れて、「ファイルシステム」を中心に手軽に**お安く(ここポイント)**ビッグデータを扱うことを考えます。なので、この方法は最速ではありませんし、個人がちょっと遊んでみようというときに気楽にできる”チープ”な物です1。企業でやるならちゃんとしたデータベースを使うべきです。その前提で読んでみてください(ちょっと長いです)。
ファイルシステムは、テキストファイルやZipアーカイブといったただのファイルです。ただのファイルなので、データベースが得意なインデックスも効きませんし、検索や結合も弱いですし、同時接続やトランザクションの管理という器用なことはできません。ただ、頭から最後まで全部読むのにはそこそこ強いです。以下の記事は、MessagePackを使ってデータ分析をしている素晴らしい内容です。背景となっている状況が結構被っているのでぜひ読むことをおすすめします。
MessagePackを使ったデータ分析のすすめ
https://qiita.com/m_mizutani/items/c40295549c3368a4257d
目的と環境
この投稿では、ビッグデータ()の例として某仮想通貨の公開データを用います。自分が書いた記事で恐縮ですが、以前書いた記事の続きです。JSON1個あたりこのようになっています(4~5KB)。このJSONからlast_price.priceとtimstampを抜き出す操作をしてパフォーマンスを検証します。

このようなJSONが1日あたり6万件程度送られてきます。23日分のデータをUTF-8エンコードの無圧縮テキストで記録すると次のようになります。あまりにファイルアクセスが遅すぎたのでSSDに移しました。
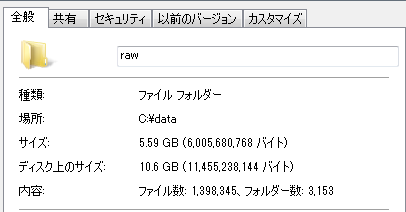
ファイル数:1,398,345個、合計サイズ5.59GBです。1日あたり無圧縮で250MB程度です。フォルダは日単位→10分単位でデータを区切るように設定しています。
このデータを実際分析するとき、データをメモリに格納できればそれが一番速いですが、全てで5.6GBなので、丸ごとメモリにインポートするのはきつくなっていきます。HDDにすら載せきれないTB、PB単位の本物のビッグデータはもはや個人で扱うものではないので関知しません。
データベースを使わない場合、とにかくファイルシステムのオーバーヘッドと戦うことになります。本稿ではまず、ファイルシステムを使った例として、無圧縮のテキストとZipアーカイブで固めた場合を比較し、読み込みのオーバーヘッドがどの程度変わるのかを体感します。次に、DBを使った例としてPostgreSQLとMongoDBからロードして速さを体感します。最後にファイルシステムに戻り、圧縮・シリアル化のフォーマットを変えていって、DBに近い速度で読み込ませることを目標とする結構無謀な企画です。
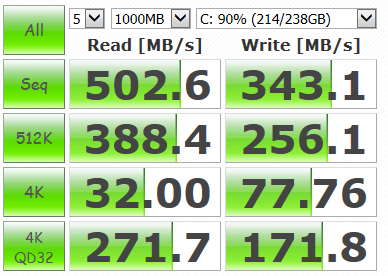
基本的にIOがボトルネックになるため、ストレージの転送速度を上げることが重要です。HDDではなくSSDを使うのはとてもメリットが多いです。書き込み先は全てSSDで、CrystalDiskMarkでのベンチマークは以下の通りです。
基本的にC#で行いますが、Linux環境でも読み書きできることを保ちたいのでPythonでも実行できることを目指します。ファイル圧縮を1から独自のフォーマットで書いていくようなことはしません。
環境:.NET Framework 4.5.2、PostgreSQL 10.2、MongoDB v3.6.2(x86_64)
C#ライブラリ:Utf8Json v1.3.7(2018/1/30)、MessagePack v1.7.3.4(2018/1/30)、IonKiwi.lz4.net v1.0.10(2017/12/6)、Npgsql v3.2.6(2017/12/3)、MongoDB.Driver v2.5.0(2017/12/13)、SharpCompress v0.19.2(2017/12/16)
ファイルシステム編(1)
[F1]PlainText
テキストファイルを全部読み込むだけの簡単なお仕事。
var rawRootDir = @"C:\data\raw";
var rawDirs = Directory.GetDirectories(rawRootDir)
.SelectMany(x => Directory.GetDirectories(x));
var sw = new Stopwatch();
sw.Start();
foreach (var dir in rawDirs)
{
Console.WriteLine(dir);
foreach (var file in Directory.GetFiles(dir))
{
var binary = File.ReadAllBytes(file);
}
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
容量:5.59GB(サイズ)、10.6GB(ディスク上のサイズ):エクスプローラーで確認
読み込み時間:01:44:01.2668862
すごく重いし、すごく遅い。やってられない。
[F2]Zipファイル
Zipで固めるとちょっとマシになります。System.IO.Compressionを(ダメだったらSystem.IO.Compression.FileSystemも)参照に追加しておきます。Plain Textほど遅くないのでJSONパースを入れてみます。JSONパースはUtf8Jsonを使います。
//using System.IO.Compression;
var destRootDir = @"C:\data\zip";
var zips = Directory.GetFileSystemEntries(destRootDir, "*.zip", SearchOption.AllDirectories);
var sw = new Stopwatch();
sw.Start();
foreach (var zip in zips)
{
using (var archive = ZipFile.OpenRead(zip))
{
foreach (var entry in archive.Entries)
{
var obj = JsonSerializer.Deserialize<JsonData>(entry.Open());
}
}
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
public class JsonData
{
public string timestamp { get; set; }
public LastPrice last_price { get; set; }
public class LastPrice
{
public double price { get; set; }
}
}
容量:1.08GB(エクスプローラー上でのサイズ)
読み込み時間:00:02:46.2418295(JSONパースなしの場合は00:02:14.1958927)
Zipで固めただけでだいぶマシになりました。JSONパースなしの場合はPlain Textの場合と同様に、バイナリを変数に代入して終了させています。Utf8Jsonはやーい!
バイナリまで読んでしまったらあとはJsonパース部分はファイルフォーマットによらないので、以下全部パースする場合で計測します。だいたい30秒マイナスすれば素の解凍時間になります。
データベース編
[D1]PostgreSQL
以下の定義でデータテーブルを作ります。PostgreSQLの日付の扱いについては拙作の記事でグダグダと書いたのでよろしければ。
| カラム | 制約 | データ型 |
|---|---|---|
| ts | PrimaryKey | TIMESTAMP |
| json | - | JSONB |
コンソールからサーバーを起動して、データベースを作っておきます。
> pg_ctl start -D C:\psql\data
> psql -U postgres
postgres=# CREATE DATABASE currency;
データ挿入。.msg.lz4というのは後で出てくるMessagePack+LZ4のアーカイブ形式です。Npgsqlを用います。
//using MessagePack;
//using lz4;
//using Npgsql;
//using Utf8Json;
var builder = new NpgsqlConnectionStringBuilder()
{
Host = "localhost",
Port = 5432,
Database = "currency",
Username = "postgres",
Password = "postgres"
};
var msgRootDir = @"C:\data\msglz4";
var lz4Files = Directory.EnumerateFiles(msgRootDir, "*.msg.lz4", SearchOption.AllDirectories);
using (var con = new NpgsqlConnection(builder.ConnectionString))
{
con.Open();
using (var cmd = new NpgsqlCommand())
{
cmd.Connection = con;
//CREATE TABLE
cmd.CommandText = "CREATE TABLE IF NOT EXISTS btcjpy(" +
"ts TIMESTAMP PRIMARY KEY," +
"json JSONB)";
cmd.ExecuteNonQuery();
//INSERT
foreach (var lz in lz4Files)
{
Console.WriteLine(lz);
IEnumerable<Tuple<DateTime, string>> vals;
using (var fs = new FileStream(lz, FileMode.Open, FileAccess.Read))
using (var lz4Stream = LZ4Stream.CreateDecompressor(fs, LZ4StreamMode.Read))
{
var binaries = MessagePackSerializer.Deserialize<byte[][]>(lz4Stream);
var jsons = binaries.Select(x => Encoding.UTF8.GetString(x));
vals = jsons.Select(x => new Tuple<DateTime, string>(
DateTime.Parse(JsonSerializer.Deserialize<JsonData>(x).timestamp), x));
}
//Binary COPY
using (var writer = con.BeginBinaryImport(
"COPY btcjpy(ts, json) FROM STDIN (FORMAT BINARY)"))
{
foreach (var v in vals)
{
writer.StartRow();
writer.Write(v.Item1, NpgsqlTypes.NpgsqlDbType.Timestamp);
writer.Write(v.Item2, NpgsqlTypes.NpgsqlDbType.Jsonb);
}
}
}
}
}
5~6分で挿入完了です。データ数の確認。
currency=# SELECT count(*) FROM btcjpy;
count
---------
1398345
(1 row)
データテーブルのサイズは以下の通り。
currency=# SELECT relname,
currency-# pg_size_pretty(pg_total_relation_size(relid)) AS totalsize,
currency-# pg_size_pretty(pg_table_size(relid)) AS tablesize,
currency-# pg_size_pretty(pg_indexes_size(relid)) AS indexsize
currency-# FROM pg_stat_user_tables;
relname | totalsize | tablesize | indexsize
---------+-----------+-----------+-----------
btcjpy | 1614 MB | 1584 MB | 30 MB
(1 row)
データの読み込み。全部読むだけなのであまりDBの恩恵を感じられないかもしれません。
//using Npgsql;
public static void _Main(string[] args)
{
var builder = new NpgsqlConnectionStringBuilder()
{
Host = "localhost",
Port = 5432,
Database = "currency",
Username = "postgres",
Password = "postgres"
};
using (var con = new NpgsqlConnection(builder.ConnectionString))
{
con.Open();
using (var cmd = new NpgsqlCommand())
{
cmd.Connection = con;
var sw = new Stopwatch();
sw.Start();
//SELECT
cmd.CommandText =
"SELECT json->'timestamp' AS time, json->'last_price'->'price' AS price FROM btcjpy";
using (var reader = cmd.ExecuteReader())
{
while (reader.Read())
{
var time = (string)reader["time"];
var price = Convert.ToDouble(reader["price"]);
}
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
}
}
}
サイズ:1.58GB
読み込み時間(中央値):00:00:19.8031381(他00:00:19.5927425、00:00:19.8031381)
さすが本業のDB強い。JSONBでバイナリ対応になって若干サイズも縮んでいます(Zipよりやや圧縮が悪いぐらい)。PostgreSQLのロードマップを見ていると、将来圧縮に対応する予定もあるそうなので期待しましょう。これでインデックススキャンできるのだから大したものです。
SQL全般的に設定項目が多いのでチューニングを気にして本末転倒にならないように注意してください。特に設定せずに8GBぐらいのデータテーブルを頭から最後まで読んだら10GBメモリアロケーションされたので、大規模なテーブルを読むときはCPU、IO、メモリ全部に気を遣う必要があります。
DBの場合はお片付けも忘れずに。
currency-# DROP TABLE btcjpy;
currency-# \q
> pg_ctl stop -D C:\psql\data
[D2]MongoDB
JSONのDBといったらこれです。設定ファイルは以下のようにしました。
systemLog:
destination: file
path: C:\mongodb\server\log\mongod.log
storage:
dbPath: C:\mongodb\server\data
engine: wiredTiger
journal:
enabled: false
wiredTiger:
engineConfig:
cacheSizeGB: 2
statisticsLogDelaySecs: 0
journalCompressor: none
directoryForIndexes: false
collectionConfig:
blockCompressor: snappy
indexConfig:
prefixCompression: false
Snappyで圧縮をかけます。最新のMongoDBだとデフォルトで圧縮かかっているみたいですね。MongoDBはinit_dbしなくていいのが楽です。サーバーを起動します。
> mongod --config C:\mongodb\server\mongod.cfg
確認用に別のコンソールでクライアントも起動しておきます。
> mongo
挿入用コード。MongoDB.NET Driverを用います。
//using MongoDB.Bson;
//using MongoDB.Bson.Serialization;
//using MongoDB.Driver;
//using lz4;
//using MessagePack;
public static void _Main(string[] args)
{
var client = new MongoClient("mongodb://localhost:27017");
var db = client.GetDatabase("currency");
var collection = db.GetCollection<BsonDocument>("btcjpy");
var msgRootDir = @"C:\data\msglz4";
var lz4Files = Directory.EnumerateFiles(msgRootDir, "*.msg.lz4", SearchOption.AllDirectories);
var sw = new Stopwatch();
sw.Start();
foreach (var lz in lz4Files)
{
Console.WriteLine(lz);
byte[][] binaries;
using (var fs = new FileStream(lz, FileMode.Open, FileAccess.Read))
using (var lz4Stream = LZ4Stream.CreateDecompressor(fs, LZ4StreamMode.Read))
{
binaries = MessagePackSerializer.Deserialize<byte[][]>(lz4Stream);
}
//JsonBinary → BsonArray
var bsonArray = binaries
.Select(x => Encoding.UTF8.GetString(x))
.Select(rawjson => BsonSerializer.Deserialize<BsonDocument>(rawjson));
collection.InsertMany(bsonArray);
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
}
挿入終わるまで20分ぐらい。JSON→BSONへの変換に時間かかってここがボトルネックになってしまうのがもうちょっと上手く行けばと思いました(BSONがJSONのバイナリだからと言って読み込んだUTF8のバイナリをそのままぶち込むのはダメだし)。
> show dbs
admin 0.000GB
config 0.000GB
currency 1.544GB
local 0.000GB
容量を調べると1.54GB。PostgreSQLとあんまり変わりません。読み込みはこうです。
//using MongoDB.Bson;
//using MongoDB.Driver;
var client = new MongoClient("mongodb://localhost:27017");
var db = client.GetDatabase("currency");
var collection = db.GetCollection<BsonDocument>("btcjpy");
var sw = new Stopwatch();
sw.Start();
foreach (var data in collection.Find(FilterDefinition<BsonDocument>.Empty)
.Project("{timestamp:1, \"last_price.price\":1, _id:0}").ToList())
{
var values = data.Values.ToList();
var dic = (Dictionary<string, object>)BsonTypeMapper.MapToDotNetValue(values[0]);
var price = (double)dic["price"];
var time = values[1].AsString;
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
ネスト構造まではうまく消せなかったので、読み込むときに絞ってあとアプリ側でいじる作戦で。
サイズ:1.54GB
読み込み時間(中央値):00:00:15.8827782(00:00:16.1628182、00:00:14.9827487)
インデックスを張っていない違いはあれど、PostgreSQLより若干速い。MongoDBはクエリ実行時ではなく、サーバーが動いている限りメモリを食った状態で常駐しているので気になるといえば気になるかもしれません。
DBのお片付けもちゃんとしましょう。クライアントのコンソール側から。
> use currency
> db.dropDatabase();
> use admin
> db.shutdownServer();
> quit()
もういらねえやこの作業ファイル!でエクスプローラーから消しても、ちゃんとDBを初期化してくれるのいいところだと思います。SQLは下手に消すと動かなくなるので。
ファイルシステム編(2)
結論としてはDBほどの速度はでませんが、DBよりは容量は縮みます。Zipの読み込み時間が2分46秒なので、1分切りを目指します。
[F3]tar.gz
Linuxでよく用いられているアーカイブ形式です。Pythonの場合はtarfileというモジュールが組み込みでついてくるので、Pythonが使えればルート権限は不要です。コマンドからもできます。Pythonからの使い方は公式ドキュメントを参照
Zipファイルから一時ファイルに書き出さずにメモリを中継して圧縮させる方法です。C#ではSharpCompressを使います。オンザフライでの書き込みはストリームの数が多くなると同期を取るのが結構難しくになり、下手をしなくてもアーカイブが壊れるのでとても注意してください。特にこのライブラリはデリケートです(そこそこハマった)。SharpZipLibのほうが扱いやすいですがNuGetに上がっているバージョン若干遅いです(解凍でSharpCompressの3~4倍時間がかかる)。
下記のコードのように、いったんメモリ上に読み込んだファイルをバッファリングしながら丁寧に書いていくと壊れません。
//using SharpCompress.Readers;
//using SharpCompress.Writers;
//using System.Diagnostics;
//using System.IO;
var zipRootDir = @"C:\data\zip";
var zipFiles = Directory.EnumerateFiles(zipRootDir, "*.zip", SearchOption.AllDirectories);
var destRootDir = @"C:\data\targz";
foreach (var zip in zipFiles)
{
var destFileName = zip.Replace(zipRootDir, destRootDir).Replace(".zip", ".tar.gz");
var destDirectory = Path.GetDirectoryName(destFileName);
var tarEntryName = Path.GetFileName(destFileName).Replace("tar.gz", ".tar");
if (!Directory.Exists(destDirectory)) Directory.CreateDirectory(destDirectory);
using (var tarMs = new MemoryStream())
{
//Zip Read
var tmpdata = new List<Tuple<string, byte[]>>();
using (var infs = new FileStream(zip, FileMode.Open, FileAccess.Read))
using (var zipReader = ReaderFactory.Open(infs, new ReaderOptions()))
{
while (zipReader.MoveToNextEntry())
{
if (!zipReader.Entry.IsDirectory)
{
using (var ms = new MemoryStream())
{
using (var entryStream = zipReader.OpenEntryStream())
{
entryStream.CopyTo(ms);
}
var item = new Tuple<string, byte[]>(zipReader.Entry.Key, ms.ToArray());
tmpdata.Add(item);
}
}
}
}
//Create Tar
using (var tarWriter = WriterFactory.Open(tarMs, SharpCompress.Common.ArchiveType.Tar,
new WriterOptions(SharpCompress.Common.CompressionType.None) { LeaveStreamOpen = true }))
{
foreach(var item in tmpdata)
{
using (var ms = new MemoryStream(item.Item2))
{
tarWriter.Write(item.Item1, ms, DateTime.Now);
}
}
}
tarMs.Position = 0;
//Compress Gzip
using (var outfs = new FileStream(destFileName, FileMode.Create, FileAccess.Write))
using (var gzWriter = WriterFactory.Open(outfs, SharpCompress.Common.ArchiveType.GZip,
new WriterOptions(SharpCompress.Common.CompressionType.GZip) { LeaveStreamOpen = true }))
{
gzWriter.Write(tarEntryName, tarMs, DateTime.Now);
}
}
}
5分で圧縮が完了しました。メモリ上に逐次解凍して読み込みます。
//using SharpCompress.Readers;
//using System.Diagnostics;
//using System.IO;
//using Utf8Json;
var zipRootDir = @"C:\data\targz";
var zipFiles = Directory.EnumerateFiles(zipRootDir, "*.tar.gz", SearchOption.AllDirectories);
var sw = new Stopwatch();
sw.Start();
foreach(var archive in zipFiles)
{
using (var fs = new FileStream(archive, FileMode.Open, FileAccess.Read))
using (var reader = ReaderFactory.Open(fs))
{
while(reader.MoveToNextEntry())
{
if(!reader.Entry.IsDirectory)
{
using (var ms = new MemoryStream())
{
using (var entryStream = reader.OpenEntryStream())
entryStream.CopyTo(ms);
ms.Position = 0;
var obj = JsonSerializer.Deserialize<JsonData>(ms);
}
}
}
}
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
サイズ:211MB(ディスク上は217MB)
読み込み時間:00:01:39.3375536(3回やった中間値:1:39~1:47)
Zipよりちょっと速くなり、ファイルサイズは結構縮みました。サイズ面では既にDBに勝っています。
[F4]Tar.xz
圧縮率重視のフォーマットとしてTar.xzがあります。これは7zipに似たLZMA系統の圧縮で、7zipと違いLinuxでも結構簡単に扱えます。Pythonでは組み込みモジュールで読み書きできます(C#もtarアーカイブぐらい組み込みで用意してもいいと思うんですけどね…)。
Tar.xzのC#の読み書きはこちらでも書きました。圧縮。SharpCompressにはXZがないので、TarのみSharpCompressで行い、XZはXZ.NETで行います。他にLZMA SDKが必要です。Pythonでは特にインストールは必要ありません。
using System.IO;
using SharpCompress.Readers;
using SharpCompress.Writers;
using XZ.NET;
var zipRootDir = @"C:\data\zip";
var zipFiles = Directory.EnumerateFiles(zipRootDir, "*.zip", SearchOption.AllDirectories);
var destRootDir = @"C:\data\tarxz";
foreach (var zip in zipFiles)
{
var destFileName = zip.Replace(zipRootDir, destRootDir).Replace(".zip", ".tar.xz");
var destDirectory = Path.GetDirectoryName(destFileName);
if (!Directory.Exists(destDirectory)) Directory.CreateDirectory(destDirectory);
using (var tarMs = new MemoryStream())
{
//Zip Read
var tmpdata = new List<Tuple<string, byte[], DateTime?>>();
using (var infs = new FileStream(zip, FileMode.Open, FileAccess.Read))
using (var zipReader = ReaderFactory.Open(infs, new ReaderOptions()))
{
while (zipReader.MoveToNextEntry())
{
if (!zipReader.Entry.IsDirectory)
{
using (var ms = new MemoryStream())
{
using (var entryStream = zipReader.OpenEntryStream())
{
entryStream.CopyTo(ms);
}
var item = new Tuple<string, byte[], DateTime?>(zipReader.Entry.Key, ms.ToArray(), zipReader.Entry.ArchivedTime);
tmpdata.Add(item);
}
}
}
}
//Create Tar
using (var tarWriter = WriterFactory.Open(tarMs, SharpCompress.Common.ArchiveType.Tar,
new WriterOptions(SharpCompress.Common.CompressionType.None) { LeaveStreamOpen = true }))
{
foreach (var item in tmpdata)
{
using (var ms = new MemoryStream(item.Item2))
{
tarWriter.Write(item.Item1, ms, DateTime.Now);
}
}
}
tarMs.Position = 0;
//Compress XZ
using (var outfs = new FileStream(destFileName, FileMode.Create, FileAccess.Write))
using (var xzStream = new XZOutputStream(outfs))
{
var buf = new byte[1 * 1024 * 1024];
var bytesRead = (long)0;
while (bytesRead < tarMs.Length)
{
var count = tarMs.Read(buf, 0, buf.Length);
xzStream.Write(buf, 0, count);
bytesRead += count;
}
}
}
}
圧縮は20分ちょいでした。サイズを縮めているだけあって遅いです。解凍。
//using System.IO;
//using System.Diagnostics;
//using SharpCompress.Readers;
//using XZ.NET;
//using Utf8Json;
var zipRootDir = @"C:\data\tarxz";
var zipFiles = Directory.EnumerateFiles(zipRootDir, "*.tar.xz", SearchOption.AllDirectories);
var sw = new Stopwatch();
sw.Start();
foreach (var archive in zipFiles)
{
using (var fs = new FileStream(archive, FileMode.Open, FileAccess.Read))
using (var xzStream = new XZInputStream(fs))
using (var tarMs = new MemoryStream())
{
xzStream.CopyTo(tarMs);
tarMs.Position = 0;
using (var tarReader = ReaderFactory.Open(tarMs))
{
while (tarReader.MoveToNextEntry())
{
if (!tarReader.Entry.IsDirectory)
{
using (var entryMs = new MemoryStream())
using (var entryStream = tarReader.OpenEntryStream())
{
entryStream.CopyTo(entryMs);
entryMs.Position = 0;
var obj = JsonSerializer.Deserialize<JsonData>(entryMs);
}
}
}
}
}
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
サイズ:135MB(ディスク上は141MB)
読み込み時間:00:01:41.1453396(3回の中央値、1:40~1:44)
LZMA系なので読み込みも遅いかなと思いましたが、まさかのgzip並の読み込み速度が出てびっくり。圧縮率がすごく良い(Plain Textでは5.6GBもあったことを思い出しましょう)ので、圧縮速度がいらない場合は結構ありかもしれません。同じLZMA系にLZIPもありますが、今回は省略します。暇な方はやってみてください。
[F5]MessagePack+LZ4
neuecc先生の傑作ライブラリ、MessagePack for C#があります。これにLZ4フォーマット(速度特化のフォーマットです)がついていたので、これを参考にしました。
ただし、MessagePack for C#のライブラリのLZ4フォーマットはFrame Formatではないので(2018年1月末時点)、LZ4圧縮の部分は相互運用性の観点からFrame Formatが使えるIonKiwi.lz4.netを用います。Frame Formatの問題は以前書いたのでよろしければ参考にしてください。リンクの記事にPythonでの圧縮・解凍方法もあります。したがって、ルート権限があればMessagePack+LZ4でもPythonと相互運用できます。Pythonと相互運用できればLinux環境でも全然使えます(自分は今VPS環境とやり取りするときにこの方式を使っています)。
MessagePackもLZ4もアーカイブ機能はないので、バイナリを配列としてつなぎ合わせて擬似アーカイブにします。ファイル名やファイルの種類とかそういう情報は落ちるのですが、まあそういうのを気にしない用途向けで(格納するデータ側にタイムスタンプがあるとかそういう用途)。もちろんMessagePackもJSONみたいなものなので、定義すればそういった情報を保持できます。
前置きが長くなってしまいましたが、C#での圧縮です。MessagePackとIonKiwi.lz4.netをNugetからダウンロードしておきます。
//using System.IO;
//using MessagePack;
//using System.Diagnostics;
//using lz4;
var zipRootDir = @"C:\data\zip";
var zipFiles = Directory.EnumerateFiles(zipRootDir, "*.zip", SearchOption.AllDirectories);
var destRootDir = @"C:\data\msglz4";
foreach (var zip in zipFiles)
{
var binaries = new List<byte[]>();
using (var archive = ZipFile.OpenRead(zip))
{
foreach (var entry in archive.Entries)
{
using (var ms = new MemoryStream())
{
entry.Open().CopyTo(ms);
binaries.Add(ms.ToArray());
}
}
}
var msgpack = MessagePackSerializer.Serialize<byte[][]>(binaries.ToArray());
var destFileName = zip.Replace(zipRootDir, destRootDir).Replace(".zip", ".msg.lz4");
var destDir = Path.GetDirectoryName(destFileName);
if (!Directory.Exists(destDir)) Directory.CreateDirectory(destDir);
using (var fs = new FileStream(destFileName, FileMode.Create, FileAccess.Write))
using (var lz4 = LZ4Stream.CreateCompressor(fs, LZ4StreamMode.Write))
{
lz4.Write(msgpack, 0, msgpack.Length);
}
}
圧縮は3分程度で終わりました。はやーい。解凍。
//using System.IO;
//using System.Diagnostics;
//using MessagePack;
//using lz4;
//using Utf8Json;
var msgRootDir = @"C:\data\msglz4";
var lz4Files = Directory.EnumerateFiles(msgRootDir, "*.msg.lz4", SearchOption.AllDirectories);
//MsgLz4 Read with JsonDecode
var sw = new Stopwatch();
sw.Start();
foreach (var lz in lz4Files)
{
byte[][] binaries;
using (var fs = new FileStream(lz, FileMode.Open, FileAccess.Read))
using (var lz4Stream = LZ4Stream.CreateDecompressor(fs, LZ4StreamMode.Read))
{
binaries = MessagePackSerializer.Deserialize<byte[][]>(lz4Stream);
}
foreach(var b in binaries)
{
var data = JsonSerializer.Deserialize<JsonData>(b);
}
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
サイズ:280MB(ディスク上は286MB)
読み込み時間:00:00:52.6152158(3回の中央値、全て52秒台)
ぶっちぎりで速いです。1分切りに成功しました。うち30秒ぐらいはJSONパース部分なので、残りの22秒で展開していることになります。速度面ではDBに勝つことはほぼ不可能ですが、容量はDBの1/6ぐらいになっているので、相当肉迫しているといえると思います。ファイルシステムも捨てたものではないです。
ただチェックサムが全くないので、そこら辺気にする方はMessagePackではなくtarに固めてからのほうがいいかもしれません。無圧縮tarならほとんど速度落ちませんので。
まとめ
| 形式 | ファイルorDB | 読み込み時間 | サイズ(MB) | 要インストール | Linuxでのルート権限 |
|---|---|---|---|---|---|
| PostgreSQL | DB | 00:19.803 | 1,614 | ○ | ○ |
| MongoDB | DB | 00:15.883 | 1,581 | ○ | ○ |
| Plain Text | File | 104:01.267 | 5,727 | × | × |
| Zip | File | 02:46.242 | 1,112 | × | × |
| Tar.gz | File | 01:39.338 | 211 | × | × |
| Tar.xz | File | 01:41.145 | 135 | × | × |
| MessagePack+LZ4 | File | 00:52.615 | 280 | × | ○ |
速度面ではファイルシステムで最速だったMessagePack+LZ4がデータベースを超えることはできませんでした。データベースにはこれにインデックスやら同時接続やトランザクションがついてくるので強すぎます。
ただ、データベースにも1つにも苦手なことがあって、インデックスつきでシャッフルされたデータで苦手です。別の記事で調べてみたのですが、PostgreSQLのBtreeインデックスはシャッフルされたか整列されたかどうかでソートが5,6倍かかるようになります。なので、うっかり「あっこの期間のデータ入れるの忘れちゃった」「これより前の期間のデータを追加しよう」というような状況に弱いです。ファイルシステムの場合は、アーカイブ単位で時系列を整理しておけば、事実上パス文字列のソートになり、アーカイブ単位のソートで結構お手軽になります。
ファイルシステムの強みは、容量の少なさ、手軽さ、必要スペックの少なさなどで、DBが得意とするような弱みを差し引いても結構いい勝負ではないかと思います。特に個人向きかなと思います。
普段はアーカイブとして保存しておいて、実際に使うときにローカルでデータベースに格納するのもありなので、やりたいことに合わせてうまく使い分けると快適になれるのではないかなと思います。
余談ですが、アーカイバー同士の比較はFenrirのページでも紹介されていました。圧縮率と時間のトレードオフ関係がわかりやすいです。
参考:Zip より Tar より QuickLZ が(サイズが大きいときは)便利です
https://blog.fenrir-inc.com/jp/2012/07/quicklz.html