Deep Learning の学習を高速でぶん回すには GPU の活用が欠かせないですよね!
12月1日についに Azure の GPU インスタンス (Azure N series) が GA (General Availability) になったので、
その N series で使える以下の3種類の OS の中から、
- Ubuntu 16.04 LTS
- Windows Server 2016
- Windows Server 2012 R2
Ubuntu 16.04 LTS を選んで、TensorFlow on GPU の環境構築方法をまとめました。
TensorFlow on GPU の環境構築完了までには、
- NVIDIA の GPU Driver を入れる
- CUDA Toolkit を入れる
- cuDNN を入れる
- TensorFlow GPU version を入れる
というそこそこ面倒な手順が必要になってくるので、そこら辺の情報が誰かの手助けになればと思います。
ちなみに、Azure N series は Visualize の NV と Compute の NC に分かれていて、NV では NVIDIA Tesla M60 、NC では NVIDIA Tesla K80 が使えるようになっています。
なので、Deep Learning のシナリオでは NC シリーズを使っていくことになります。
NC series の詳細のスペックは以下のようになります。
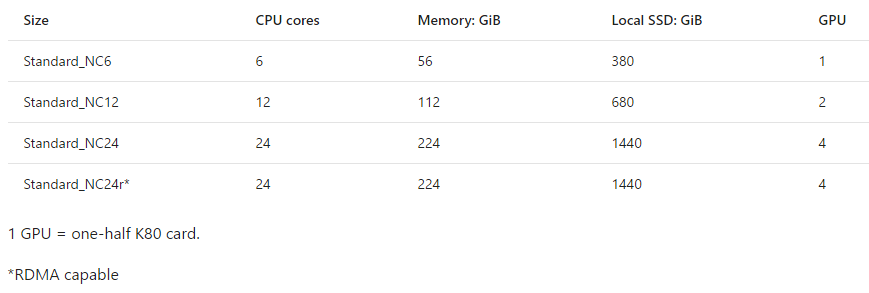
(参考公式ページ)
特筆すべきは、最上位のインスタンス (NC24r) が InfiniBand に対応していて広帯域・低遅延の通信が可能になり、複数 VM で並列に学習をぶん回すときにかなり高いパフォーマンスを期待できる点かなと思います。(クラウドの GPU インスタンスで対応しているのが Azure だけだった気がする。間違ってたら訂正ください。)
Azure Portal 上での GPU インスタンスのデプロイ
では、早速 Azure 上で GPU インスタンスをさくっと立てちゃいましょう!
まず、Azure のポータルの画面から Compute を押して Ubuntu Server 16.04 LTS を選択します。
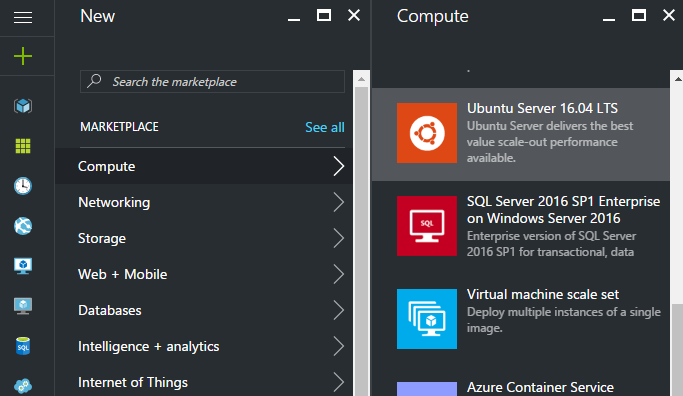
選んで Create を押すと、以下のような4つのステップが出てくるので順番に進めていきます。
まず、ステップ1です。
VM Disk Type を初期選択では SSD になっていますが、次の画面で GPU インスタンスを選択できるように HDD を選んでおきます。
また、NC seriesは現在(2016/12/12)は以下のリージョンのみで展開されています。
- South Central US
- East US
なので、今回は Location を South Central US に設定します。
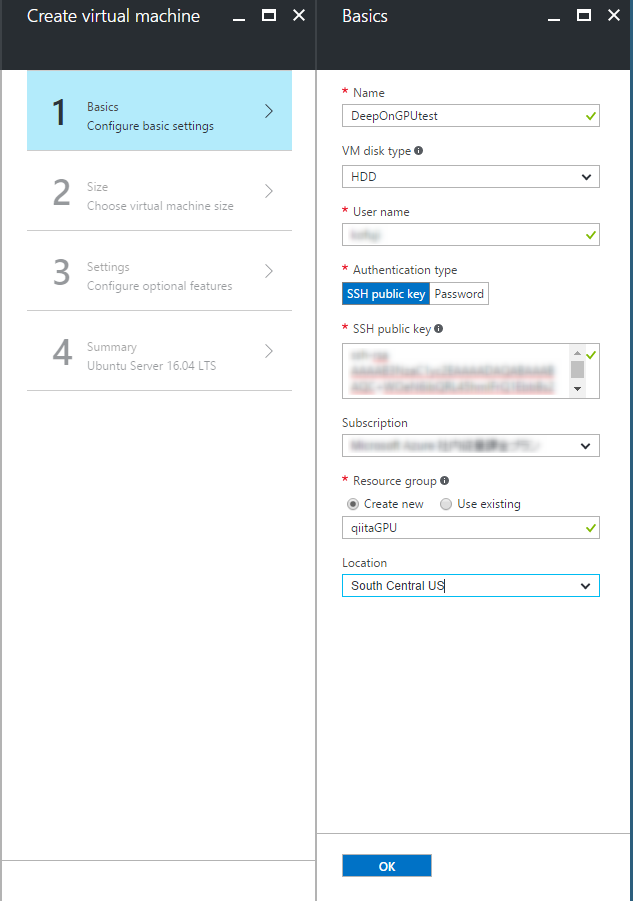
そうして OK を押すと、次にステップ2に進めて以下の画面が出てきます。View All を押すと NC シリーズも表示されるようになり、4種類から選べるようになっています。
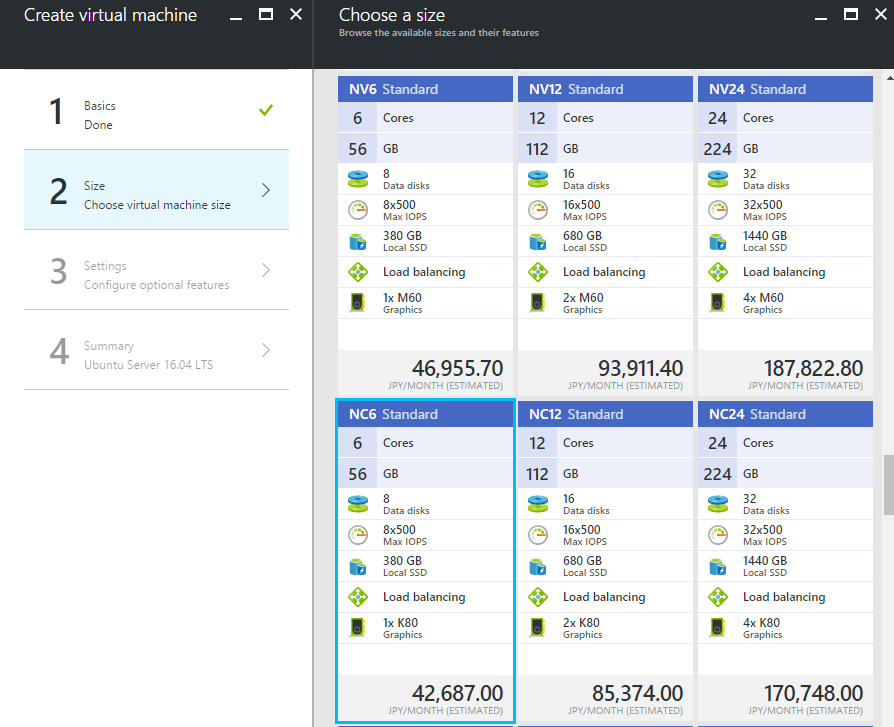
Deep Learning を活用するには NVIDIA Tesla K80 が使える NC series を選択します。
今回はその中でも一番安い NC6 シリーズを使います。
ステップ3、4の設定項目はデフォルトのまま OK を押してどんどん進んでいきます。
そうすると愛しい GPU インスタンスが生成されてきます。
2分ほど待てばデプロイが完了するので、画面に表示される IP アドレスに早速 ssh で繋ぎに行きます。
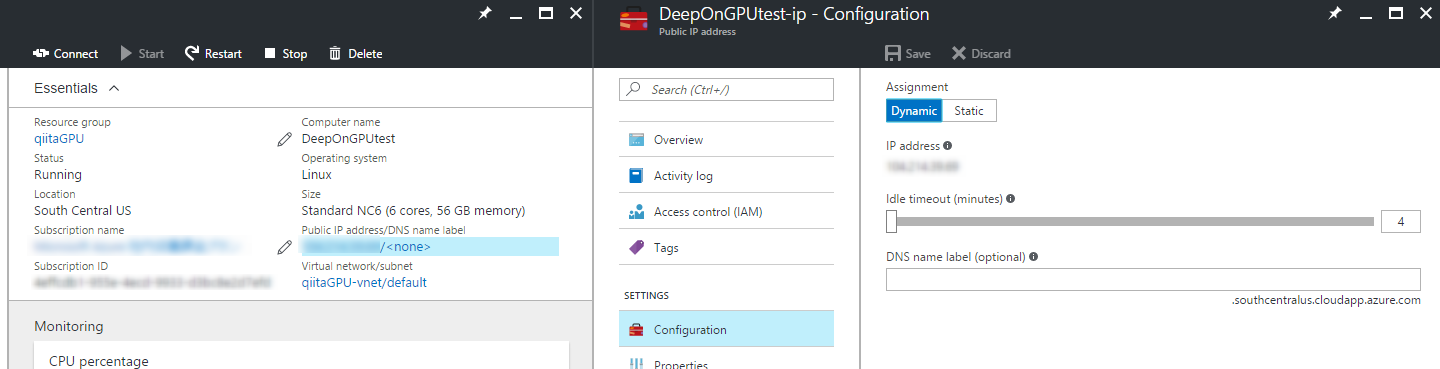
このタイミングで下の画像の右の項目から DNS 名を割り当ててあげるのもいいかもしれません。
ログインができたら、こちらのコマンドを打ってちゃんと GPU が認識されているか確認しましょう。
lspci | grep -i NVIDIA
そうするとこういう出力が返ってきます。

無事ちゃんと Tesla K80 が認識されてますね!
NVIDIA の GPU Driver のインストール
次にここから NVIDIA の GPU Driver ダウンロードをしてきてインストールをする必要があります。
ただ Ubuntu 16.04 LTS の場合は以下のコマンドでいけると思います。
gcc と make が必要となってくるのでこのタイミングで build-essential も入れておきます。
sudo apt-get install build-essential
wget http://us.download.nvidia.com/XFree86/Linux-x86_64/375.20/NVIDIA-Linux-x86_64-375.20.run
chmod +x NVIDIA-Linux-x86_64-375.20.run
sudo ./NVIDIA-Linux-x86_64-375.20.run
CUDA Toolkit のインストール
次に CUDA Toolkit 8.0 を入れます。
ここから OS 等々を選んで該当するものをダウンロードするのですが、
Ubuntu 16.04 であれば以下のコマンドでいけると思います。
wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.44-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1604_8.0.44-1_amd64.deb
sudo apt-get update
sudo apt-get install cuda
こちらはインストール完了まで 10分ちょっとかかると思います。
インストールが成功しているかを確認してみましょう。
以下のコマンドを順に実行してください。
cd /usr/local/cuda-8.0/bin
sudo ./cuda-install-samples-8.0.sh .
cd NVIDIA_CUDA-8.0_Samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
そうすると、こういう出力が返ってくると思います。
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla K80"
CUDA Driver Version / Runtime Version 8.0 / 8.0
CUDA Capability Major/Minor version number: 3.7
Total amount of global memory: 11440 MBytes (11995578368 bytes)
(13) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA Cores
GPU Max Clock rate: 824 MHz (0.82 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 36580 / 0 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 1, Device0 = Tesla K80
Result = PASS
無事 CUDA も入りました。
cuDNN のインストール
次に cuDNN のインストールが必要となります。
こちらからダウンロードをすることになりますが、Developer 登録をしないとダウンロードできないようになっているのでまず登録を行います。
登録完了後のダウンロードページ上では、
Download cuDNN v5.1 (August 10, 2016), for CUDA 8.0 を押して展開される中の cuDNN v5.1 Library for Linux
を選択してください。そうしてダウンロードできるファイルを scp コマンドでも FTP でもいいので、何かしらの方法でクラウド上のインスタンスにアップロードします。
アップロードが終わるとそれを解凍します。
tar zxvf cudnn-8.0-linux-x64-v5.1.tgz
解凍すると以下のファイルが直下に生成されます。
cuda/include/cudnn.h
cuda/lib64/libcudnn.so
cuda/lib64/libcudnn.so.5
cuda/lib64/libcudnn.so.5.1.5
cuda/lib64/libcudnn_static.a
しかるべき場所にコピーします。
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
以下をパスに追加します。
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
export CUDA_HOME=/usr/local/cuda
TensorFlow on GPU のインストール
ついに TensorFlow のインストールです!
ささっと Python の実行環境を構築します。
sudo apt-get install python3-pip python3-dev
後は公式のページの誘導に従います。
CUDA toolkit 8.0 と CuDNN v5 用のバイナリを用意してくれているので、それに乗っかって以下のコマンドでいれちゃいます。
# Ubuntu/Linux 64-bit, GPU enabled, Python 3.5
# Requires CUDA toolkit 8.0 and CuDNN v5. For other versions, see "Installing from sources" below.
$ export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-0.12.0rc0-cp35-cp35m-linux_x86_64.whl
# Python 3
$ sudo pip3 install --upgrade $TF_BINARY_URL
これで環境構築が完了したはずです。
Python3 系を動かして以下のコマンドを入れてみて成功を確認します。
>>> import tensorflow as tf
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcublas.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcudnn.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcufft.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcurand.so locally
>>> sess = tf.Session()
I tensorflow/core/common_runtime/gpu/gpu_device.cc:885] Found device 0 with properties:
name: Tesla K80
major: 3 minor: 7 memoryClockRate (GHz) 0.8235
pciBusID b148:00:00.0
Total memory: 11.17GiB
Free memory: 11.11GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:906] DMA: 0
I tensorflow/core/common_runtime/gpu/gpu_device.cc:916] 0: Y
I tensorflow/core/common_runtime/gpu/gpu_device.cc:975] Creating TensorFlow device (/gpu:0) -> (device: 0, name: Tesla K80, pci bus id: b148:00:00.0)
無事 GPU 上で TensorFlow が動いていることが確認できました!!