はじめに
G検定(ジェネラリスト検定)の学習において、音声処理の分野は専門用語が多く、混乱しやすいポイントの一つです。
本記事では、単に用語を羅列するのではなく、「AIが音声を処理する際の流れ」 に沿って体系的に整理しました。
学習の際、「今どの段階の話をしているのか」を意識することで、理解がスムーズになります。
音声処理の全体フロー
音声処理は、大きく以下の5つのステップで構成されます。

- 【タスク】:何をしたいのか(目的)
- 【音の構造】:扱う「音・言葉」の基礎知識
- 【信号処理】:アナログからデジタル、そして周波数へ(前処理)
- 【特徴量】:AIが学習しやすい形へ加工
- 【モデル】:AIアルゴリズムによる学習・推論
1. タスク(目的・全体像)
まず、音声処理で何を実現したいのかを分類します。

| 用語 | 解説 |
|---|---|
| 音声処理 | 音声に関わる技術の総称。 |
| 音声認識 | 音声をテキスト(文字)に変換するタスク。(例:自動文字起こし) |
| 音声合成 | テキストから音声を生成するタスク(TTS)。(例:カーナビの案内) |
| 話者識別 | 声の主が誰であるかを特定するタスク。(例:声による生体認証) |
2. 音の構造(言語・音響の基礎)
人間が発する言葉や音の最小単位についての定義です。
-
音素 (Phoneme)
- 物理的な音の最小単位。(例:「あ」の音、英語の「L」と「R」の違い)
-
音韻 (Phonology)
- 意味を区別する、脳内で認識される抽象的な最小単位。
- 日本語の「ん」は後ろに続く言葉で発音が変わる(音素が違う)が、意味としては同じ(音韻)。
3. 信号処理(前処理・変換)
マイクで拾ったアナログの音を、コンピュータが扱える形に変換する段階です。
-
A-D 変換 (ADC)
- 連続的な「アナログ信号」を、離散的な「デジタル信号」へ変換する処理。
-
パルス符号変調器 (PCM)
- A-D変換の代表的代表的な方式。標本化、量子化、符号化の手順でデジタル化する。
-
高速フーリエ変換 (FFT)
- 時間とともに変化する「波形データ」を、どの高さの音がどれくらい含まれるかという「周波数データ」に高速に変換するアルゴリズム。
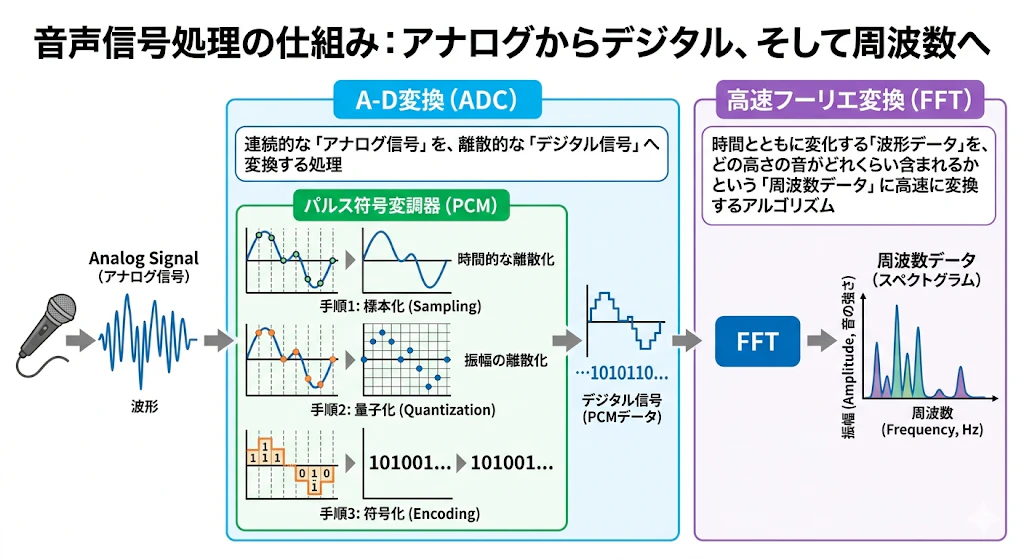
※画像は処理の全体像を理解するためのイメージです。厳密な波形や専門的な回路図を示すものではありません。
4. 特徴量(モデルに入れるデータ表現)
FFTで得たデータを、さらに人間の聞こえ方や声の特徴に特化した数値へ変換します。
-
スペクトル包絡
- 周波数データの細かいギザギザを繋いだ大まかな輪郭。ここに「声の音色」や「母音」の情報が含まれる。
-
フォルマント(フォルマント周波数)
- スペクトル包絡にある「山の盛り上がり」のこと。低い方から第1フォルマント(F1)...と呼び、その組み合わせで「あいうえお」を判別できる。
-
メル尺度
- 人間の聴覚(低い音には敏感、高い音には鈍感)に合わせた周波数のモノサシ。
-
メル周波数ケプストラム係数 (MFCC)
- メル尺度を利用して抽出される、音声認識における最も代表的な特徴量。

5. モデル(学習アルゴリズム)
抽出された特徴量を用いて、最終的な予測や生成を行う心臓部です。

-
隠れマルコフモデル (HMM)
- 時系列データを確率的に扱うモデル。ディープラーニング以前の音声認識の主流。
-
WaveNet
- CNN(畳み込みニューラルネットワーク)を用いた音声生成モデル。
- 非常に高品質で自然な音声合成を実現した(Google DeepMind開発)。
まとめ
音声処理の用語は、以下の流れで繋がっています。

アナログの音(PCM)
↓ FFTで変換
周波数データ
↓ 特徴抽出
MFCC(メル尺度を利用)
↓ モデル学習
HMMやWaveNet
↓
音声認識・音声合成の実現!
この流れを押さえておくことで、「どのフェーズの技術か」を混同せずに済むのではと思います。