はじめに
本記事では、機械学習の「分類問題」において重要な、「ロジスティック回帰」と「サポートベクターマシン(SVM)」 について解説します。
難しい数式は極力控え、「データの中で何が起きているのか?」を直感的にイメージできる図解も使ってまとめてみました。
1. ロジスティック回帰 (Logistic Regression)
名前に「回帰」とついていますが、実は 「分類」(特に「合格か不合格か」などの 二値分類)を得意とするアルゴリズムです。結果を「0か1か」の極端な値ではなく、「〇〇%の確率でこちらに属する」という 確率(0〜1の連続値) で出力するのが最大の特徴です。
特徴と仕組み
- シグモイド関数がカギ: 入力されたデータを、0から1の間の滑らかなS字カーブを描く 「シグモイド関数」 に通すことで、確率として表現します。
- 0.5で白黒つける: 「0.5(50%)以上ならクラス1(合格)、未満ならクラス0(不合格)」のように、あらかじめ決めた閾値(しきいち)を使って分類します。
- 活用シーン: 「あるユーザーが商品を購入する確率」や「スパムメールである確率」の算出など、単に分けるだけでなく「確率そのもの」を知りたいビジネスシーンで非常に重宝されます。
直感イメージ図:ロジスティック回帰
以下の図は、横軸に特徴量(例:勉強時間)、縦軸に確率(0〜1)をとったグラフです。
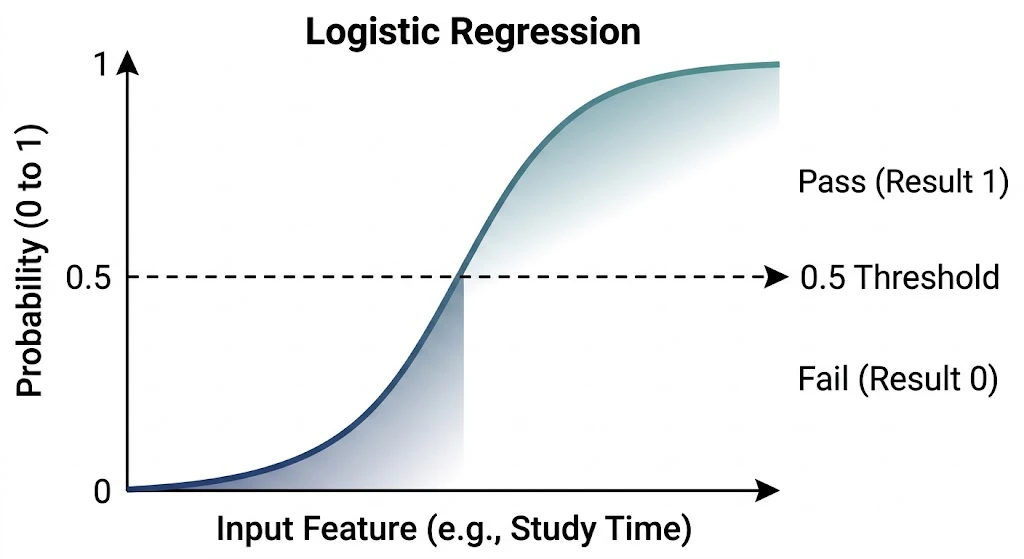
図の説明:
青い曲線がシグモイド関数によって描かれたモデルです。入力(勉強時間)が増えるにつれて、合格確率が0から1へ滑らかに変化しています。
0.5(50%)の位置にある破線が境界線となり、ここを基準に「合格/不合格」の判定が行われます。
2. サポートベクターマシン (SVM)
データを分類するための「最も安全で太い境界線」を引く、職人のようなアルゴリズムです。異なるグループのデータの間に、できるだけ広い「道(マージン)」を通すように境界線を引きます。
特徴と仕組み
- マージン最大化: データ群と境界線の間の隙間(マージン)が最大になるような線を計算で見つけ出します。これにより、未知の新しいデータに対しても正しく分類できる能力(汎化性能)が高まります。
- サポートベクター: 境界線を決める際に基準となる、境界のギリギリにいるデータ点のことです。マージンを決めるのはこの一部のデータ(サポートベクター)のみであるため、計算効率が良いという利点があります。
直感イメージ図1:マージン最大化
以下の図は、2次元のグラフ上で2つのグループを分ける様子です。
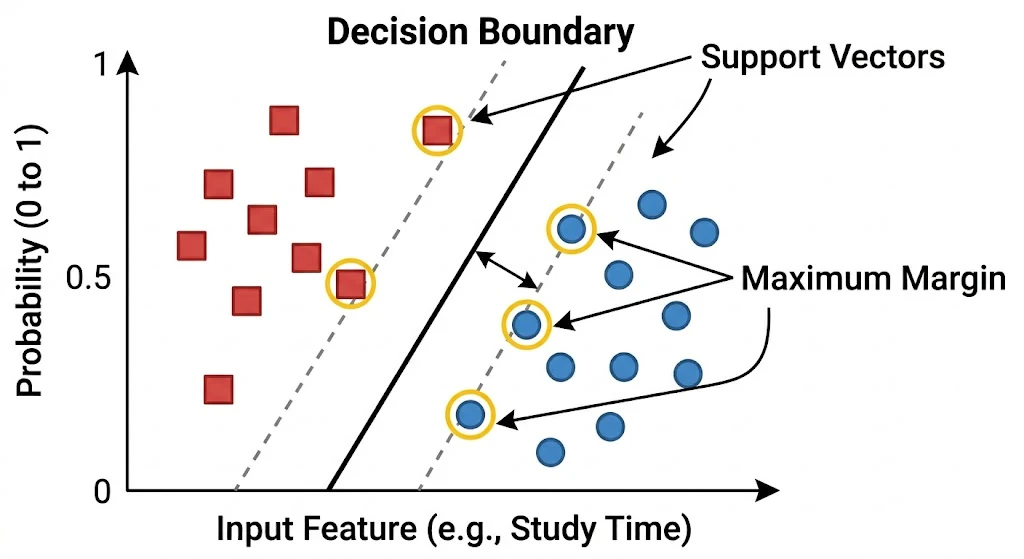
図の説明:
赤い四角と青い丸のグループを、真ん中の黒い実線(決定境界)で分けています。実線の両脇にあるグレーの破線までの隙間が「マージン」であり、これが最大になるように線が引かれています。破線に触れている黄色の丸で囲まれたデータがサポートベクター です。
「カーネルトリック」と非線形分離
SVMの最大の強みは、直線では分けられない複雑なデータ配置(非線形分離問題)であっても対応できることです。データを疑似的に「高次元空間」に飛ばすことで、スパッと平面で切り分けることができる魔法のような手法 「カーネルトリック」 を使用します。
直感イメージ図2:カーネルトリック
以下の図は、カーネルトリックのビフォーアフターです。
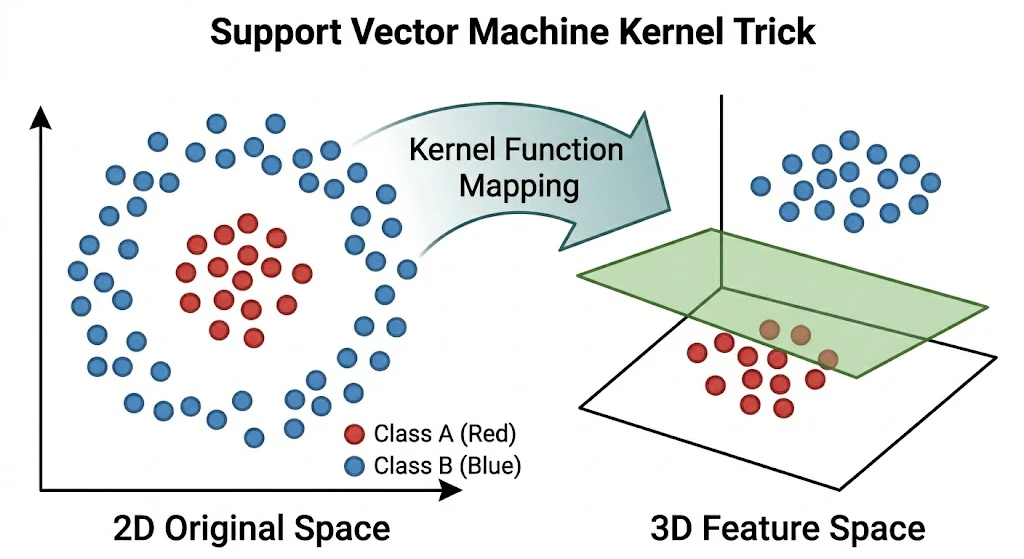
図の説明:
- 左図(2D): 内側に赤い丸、外側に青い丸があり、直線では絶対に分けられません。
- 右図(3D): 「カーネル関数」を使ってデータを3次元空間に持ち上げました。すると、赤い丸と青い丸の間に 1枚の平らな板(緑色の平面) を差し込むことで、綺麗に分類できるようになります。
3. ロジスティック回帰とSVMの比較まとめ
最後に、比較表をまとめました。
| 項目 | ロジスティック回帰 (Logistic Regression) | サポートベクターマシン (SVM) |
|---|---|---|
| 分類のアプローチ | 確率を計算して閾値(例:0.5)で分ける | 境界線とデータの隙間を最大化して分ける |
| 出力形式 | 0〜1の連続値(確率) | クラス(AかBか) |
| 複雑なデータへの対応 | 基本的には直線的な分離(線形分離) | カーネルトリックで複雑な境界も引ける(非線形分離) |
| G検定 頻出キーワード | ・分類問題 ・シグモイド関数 ・二値分類 |
・マージン最大化 ・サポートベクター ・カーネルトリック ・非線形分離 |
| 実務での選び方 | 「なぜその結果になったか」の解釈性や、確率そのものが欲しいとき | とにかく高い精度で、複雑な分類を行いたいとき |
おわりに
今回は機械学習の代表的な分類アルゴリズムである「ロジスティック回帰」と「SVM」について、直感的な図解を交えて解説しました。数式を見ると難しく感じますが、裏側でやっているイメージが掴めると、途端に親しみやすくなるなと思いました。
学習に利用している書籍
公式教科書ということでとりあえず購入しました。読んでみて、わかりやすいとは程遠いなというのが正直な感想です。
とはいえ、ここに記載されているのが基本になると思うので、それを知るために一読は良いと思います。
各セクションごとに問題が用意されていて、最後に模擬試験的な形式での問題が用意されています。
解説もわかりやすいですし、これを繰り返し行って学習しようと思います。