やったこと
AWSの勉強がてら、「QiitaマイページからLGTM / View / ストック数の一覧を確認できるようにしてみた」で作ったpythonファイルをAWS Lambdaから定期実行できるようにしてみました。
(過去記事ではHerokuで定期実行させていました)
ちょうど同じ時期にAWS Lambdaでpythonプログラムの定期実行という記事が上がっていたので、全体の流れはこちらを参考にさせていただきました。
ところどころ追加で調べた箇所があるので、この記事はそちらをメインにした内容になります。
また例によって、AWSアカウントは作成済みとします。
ちなみに料金の方は
AWS Lambda の無料利用枠には、1 か月ごとに 100 万件の無料リクエスト、および 40 万 GB-秒のコンピューティング時間が、それぞれ含まれます。
とあるので今回のように1日1回程度のリクエストであれば問題ないだろうと一安心。
(今のところ基本無料でやりたいので、一応8$を超えたらアラートが飛ぶようにしています)
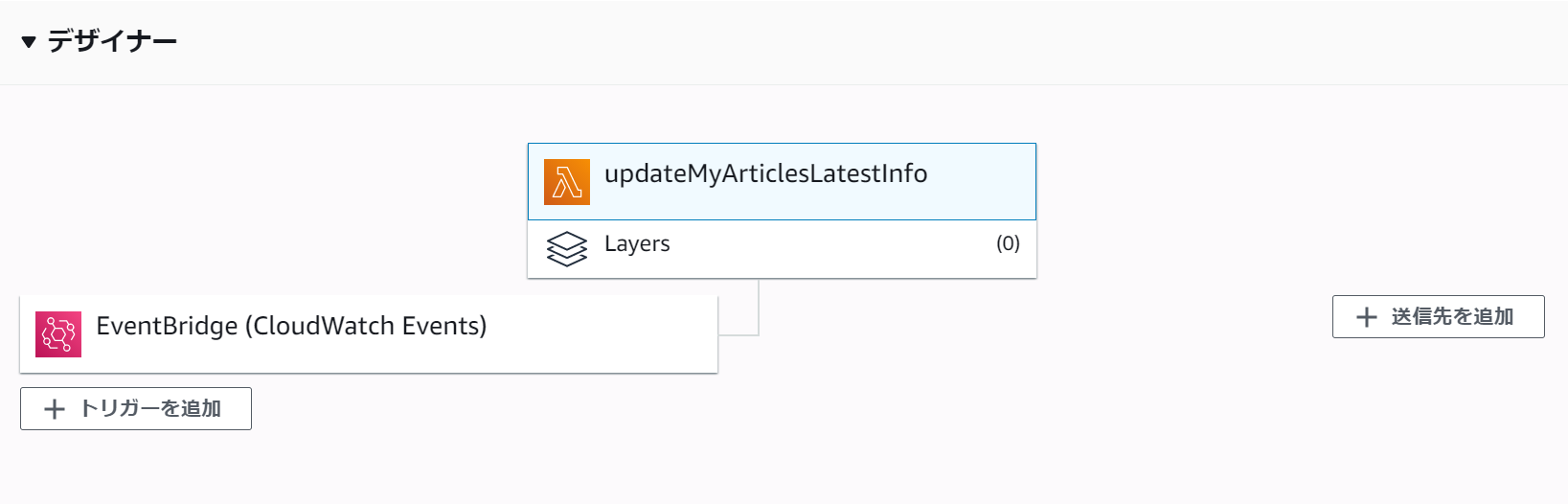
作成したLambda関数の内容
- ランタイム:python 3.8
- トリガー:毎朝7時に実行
- 外部モジュール(pytz, requests)を使用
- タイムアウト時間:30秒
- その他:初期値のまま
ソースコード
おおむね同じですが、前回と比較して以下を変更しています。
- Qiitaのアクセストークンや記事IDをべた書き⇒環境変数から読み込む
-
if __name__ == "__main__":
⇒def lambda_handler(event, context):
※lambda_handler:Lambda関数から最初に呼ばれる関数名
ソースコード
import os
import http.client
import json
import requests
import datetime
import pytz
TOKEN = os.environ['TOKEN'] # Read&Write用
HEADERS = {'content-type': 'application/json',
'Authorization': 'Bearer ' + TOKEN}
URL_BASE = 'https://qiita.com/api/v2'
ARTICLE_ID = os.environ['ARTICLE_ID']
# 記事一覧のLGTM, View, ストック数を取得する
def get_info():
url_authenticate = URL_BASE + '/authenticated_user/items'
# 記事一覧を取得
res = requests.get(url_authenticate, headers=HEADERS)
list = res.json()
# 不要な記事を除外
list_item = []
for item in list:
# 限定記事は対象外
if item['private']:
continue
# 投稿先の記事は対象外
if item['id'] == ARTICLE_ID:
continue
list_item.append(item)
num = 0
list_iteminfo = [[0 for i in range(5)] for j in range(len(list_item))]
for item in list_item:
# 各種項目を取得
id = item['id']
title = item['title']
url = item['url']
likes_count = item['likes_count']
# 記事の情報を取得
url_item = URL_BASE + '/items/' + id
res = requests.get(url_item, headers=HEADERS)
json = res.json()
# タイトル別のview数のセット
page_views_count = json['page_views_count']
i = 1
# stock数の取得(最大1000件)
while i < 10:
url_stock = url_item + '/stockers?page=' + str(i) + '&per_page=100'
res_stock = requests.get(url_stock, headers=HEADERS)
json_stock = res_stock.json()
stock_num = len(json_stock)
if stock_num != 100:
stock_count = (i * 100) - 100 + stock_num
break
else:
i += 1
list_iteminfo[num] = [title, url, likes_count, page_views_count, stock_num]
num += 1
return list_iteminfo
# 記事を更新する
def update_article(list_iteminfo):
item = {
'body': '',
'coediting': False,
'private': False,
'tags': [{'name': 'qiita'}],
'title': '投稿記事のLGTM, View, ストック数一覧'
}
# 本文の作成([記事タイトル](URL), LGTM数, View数, ストック数)
now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
setdate = now.strftime('%Y/%m/%d %H:%M:%S')
body = 'この記事は [' + setdate + '] に更新されました。\r\n'
for info in list_iteminfo:
body += '\r\n[' + str(info[0]) + '](' + str(info[1]) + ')'
body += '\r\nLGTM:' + str(info[2]) + '件, View:' + str(info[3]) + '件, ストック:' + str(info[4]) + '件\r\n'
item["body"] += body
url = URL_BASE + '/items/' + ARTICLE_ID
# 記事の更新
res = requests.patch(url, headers=HEADERS, json=item)
return res
def lambda_handler(event, context):
list_iteminfo = get_info()
res = update_article(list_iteminfo)
print(res)
追加で調べたこと
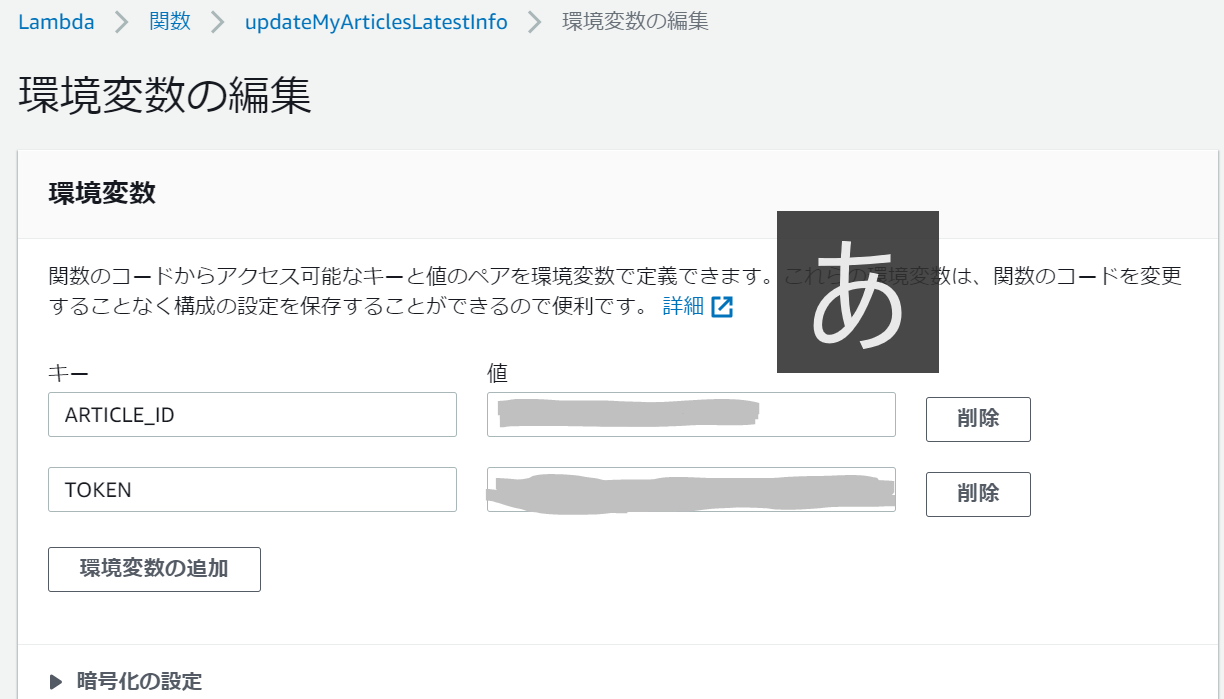
環境変数の設定
Qiitaのアクセストークンなどを環境変数に設定したかったのですが、コードやデザイナと同じページの「環境変数」欄の編集ボタンから簡単に編集ページへ遷移できました。
外部モジュールの配置方法
初めは単純に実行対象となるlambda_function.pyのみを配置しましたが、
"errorMessage": "Unable to import module 'lambda_function': No module named 'requests'"
とエラーになってしまいました。どうやら外部モジュールがある場合、自分で読み込ませる必要がある様子。
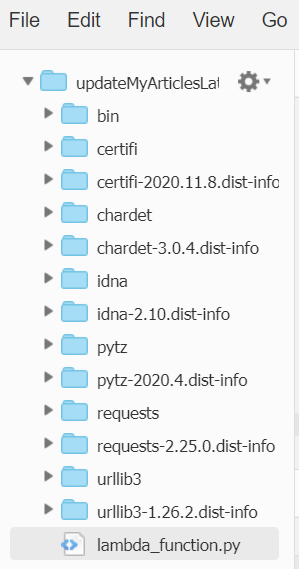
こちらを参考に、ローカル環境でlambda_function.pyと同階層に対象のモジュール(pytz, requests)をpipでインストールし、zip化してアップロードしました。
アップロード後は下記のようにモジュールが展開されました。
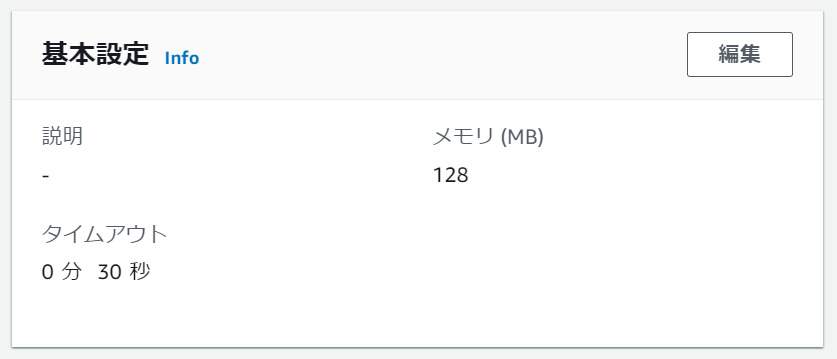
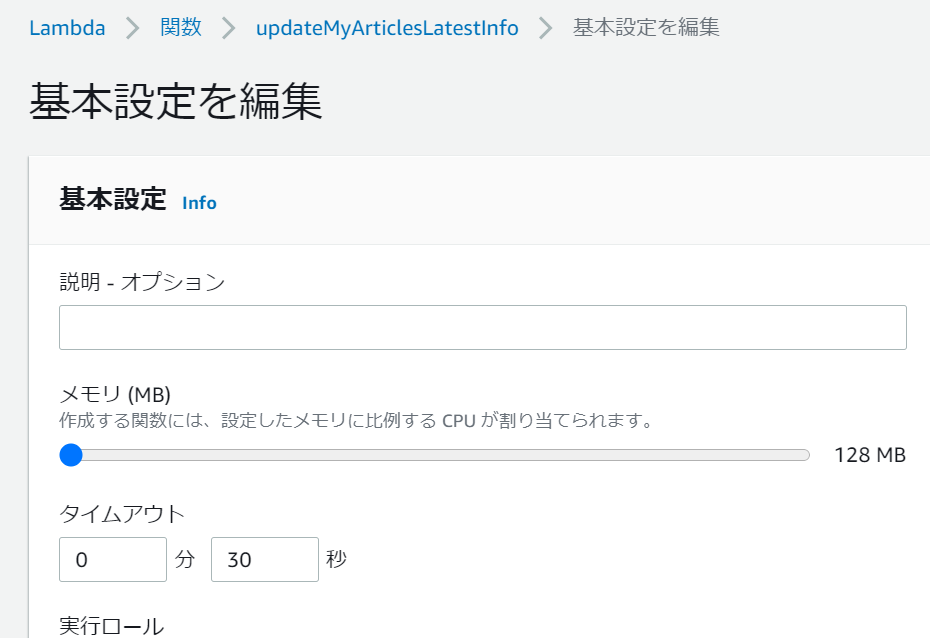
タイムアウト時間の変更
外部モジュールも無事読み込め、これで実行成功!と思いきや、今度は
Task timed out after 3.00 seconds
というエラーが発生しました。
初期設定だと実行時間が3秒を超えるとタイムアウトしてしまうので、こちらの設定を変更します。
環境変数の設定同様、今度は「基本設定」欄の編集ボタンから編集ページへ遷移し、設定値を30秒に変更しました。
最後に
Lambda、思ってたより簡単。
次はサーバー立てたり、いろいろ試したくなりました。
参考
AWS Lambdaでpythonプログラムの定期実行
AWS Lambda 環境変数の使用
AWS_Cron式のワイルドカード
AWS Lambdaで「No module named 'pytz'」エラーが発生したときの対処方法
【AWS】Lambdaでtime out after 3.00 secondsが出たときの対処法