作ったもの
下記のように、Qiita APIから特定の記事に対して**[LGTM/View/ストック数]の取得・更新**を行えるようにしました。
ピックアック記事にすることでマイページからすぐに確認できます。
まだ手動で実行しているだけですが、今後そこも自動化すればいつでも最新の情報がQiita上ですぐ確認できていい感じです。
マイページトップ画面
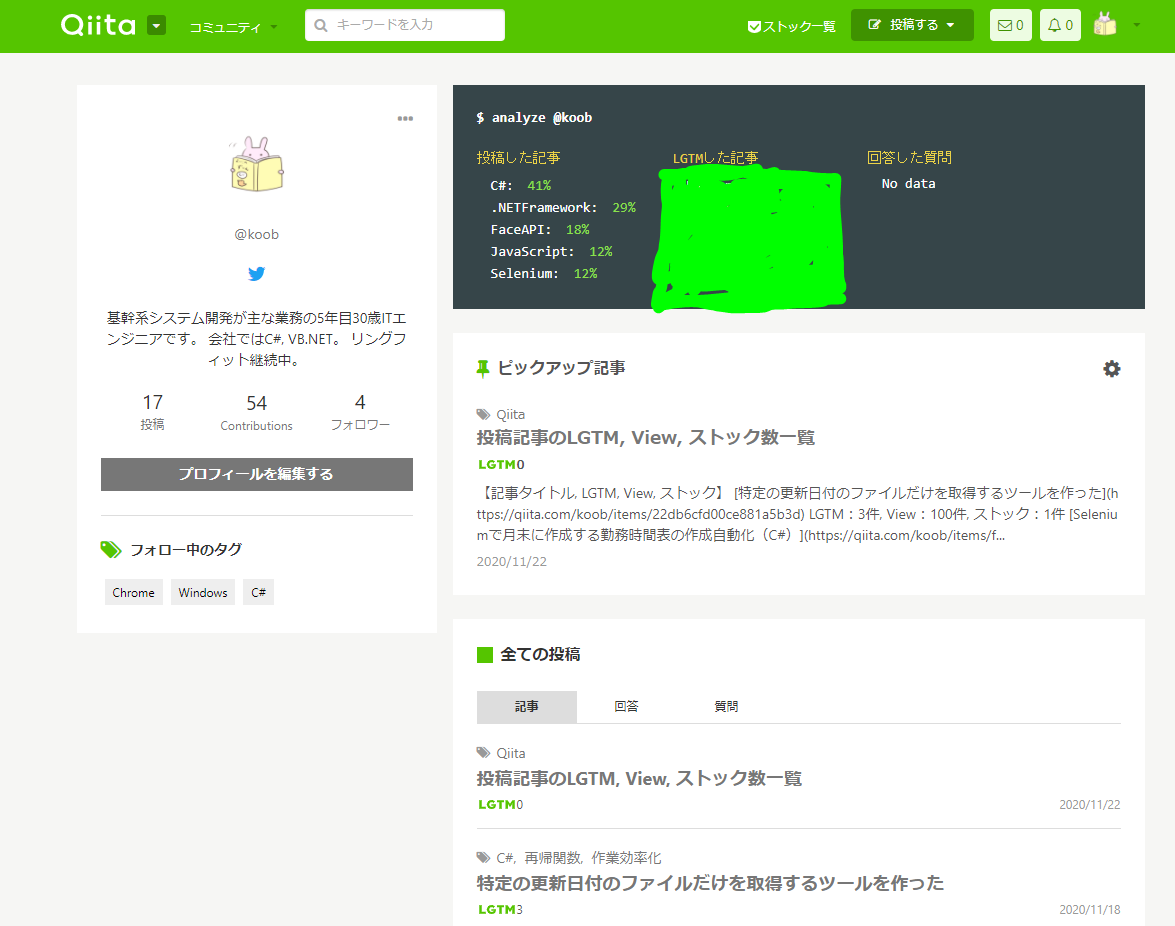
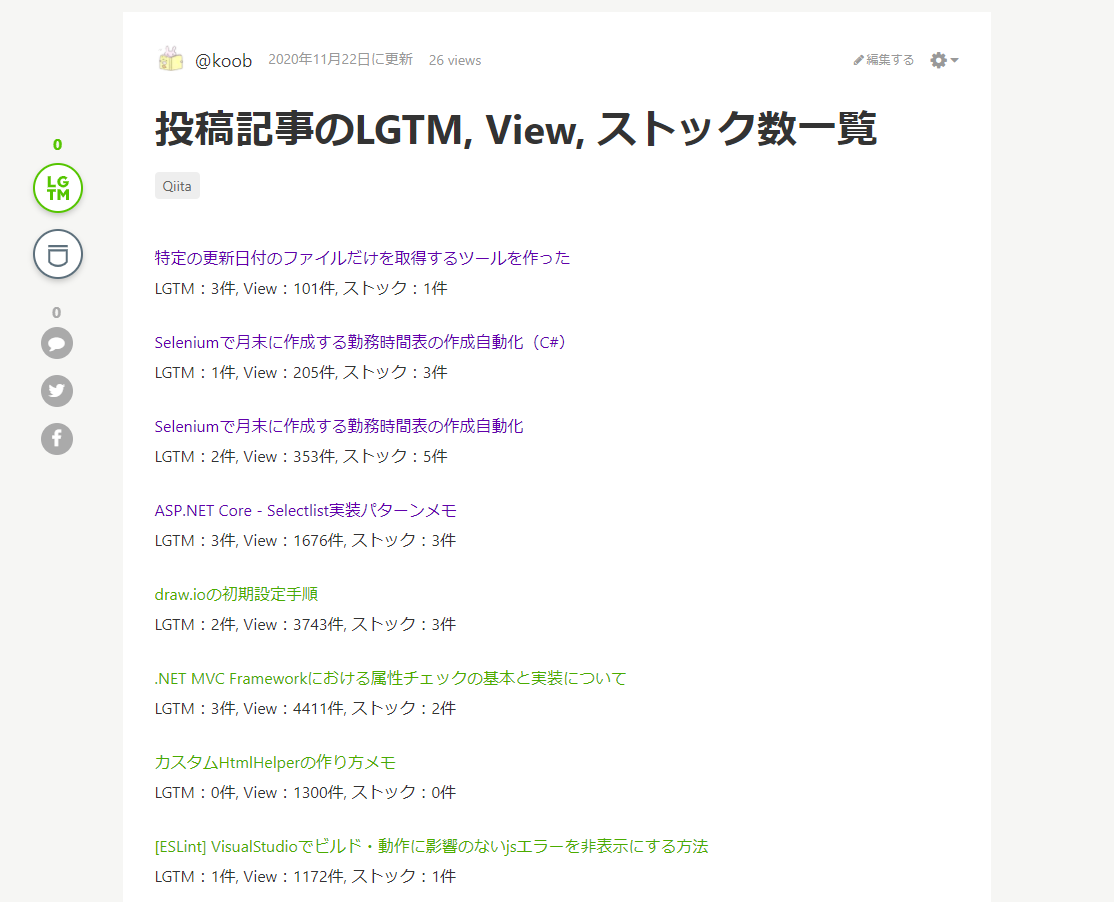
記事の内容(こちらから直接実際の記事に飛べます)
環境
Google Colaboratory から実行しています。
Qiita APIのアクセストークン(必須)は[read_qiita]、[write_qiita]を選択して発行しています。
※Google ColaboratoryやQiita APIの使い方、アクセストークンの発行の仕方は省きます。
また、今回更新対象とする記事は事前に新規投稿済みとします。
その記事の記事IDも別途Qiita APIから取得しているものとします。
ソースコード
ソースコード
Qiitaから記事情報を取得・更新する.ipynb
import http.client
import json
import requests
TOKEN = {発行したアクセストークン} # Read&Write用
HEADERS = {'content-type': 'application/json',
'Authorization': 'Bearer ' + TOKEN}
URL_BASE = 'https://qiita.com/api/v2'
ARTICLE_ID = {更新対象となる記事のID} # こちらも事前にQiita APIで取得して確認しておいてください
# 記事一覧のLGTM, View, ストック数を取得する
def get_info():
url_authenticate = URL_BASE + '/authenticated_user/items'
# 記事一覧を取得
res = requests.get(url_authenticate, headers=HEADERS)
list = res.json()
# 不要な記事を除外
list_item = []
for item in list:
# 限定記事は対象外
if item['private']:
continue
# 投稿先の記事は対象外
if item['id'] == ARTICLE_ID:
continue
list_item.append(item)
num = 0
list_iteminfo = [[0 for i in range(5)] for j in range(len(list_item))]
for item in list_item:
# 各種項目を取得
id = item['id']
title = item['title']
url = item['url']
likes_count = item['likes_count']
# 記事の情報を取得
url_item = URL_BASE + '/items/' + id
res = requests.get(url_item, headers=HEADERS)
json = res.json()
# 記事別のview数のセット
page_views_count = json['page_views_count']
i = 1
# ストック数の取得(最大1000件)
while i < 10:
url_stock = url_item + '/stockers?page=' + str(i) + '&per_page=100'
res_stock = requests.get(url_stock, headers=HEADERS)
json_stock = res_stock.json()
stock_num = len(json_stock)
if stock_num != 100:
stock_count = (i * 100) - 100 + stock_num
break
else:
i += 1
list_iteminfo[num] = [title, url, likes_count, page_views_count, stock_num]
num += 1
return list_iteminfo
# 記事を更新する
def update_article(list_iteminfo):
item = {
'body': '',
'coediting': False,
'private': False,
'tags': [{'name': 'qiita'}],
'title': '投稿記事のLGTM, View, ストック数一覧'
}
# 本文の作成([記事タイトル](URL), LGTM数, View数, ストック数)
now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
setdate = now.strftime('%Y/%m/%d %H:%M:%S')
body = 'この記事は [' + setdate + '] に更新されました。\r\n'
for info in list_iteminfo:
body += '\r\n[' + str(info[0]) + '](' + str(info[1]) + ')'
body += '\r\nLGTM:' + str(info[2]) + '件, View:' + str(info[3]) + '件, ストック:' + str(info[4]) + '件\r\n'
item["body"] += body
url = URL_BASE + '/items/' + ARTICLE_ID
# 記事の更新
res = requests.patch(url, headers=HEADERS, json=item)
return res
if __name__ == "__main__":
list_iteminfo = get_info()
res = update_article(list_iteminfo)
print(res)
(2020/11/22 21:27追記)
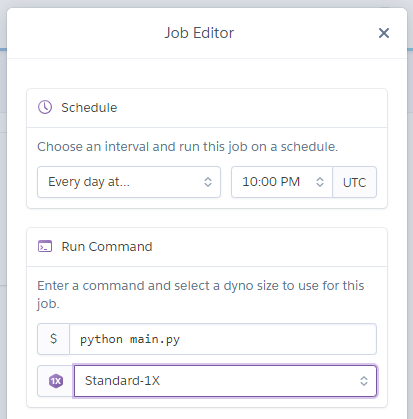
自動実行の件は、結局herokuにpyファイルを置いて[heroku scheduler]なるもので定期実行させることにしました。
UTCで毎日PM10:00、つまり日本時間で約AM7:00に自動で実行されます。
参考
Qiita API公式
【Qiita API】いろんな方法で Views、Likes、Stocksを取得(JavaScript、Google Script、Python, Vue.js)
Herokuでお天気Pythonの定期実行