こんにちは。
レアゾン・ホールディングスでエンジニアをしている畑山です。
突然ですが、皆様、ゲームをプレイしてますでしょうか?
私はSteamライブラリに眠る積みゲーから目を逸らしながらこの記事を書いています。
そんな私ですが、新しいゲームを探す手を止めることはできません。
大きなタイトルであればニュースサイトを追っていれば情報収集できますが、個人開発のインディーゲームまで考えると、毎日のように発売されるタイトル全てに目を通すのは困難です。
そこで、この課題を、AI(LLM)を使って解決してみようと思います。
前提
この記事は、以下のような読者を対象としています。
- AI(LLM) を組み込んだ実践的なアプリケーション開発に興味がある方
- 低コスト で AI アプリケーションのプロトタイプを作成したい方
- LLM やテキストマイニング、ベクトル検索の基本的な概念に馴染みがある方
- ゲームが好きな方(!)
各サービスの料金体系や制約は執筆時点の情報に基づきます。
つくったもの
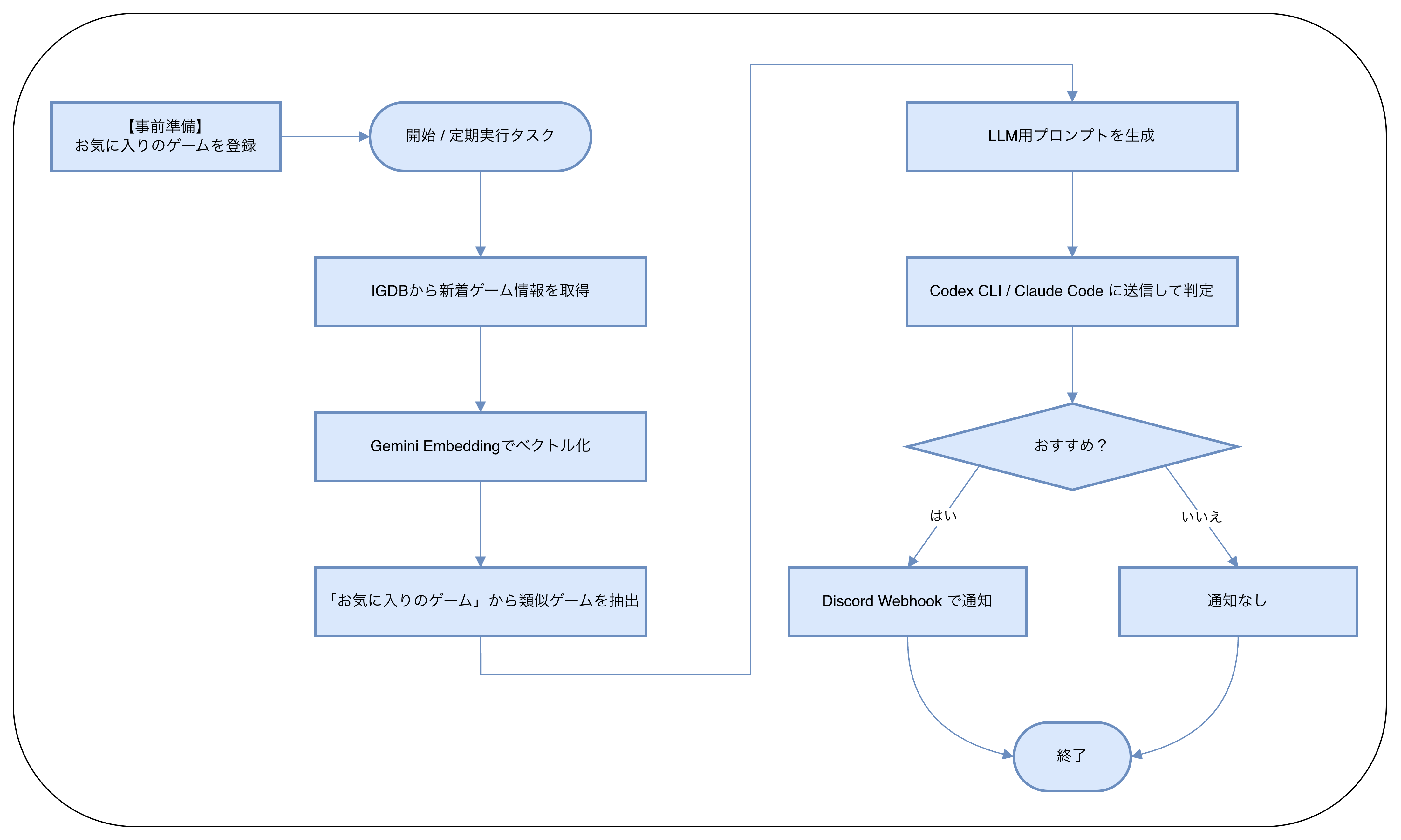
以下のような流れで、おすすめのゲームを判定するシステムを作成しました。
- IGDBから新着のゲーム情報を取得
- AIを用いて自身が過去にプレイしたお気に入りゲームの傾向と新着ゲームを比較・分析
- おすすめかどうかを判定しDiscordに通知
処理フローの全体像
事前準備
おすすめのゲームを判定するにあたり、まずは自分の好きなゲームを登録しておく必要があります。
後述する処理フローと同様の流れで自分の好きなゲームをIGDB APIから取得し、SQLiteで構築したデータベースに記録しておきます。
ここは変に自動化せず、情報を取得してDBに格納する処理だけ作って1件ずつ手動で登録しました。
IGDB APIでゲーム情報を取得
ゲーム情報の取得には、Twitch(Amazon)が運営するゲームデータベース IGDB(Internet Game Database) が提供しているAPIを使用します。
IGDBは、プラットフォームを横断したゲーム情報を集約するデータベースで、ジャンル、プラットフォーム、発売日、カバー画像、開発会社など、多様な属性情報を提供しています。
開発者向けには公式APIが公開されており、商用を含む幅広い用途で利用可能です。
海外のデータベースなのでほとんどの情報が英語になっています。
また、ユーザー投稿型のため間違いが含まれている可能性があります。
非商用の範囲では無料で使用することができます。
ありがたいです。
APIの利用には、Twitch アカウントで Twitch Developers コンソール へサインインして、クライアントIDとシークレットの発行が必要です。
今回は Python 向けの公式ラッパーライブラリ igdb-api-v4 を利用しました。
今回は以下の流れでゲーム情報を取得しています。
- release_dates API で発売日で絞り込んだゲーム情報を取得
ここでゲームのIDを取得します - game API で、1で取得したゲームの詳細を取得
ここでゲームのタイトル、概要、ストーリーの概要、ジャンル/テーマ/キーワードといったゲームについているタグを取得します - genre API/theme API/keyword API で、2で取得したタグの表示名を取得
Gemini API で概要テキストを埋め込みベクトルに変換
ゲームの類似度を判定するため、ゲームの概要テキストを埋め込みベクトルに変換します。
埋め込みベクトルに変換することで、テキストの長さによらず、意味的に近いものを検索することができます。
埋め込みベクトル変換には Gemini API を使用します。
Gemini を採用した理由は、 Gemini API には大きな無料枠が設定されており、今回の個人での利用範囲では無料枠で実現できるためです。
ありがたいです。
Gemini API を使用するには、 Google AI Studio で API key を取得する必要があります。
今回は Python 向けの公式ライブラリ google-generativeai を利用しました。
今回は IGDB API から取得したゲーム情報のうち以下をベクトル化します。
- ゲームタイトル
- ゲームの要約
- ゲームのストーリーライン
Gemini APIの無料枠では、リクエストの内容がモデルの改善に利用される可能性があるため注意して下さい。
取得した情報を元にお気に入りの類似ゲームを検索
こちらが、今回のシステムのコア部分その1になります。
IGDB API から取得したゲーム情報を元に、事前に登録した自身の好みのゲームの中から以下の複数観点で類似のゲームを数本ずつ取得してきます。
タグ類似
ゲームに付いているタグ情報は多岐にわたります。ゲームジャンルから、どのようなテーマか、ゲームに紐づけられたキーワードなど。
これらの情報を集合として扱い、ダイス係数により類似度を算出します。
ダイス係数は以下の式で定義され、2つの集合の共通要素が占める割合を表しています。
$$
\mathrm{Dice}(A, B) = \frac{2|A \cap B|}{|A| + |B|}
$$
いくつかゲームを確認したところ、ゲームによって大量にタグが付いていたり数件しかついていなかったりとまちまちだったため、要素数の影響を平均的に打ち消せるダイス係数を採用しました。
また、本来はジャンル(シューティングとかアドベンチャーとか)の一致にはバイアスをかけたほうが精度が出ると思われますが、今回はこれだけでもそこそこの精度が出ることが確認できたので、類似度の計算にタグの種類は使用していません。
タグは、おすすめのゲームのジャンルや傾向を判断する根拠になると思って採用しました。
タイトル類似
埋め込みベクトル化したゲームのタイトルからコサイン類似度により類似度を算出します。
コサイン類似度は以下の式で定義され、2つのベクトルがどれくらい同じ方向を向いているかを判定できます。
$$
\mathrm{cos}(\boldsymbol{a},\ \boldsymbol{b}) = \frac{\boldsymbol{a} \cdot \boldsymbol{b}}{ \lVert\boldsymbol{a}\rVert \lVert\boldsymbol{b}\rVert }
$$
ここで、$\boldsymbol{a} \cdot \boldsymbol{b}$ はベクトルの内積、$\lVert\boldsymbol{a}\rVert$ はベクトル $\boldsymbol{a}$ のノルム(長さ)を表します。
テキストの埋め込みベクトルでこの計算を行うと、テキストの意味の近さが判定できます。
ゲームのタイトルは、同一シリーズを好んでプレイしている場合などに判断の根拠になると思って採用しました。
ストーリー類似
埋め込みベクトル化したゲームのストーリーから、上記と同様にコサイン類似度により類似度を算出します。
ストーリーは、好みの物語の傾向の判断する根拠になると思って採用しました。
概要類似
埋め込みベクトル化したゲームの概要から、上記と同様にコサイン類似度により類似度を算出します。
情報としては過剰かとも思いましたが、APIから取得できたので採用しました。
実際、有名タイトル以外はストーリーと同一テキストが入っているものが多かったので、どちらかで良かったかもしれません。
LLMに渡すプロンプトを生成
取得した類似ゲームを元に、以下のようなLLMに渡すためのプロンプトを生成します。
プロンプト(長いので折りたたんでいます)
実際のゲームの内容は伏せています。
目的: 新着ゲームがユーザーの好みに合うかを、複合的な類似指標に基づいて判定する。
注意事項:
- タグ/ゲームシステムの一致度を最優先し、タイトル・ストーリー類似は補助指標として扱う。
- 類似度スコア0.6以上はプラス寄り、0.6未満はマイナス寄りとして評価し、複数指標の総合判断を示す。
- ただし、タグ類似度はダイス係数で計算されているため、タグの数が極端に異なる場合は低くなる。タグ類似度が0.6より僅かに低い程度の場合は実際のタグの内容を比較する。
- タイトル類似で同シリーズ作品が上位に来た場合は、タグ整合性を確認したうえで推薦可能性を検討する。
- 出力は簡潔なJSONのみとし、定義済み出力形式以外のテキストは返さない。
出力形式: {"recommend": <bool>, "reason": "<string>"}
判定対象ゲーム:
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似結果: タグ類似 上位3件
類似度スコア: 0.667
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似度スコア: 0.571
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似度スコア: 0.375
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似結果: タイトル埋め込み 上位3件
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似度スコア: 0.626
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似度スコア: 0.610
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似結果: ストーリー埋め込み 上位3件
類似度スコア: 0.714
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似度スコア: 0.686
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似度スコア: 0.684
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似結果: サマリー埋め込み 上位3件
類似度スコア: 0.712
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似度スコア: 0.681
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
類似度スコア: 0.674
タイトル: <ゲームタイトル>
ストーリー: <ストーリー>
サマリー: <概要>
タグ: <タグ一覧>
このように判定基準をプロンプトとしてLLMに判定させることで、判定基準を自然言語で記述し、より柔軟に判定ができるようになります。
場合によっては特定のジャンルが好き/嫌いなどの情報を含めることで、よりパーソナライズした判定を行うことができそうです。
コーディングエージェントを用いておすすめのゲームを判定
こちらが、今回のシステムのコア部分その2になります。
一昔前であれば、ここからOpenAIなりのAPIを叩いて判定することになりますが、今回はみんな大好きコーディングエージェントを使用することにしました。
Codex CLIやClaude Codeは、コマンドラインから非対話モードでアクセスすることができます。
これにより、コーディングエージェントをプログラムやCIパイプラインに組み込むことができます。
Codex CLI:
codex exec <prompt>
Claude Code:
claude -p <prompt>
各社のサブスクリプションに入っていれば普段使用しているサブスクリプションの範囲内で使用できます。(もちろんレートリミットなどはあるので使いすぎには注意です)
ありがたいです。
今回はこれをPythonから直接呼び出すことにします。
import subprocess
result = subprocess.run(
["codex", "exec", prompt],
text=True,
capture_output=True,
)
print("エージェントの回答:", result.stdout)
ちなみに、CodexはTypeScript、Claude CodeはTypeScriptとPython向けのSDKも提供されています。
今回はシンプルな処理しか行わないのでこれらは使用していません。
また、プロンプトで出力をJSONに限定していますが、Claude CodeはJSON以外のテキストも出力することが多くあったため注意が必要そうです。(Thinkingのテキストも一緒に出ている可能性があります)
今回は、エージェントの出力からJSONオブジェクトっぽい箇所を抽出するようにして対処しました。
LLM を判定に用いているため、同じゲーム・同じプロンプトであっても、実行のたびに判定結果に多少の揺らぎが出る場合があります。
今回は結果を最終的に人間が確認するため許容していますが、正確性が求められる場面では慎重に判断する必要があります。
おすすめのゲームをDiscordへ通知
コーディングエージェントから出力されたJSONオブジェクトは以下の形式になっています。
{"recommend": <bool>, "reason": "<string>"}
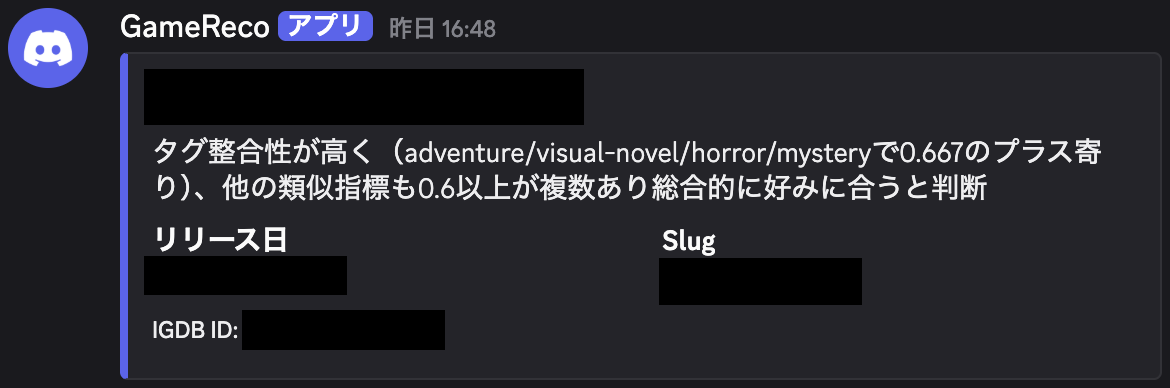
ここで、recommend: trueのもののみDiscordに通知します。
Discordの通知には単純にWebhook URLで行います。
実際に送信されたものは以下のような形です。(実際のゲームの内容は伏せています)
IGDB APIからはIGDBへのリンクや画像なども取得可能ですが、今回は記事向けに最小限の内容のみ通知しています。
やってみての気づき
実際に作って動かしてみて、特に印象に残ったポイントは次のとおりです。
- コーディングエージェントをプログラムから呼び出すことで、テキスト処理の幅が広がる
- 機械的な類似判定とLLMによる汎用的な判断を組み合わせることで、低コストでAIによるおすすめゲームの判定処理を実現できる
- 昨今のLLMの性能向上により、ある程度雑なプロンプトでも比較的高精度で意図に沿った回答が得られる
- 日本語以外のデータソースでも、LLMを用いると言語を問わない判定処理が実現できる
おわりに
今回の記事では、実践的な内容でLLMを使用したシステム構築を紹介しました。
数日運用してみたところ、面白そうなゲームがきちんとおすすめされている感じがします。
購入までは至らずとも、「確かにこういうの好きだな」と思うような作品が多く、これまでチェックしていなかった新しいゲームに出会うきっかけにもなりそうです。
私のお気に入り傾向では1日1〜2件程度のおすすめ頻度であり、1日1回サッと確認するのにちょうど良い頻度でした。
この内容が、コーディングエージェントのコーディング以外への活用や、低コストでAIアプリのプロトタイプを作成したい方への参考になれば幸いです。
リポジトリ
本記事で紹介したシステムの実装はこちらにて公開しています。
▼新卒エンジニア研修のご紹介
レアゾン・ホールディングスでは、2025年新卒エンジニア研修にて「個のスキル」と「チーム開発力」の両立を重視した育成に取り組んでいます。 実際の研修の様子や、若手エンジニアの成長ストーリーは以下の記事で詳しくご紹介していますので、ぜひご覧ください!
▼採用情報
レアゾン・ホールディングスは、「世界一の企業へ」というビジョンを掲げ、「新しい"当たり前"を作り続ける」というミッションを推進しています。 現在、エンジニア採用を積極的に行っておりますので、ご興味をお持ちいただけましたら、ぜひ下記リンクからご応募ください。