レシピを自動で取得したい
毎日のおかずを考えるのって、結構大変ですよね![]()
そんなとき、今晩のおかずを提案してくれるサービスがあったらいいなと思いませんか?
これを実装するためには、「料理のレシピを取得する」ことが必要です。
世の中にはレシピサイトは数多くありますが、楽天レシピがWeb APIを提供しているのでこれを使って**「任意のキーワードから人気レシピを取得する」**ことをPythonをで実現してみましょう。
楽天レシピAPIで人気レシピを取得しよう
準備
まず、楽天レシピAPIを利用するにはユーザー登録(無料)を行ってアプリIDを取得する必要があります。
その方法についてはこちらの記事の序盤部分をご参照いただければと思います。
以降、本記事ではアプリIDを取得できた前提で話を進めていきます。
APIの概略
楽天レシピAPIには2つのAPIが用意されています。
- 楽天レシピカテゴリ一覧API:楽天レシピのカテゴリ一覧を返す。
- 楽天レシピカテゴリ別ランキングAPI:楽天レシピの各カテゴリで人気トップ4までのレシピを取得する。
つまり、魚が食べたいな~と思ったときに「魚」というキーワードから直接的にレシピを取得することはできないということです。よって、ひと工夫する必要があります。
処理の流れとしては、
- 「楽天レシピカテゴリ一覧API」でレシピカテゴリ一覧を取得する。
- 1で取得した一覧の中から、検索したいキーワードを含むレシピカテゴリを抽出する。
- 2で抽出したレシピカテゴリに対して「楽天レシピカテゴリ別ランキングAPI」を使って人気レシピを取得する。
という方法が良さそうです。
では、順を追ってやっていきましょう!
1. 楽天レシピのレシピカテゴリ一覧を取得する
「楽天レシピカテゴリ一覧API」を利用して、カテゴリ一覧を取得します。
詳細はAPIドキュメントもご参照ください。
import requests
import json
from pprint import pprint
res = requests.get('https://app.rakuten.co.jp/services/api/Recipe/CategoryList/20170426?applicationId=xxxxx')
json_data = json.loads(res.text)
pprint(json_data)
requestsを使って楽天レシピカテゴリ一覧APIのエンドポイントに対してGETリクエストを行います。
このときapplicationId=xxxxxのxxxxxの部分にはあなたのアプリIDを記載してくださいね。
取得したレスポンス(res)はJSON形式になっているので、json.loads()でJSONとして読み込んで、pprint()で整形して表示します。
すると次のような結果が得られます。これが楽天レシピのカテゴリ一覧です。
{'result': {'large': [{'categoryId': '30',
'categoryName': '人気メニュー',
'categoryUrl': 'https://recipe.rakuten.co.jp/category/30/'},
{'categoryId': '31',
'categoryName': '定番の肉料理',
'categoryUrl': 'https://recipe.rakuten.co.jp/category/31/'},
{'categoryId': '32',
'categoryName': '定番の魚料理',
'categoryUrl': 'https://recipe.rakuten.co.jp/category/32/'},
…
ここから各レシピカテゴリのカテゴリID('categoryId')がわかるので、このカテゴリIDを「楽天レシピカテゴリ別ランキングAPI」のインプットとすることで、そのカテゴリにおける人気レシピの情報を取得することができるというわけです。
ここで注意が必要なのは、楽天レシピのカテゴリは
- 大カテゴリ
- 中カテゴリ
- 小カテゴリ
に分かれていて、それぞれ親子関係となっています。
親子のカテゴリIDはハイフンで結合する必要があるので、categoryIdは次のような形式になります。
categoryId=10 (大カテゴリ)
categoryId=10-276 (中カテゴリ)
categoryId=10-276-824 (小カテゴリ)
わかりにくいかもしれないので、例をあげましょう。
'坦々麺'という中カテゴリがあります。
{'categoryId': 541,
'categoryName': '坦々麺',
'categoryUrl': 'https://recipe.rakuten.co.jp/category/41-541/',
'parentCategoryId': '41'},
この場合、自身のカテゴリID(categoryId)である'541'と親カテゴリID(parentCategoryId)である'41'をハイフンで繋いだ41-541が担々麺のcategoryIdになるというわけです。
実装としては下記のような方法があります。
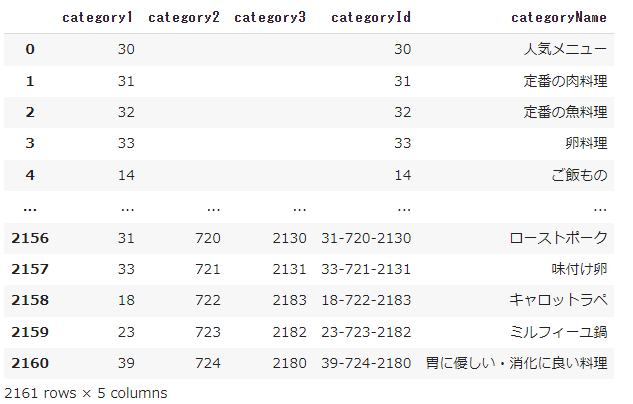
ここでは、カテゴリを一覧をすべて取得して、中カテゴリ・小カテゴリについては、parentCategoryIdとハイフンで繋いでcategoryIdを作ってDataFrameに格納しています。
import pandas as pd
# mediumカテゴリの親カテゴリの辞書
parent_dict = {}
df = pd.DataFrame(columns=['category1','category2','category3','categoryId','categoryName'])
# 大カテゴリ
for category in json_data['result']['large']:
df = df.append({'category1':category['categoryId'],'category2':"",'category3':"",'categoryId':category['categoryId'],'categoryName':category['categoryName']}, ignore_index=True)
# 中カテゴリ
for category in json_data['result']['medium']:
df = df.append({'category1':category['parentCategoryId'],'category2':category['categoryId'],'category3':"",'categoryId':str(category['parentCategoryId'])+"-"+str(category['categoryId']),'categoryName':category['categoryName']}, ignore_index=True)
parent_dict[str(category['categoryId'])] = category['parentCategoryId']
# 小カテゴリ
for category in json_data['result']['small']:
df = df.append({'category1':parent_dict[category['parentCategoryId']],'category2':category['parentCategoryId'],'category3':category['categoryId'],'categoryId':parent_dict[category['parentCategoryId']]+"-"+str(category['parentCategoryId'])+"-"+str(category['categoryId']),'categoryName':category['categoryName']}, ignore_index=True)
これでdfというDataFrameにカテゴリ名とカテゴリIDが格納できました。
2. キーワードからカテゴリを抽出する
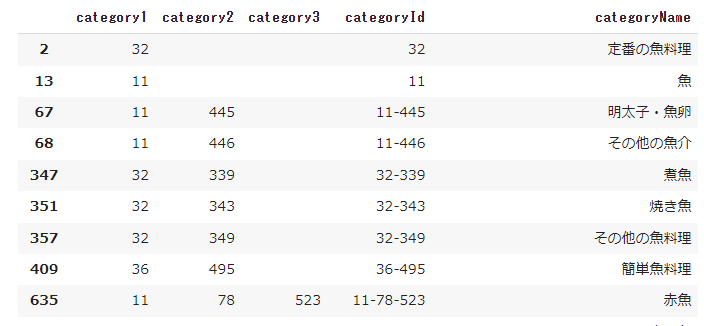
では次にdfのcategoryNameの列を検索して、検索したいキーワードを含む行を抽出してみましょう。
ここでは"魚"が食べたいとして、カテゴリ名に"魚"を含む行を抽出してみます。
# キーワードを含む行を抽出
df_keyword = df.query('categoryName.str.contains("魚")', engine='python')
3. 人気レシピを取得する
「楽天レシピカテゴリ別ランキングAPI」にcategoryIdを指定してあげればOKです。
公式ドキュメントのリンクも貼っておきます。
例えば、「煮魚」であればcategoryIdは32-339なので、下記のようなコードになります。
# 「煮魚」カテゴリの人気レシピを取得
res = requests.get('https://app.rakuten.co.jp/services/api/Recipe/CategoryRanking/20170426?applicationId=xxxxx&categoryId=32-339')
json_data = json.loads(res.text)
pprint(json_data)
{'result': [{'foodImageUrl': 'https://image.space.rakuten.co.jp/d/strg/ctrl/3/3697d133520a128ccda775bba8b7fb6274611b07.97.2.3.2.jpg',
'mediumImageUrl': 'https://image.space.rakuten.co.jp/d/strg/ctrl/3/3697d133520a128ccda775bba8b7fb6274611b07.97.2.3.2.jpg?thum=54',
'nickname': 'ムーミンママ24',
'pickup': 0,
'rank': '1',
'recipeCost': '300円前後',
'recipeDescription': '子持ちなめたカレイの煮付けです。しっかりめの味付けにしました。',
'recipeId': 1180006594,
'recipeIndication': '約15分',
'recipeMaterial': ['子持ちなめたカレイ切り身',
'☆酒',
'☆醤油',
'☆みりん',
'☆三温糖(ふつうの砂糖でも)',
'☆しょうが',
'☆ねぎの青い部分(なくても)'],
'recipePublishday': '2014/12/03 22:47:32',
'recipeTitle': '簡単・子持ちなめたカレイの煮付け',
'recipeUrl': 'https://recipe.rakuten.co.jp/recipe/1180006594/',
'shop': 0,
'smallImageUrl': 'https://image.space.rakuten.co.jp/d/strg/ctrl/3/3697d133520a128ccda775bba8b7fb6274611b07.97.2.3.2.jpg?thum=55'},
…
では、2で抽出したdf_keywordのカテゴリIDのレシピを順番に取得してみましょう。
import time
# 取得したレシピはDataFrameに格納する
df_recipe = pd.DataFrame(columns=['recipeId', 'recipeTitle', 'foodImageUrl', 'recipeMaterial', 'recipeCost', 'recipeIndication', 'categoryId', 'categoryName'])
for index, row in df_keyword.iterrows():
time.sleep(3) # 連続でアクセスすると先方のサーバに負荷がかかるので少し待つのがマナー
url = 'https://app.rakuten.co.jp/services/api/Recipe/CategoryRanking/20170426?applicationId=xxxxx&categoryId='+row['categoryId']
res = requests.get(url)
json_data = json.loads(res.text)
recipes = json_data['result']
for recipe in recipes:
df_recipe = df_recipe.append({'recipeId':recipe['recipeId'],'recipeTitle':recipe['recipeTitle'],'foodImageUrl':recipe['foodImageUrl'],'recipeMaterial':recipe['recipeMaterial'],'recipeCost':recipe['recipeCost'],'recipeIndication':recipe['recipeIndication'],'categoryId':row['categoryId'],'categoryName':row['categoryName']}, ignore_index=True)
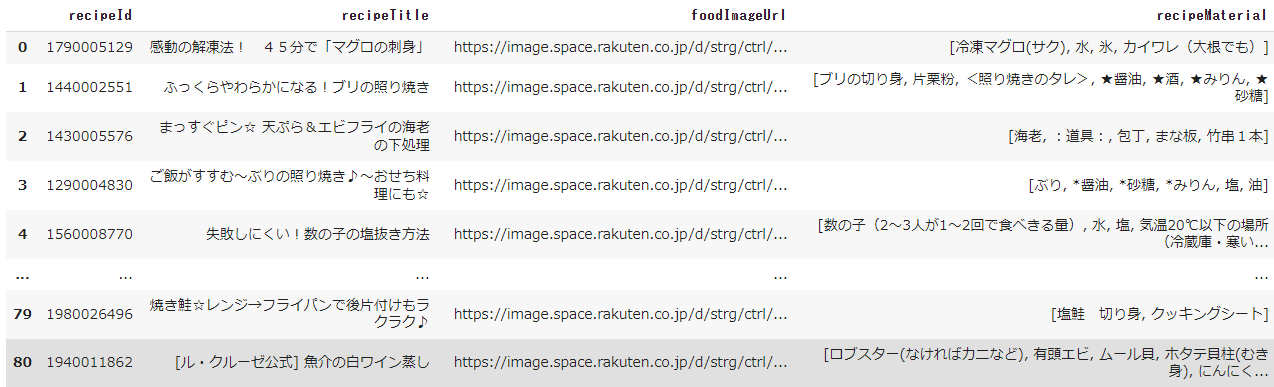
レシピが取得できましたね!
まとめ
最後に今回の全コードをまとめて載せておきます。
import requests
import json
import time
import pandas as pd
from pprint import pprint
# 1. 楽天レシピのレシピカテゴリ一覧を取得する
res = requests.get('https://app.rakuten.co.jp/services/api/Recipe/CategoryList/20170426?applicationId=xxxxx')
json_data = json.loads(res.text)
parent_dict = {} # mediumカテゴリの親カテゴリの辞書
df = pd.DataFrame(columns=['category1','category2','category3','categoryId','categoryName'])
for category in json_data['result']['large']:
df = df.append({'category1':category['categoryId'],'category2':"",'category3':"",'categoryId':category['categoryId'],'categoryName':category['categoryName']}, ignore_index=True)
for category in json_data['result']['medium']:
df = df.append({'category1':category['parentCategoryId'],'category2':category['categoryId'],'category3':"",'categoryId':str(category['parentCategoryId'])+"-"+str(category['categoryId']),'categoryName':category['categoryName']}, ignore_index=True)
parent_dict[str(category['categoryId'])] = category['parentCategoryId']
for category in json_data['result']['small']:
df = df.append({'category1':parent_dict[category['parentCategoryId']],'category2':category['parentCategoryId'],'category3':category['categoryId'],'categoryId':parent_dict[category['parentCategoryId']]+"-"+str(category['parentCategoryId'])+"-"+str(category['categoryId']),'categoryName':category['categoryName']}, ignore_index=True)
# 2. キーワードからカテゴリを抽出する
df_keyword = df.query('categoryName.str.contains("魚")', engine='python')
# 3. 人気レシピを取得する
df_recipe = pd.DataFrame(columns=['recipeId', 'recipeTitle', 'foodImageUrl', 'recipeMaterial', 'recipeCost', 'recipeIndication', 'categoryId', 'categoryName'])
for index, row in df_keyword.iterrows():
time.sleep(3) # 連続でアクセスすると先方のサーバに負荷がかかるので少し待つのがマナー
url = 'https://app.rakuten.co.jp/services/api/Recipe/CategoryRanking/20170426?applicationId=xxxxx&categoryId='+row['categoryId']
res = requests.get(url)
json_data = json.loads(res.text)
recipes = json_data['result']
for recipe in recipes:
df_recipe = df_recipe.append({'recipeId':recipe['recipeId'],'recipeTitle':recipe['recipeTitle'],'foodImageUrl':recipe['foodImageUrl'],'recipeMaterial':recipe['recipeMaterial'],'recipeCost':recipe['recipeCost'],'recipeIndication':recipe['recipeIndication'],'categoryId':row['categoryId'],'categoryName':row['categoryName']}, ignore_index=True)
Let's Python!
私の書いたPython関連の記事をいくつかリンクしておきますので、ご興味があればどうぞ!
素敵なPythonライフを![]()