1.はじめに
この記事は、インテル® FPGA Advent Calendar 2021の17日目の記事です。
インテル®FPGA上で動作するアプリをHLSで実装する場合は、OpenCLかoneAPIを使用する必要があります。最近では、FPGAだけでなくCPUやGPU上でも一貫したプログラミング作法で実装できるoneAPIが注目されています。本記事では、このoneAPIで実装した時に実際に発生した問題とそれをどのように解決したのかについて説明します。
- 動作確認環境
- OS:CentOS 7.6-1810
- SDK:インテル® oneAPI 2021.2.2
- FPGA:インテル®FPGAプログラマブルアクセラレーションカード
2.処理概要
今回実装した処理は以下になります。DDRに保存されているデータを取出し、「Kernel1」で処理を実行し、pipeで「Kernel2」に渡して処理を実行した後に再度DDRに書込むというものになります。OpenCLではDDR上のデータをGlobalで定義し、Kernel1,Kernel2内で処理して書込めばよいですが、oneAPIではどのように実装するのでしょうか?
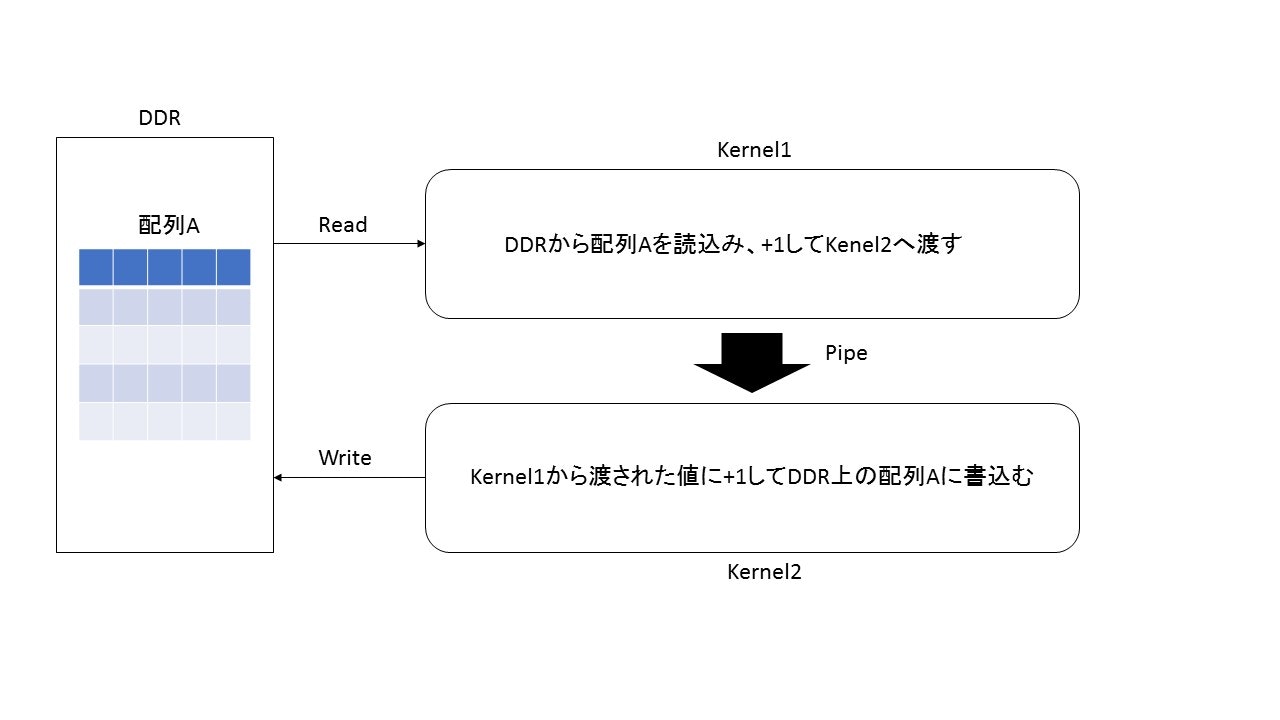
3.実装コード
oneAPIを用いて実装したコードは以下のようになります。
- oneAPI実装コード(パターン1)
# include <iomanip>
# include <iostream>
# include <numeric>
# include <vector>
# include <unistd.h>
# include <CL/sycl.hpp>
# include <CL/sycl/INTEL/fpga_extensions.hpp>
# include "dpc_common.hpp"
typedef struct {
float pt[16];
} st_trans;
using namespace sycl;
using NoCacheLSU = INTEL::lsu<INTEL::cache<0>>;
using Kernel1ToPipe = INTEL::pipe<
class Kernel1Pipe,
st_trans,
4>;
constexpr size_t maxx = 48;
constexpr size_t maxy = 48;
class Kernel1;
class Kernel2;
event kernel1(queue &q, buffer<float,1> &p_buffer) {
std::cout << "Enqueuing kernel1...\n";
auto e = q.submit([&](handler &h) {
accessor p_accessor(p_buffer, h, read_only);
h.single_task<Kernel1>([=]() {
st_trans trans;
int colloop = maxy/span;
float tmp[16]={0.0};
for (int i=0;i<colloop;i++) {
for (int j=0;j<maxx;j++) {
#pragma unroll
for (int k=0;k<16;k++) {
tmp[k] = p_accessor[j*maxy+i*16+k];
}
#pragma unroll
for (int k=0;k<16;k++) {
trans.pt[k] = tmp[k] + 1.0;
}
Kernel1ToPipe::write(trans);
}
}
});
});
return e;
}
event kernel2(queue &q, buffer<float, 1> &p_buf) {
std::cout << "Enqueuing kernel2...\n";
auto e = q.submit([&](handler &h) {
accessor p_accessor(p_buf, h, read_write);
h.single_task<Kernel2>([=]() {
st_trans trans_in;
int colloop = maxy/span;
float tmp[16] = {0.0};
for (int i=0;i<colloop;i++) {
for (int j=0;j<maxx;j++) {
trans_in = Kernel1ToPipe::read();
#pragma unroll
for (int k=0;k<16;k++) {
tmp[k] = trans_in.pt[k];
}
#pragma unroll
for (int k=0;k<16;k++) {
p_accessor[j*maxx+i*16+k] = tmp[k] + 1.0;
}
}
}
});
});
return e;
}
int main(int argc, char *argv[]) {
std::vector<float> p_vec(maxx*maxy, 0);
for (int i=0;i<maxx;i++) {
p_vec[i*maxy] = 100.0;
}
# if defined(FPGA_EMULATOR)
INTEL::fpga_emulator_selector device_selector;
# else
INTEL::fpga_selector device_selector;
# endif
event kernel1_event, kernel2_event;
try {
auto props = property_list{property::queue::enable_profiling()};
queue q(device_selector, dpc_common::exception_handler, props);
buffer p_buffer(p_vec);
kernel1_event = kernel1(q, p_buffer);
kernel2_event = kernel2(q, p_buffer);
} catch (exception const &e) {
std::cerr << "Caught a SYCL host exception:\n" << e.what() << "\n";
if (e.get_cl_code() == CL_DEVICE_NOT_FOUND) {
std::cerr << "If you are targeting an FPGA, please ensure that your "
"system has a correctly configured FPGA board.\n";
std::cerr << "Run sys_check in the oneAPI root directory to verify.\n";
std::cerr << "If you are targeting the FPGA emulator, compile with "
"-DFPGA_EMULATOR.\n";
}
std::terminate();
}
FILE *output;
output = fopen("output.dat","w");
for (int i=0; i<maxx ; i++){
for (int j=0; j<maxy; j++){
fprintf(output, "%f\n",p_vec[i*maxy+j]);
}
fprintf(output, "\n");
}
fclose(output);
return 0;
}
4.発生した問題
上記で実装したコードであるパターン1を実行すると、処理が途中で止まるという事象が発生します。デバックなどを行ってみるとどうやら、Kernel1でいくつかのデータは処理されているようですが、pipeにデータを渡すところで止まっているように思えます。
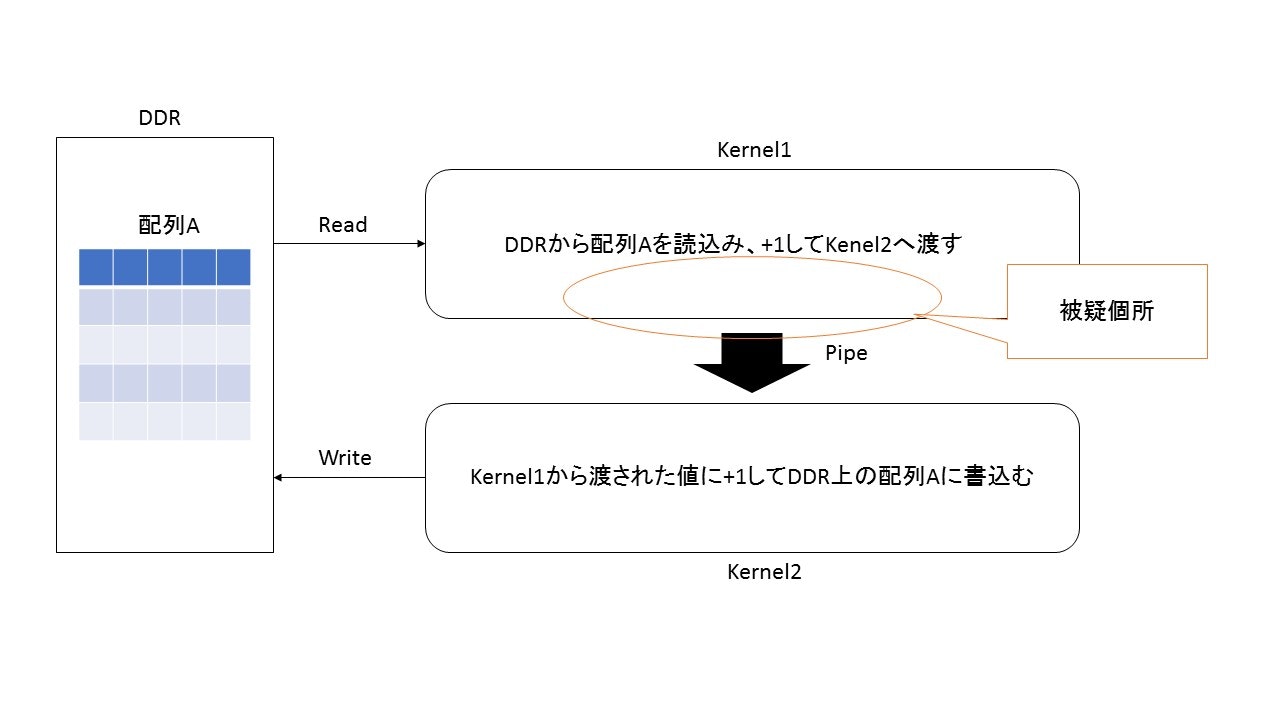
5.暫定対処方法
暫定的に処理を動作させるためには、以下の部分を修正することで対処可能です。
ポイントはpipeのバッファサイズを大きくすることです。このサイズを読み込みたい配列以上に設定することで、動作はします。
ただし、この暫定対処の場合は、Kernel1の動作が終わった後にKernel2の動作が開始されるので、
Kernel1,Kernel2がシーケンシャルに動作してしまい、性能面で課題があります。
- 修正前
using Kernel1ToPipe = INTEL::pipe<
class Kernel1Pipe,
st_trans,
4>;
- 修正後
using Kernel1ToPipe = INTEL::pipe<
class Kernel1Pipe,
st_trans,
4000000>;
6.本格対処方法
先ほどの暫定対処では、Kernel1とKernel2がシーケンシャルに動作してしまうため、この部分を改善する必要があります。Kernel1で処理済みのデータをすぐにKernel2で処理するのが理想ですが、いったいどうしたらよいのでしょうか?
そこでoneAPIのUnified Shared Memory(USM)を利用します。このUSMを使用することで意図した動作を実行することが可能になります。主な修正箇所は以下になります。
- 修正前
buffer p_buffer(p_vec);
kernel1_event = kernel1(q, p_buffer);
kernel2_event = kernel2(q, p_buffer);
- 修正後
float *p_buffer = malloc_device<float>(maxx*maxy*sizeof(float),q);
auto copy_host_device_event = q.memcpy(p_buffer, p_vec.data(), maxx*maxy*sizeof(float));
kernel1_event = kernel1(q, p_buffer);
kernel2_event = kernel2(q, p_buffer);
auto copy_device_to_host_event = q.submit([&](handler& h) {
h.depends_on(kernel1_event);
h.memcpy(out_vec.data(), p_buffer, maxx*maxy*sizeof(float));
また、USMを利用した実装コードも以下に掲載します。
- oneAPI実装コード(パターン2)
# include <iomanip>
# include <iostream>
# include <numeric>
# include <vector>
# include <unistd.h>
# include <CL/sycl.hpp>
# include <CL/sycl/INTEL/fpga_extensions.hpp>
# include "dpc_common.hpp"
typedef struct {
float pt[16];
} st_trans;
using namespace sycl;
using NoCacheLSU = INTEL::lsu<INTEL::cache<0>>;
using Kernel1ToPipe = INTEL::pipe<
class Kernel1Pipe,
st_trans,
4>;
constexpr size_t maxx = 48;
constexpr size_t maxy = 48;
class Kernel1;
class Kernel2;
event kernel1(queue &q, float *p_buffer) {
std::cout << "Enqueuing kernel1...\n";
auto e = q.submit([&](handler &h) {
cl::sycl::stream os(1024,256,h);
h.single_task<Kernel1>([=]() {
device_ptr<float> p_accessor(p_buffer);
st_trans trans;
int colloop = maxy/span;
float tmp[16]={0.0};
for (int i=0;i<colloop;i++) {
for (int j=0;j<maxx;j++) {
#pragma unroll
for (int k=0;k<16;k++) {
tmp[k] = p_accessor[j*maxy+i*16+k];
}
#pragma unroll
for (int k=0;k<16;k++) {
trans.pt[k] = tmp[k] + 1.0;
}
Kernel1ToPipe::write(trans);
}
}
});
});
return e;
}
event kernel2(queue &q, float *p_buf) {
std::cout << "Enqueuing kernel2...\n";
auto e = q.submit([&](handler &h) {
h.single_task<Kernel2>([=]() {
device_ptr<float> p_accessor(p_buf);
st_trans trans_in;
st_trans trans_out;
int colloop = maxy/span;
float tmp[16] = {0.0};
for (int i=0;i<colloop;i++) {
for (int j=0;j<maxx;j++) {
trans_in = Kernel1ToPipe::read();
#pragma unroll
for (int k=0;k<16;k++) {
tmp[k] = trans_in.pt[k];
}
#pragma unroll
for (int k=0;k<16;k++) {
p_accessor[j*maxx+i*16+k] = tmp[k] + 1.0;
}
}
}
});
});
return e;
}
int main(int argc, char *argv[]) {
std::vector<float> p_vec(maxx*maxy, 0);
std::vector<float> out_vec(maxx*maxy, 0);
for (int i=0;i<maxx;i++) {
p_vec[i*maxy] = 100.0;
}
# if defined(FPGA_EMULATOR)
INTEL::fpga_emulator_selector device_selector;
# else
INTEL::fpga_selector device_selector;
# endif
event kernel1_event, kernel2_event;
try {
auto props = property_list{property::queue::enable_profiling()};
queue q(device_selector, dpc_common::exception_handler, props);
float *p_buffer = malloc_device<float>(maxx*maxy*sizeof(float),q);
auto copy_host_device_event = q.memcpy(p_buffer, p_vec.data(), maxx*maxy*sizeof(float));
kernel1_event = kernel1(q, p_buffer);
kernel2_event = kernel2(q, p_buffer);
auto copy_device_to_host_event = q.submit([&](handler& h) {
h.depends_on(kernel1_event);
h.memcpy(out_vec.data(), p_buffer, maxx*maxy*sizeof(float));
});
copy_device_to_host_event.wait();
free(p_buffer, q);
} catch (exception const &e) {
// Catches exceptions in the host code
std::cerr << "Caught a SYCL host exception:\n" << e.what() << "\n";
// Most likely the runtime couldn't find FPGA hardware!
if (e.get_cl_code() == CL_DEVICE_NOT_FOUND) {
std::cerr << "If you are targeting an FPGA, please ensure that your "
"system has a correctly configured FPGA board.\n";
std::cerr << "Run sys_check in the oneAPI root directory to verify.\n";
std::cerr << "If you are targeting the FPGA emulator, compile with "
"-DFPGA_EMULATOR.\n";
}
std::terminate();
}
FILE *output;
output = fopen("output.dat","w");
for (int i=0; i<maxx ; i++){
for (int j=0; j<maxy; j++){
fprintf(output, "%f\n",out_vec[i*maxy+j]);
}
fprintf(output, "\n");
}
fclose(output);
return 0;
}
7.まとめ
oneAPIを利用して今回のような処理を実装する場合は、意図しない処理待ちが発生する可能性があります。
USMを利用することでメモリ間での処理完了待ちをなくすことができますので、同様の処理を実装したい方は、ぜひともUnified Shared Memoryを使って頂ければと思います。
以上