はじめに
この記事は株式会社富士通システムズウェブテクノロジーが企画する
いのべこ夏休みアドベントカレンダー2020 33日目!!(延長戦)の記事です。
本記事の掲載内容は私自身の見解であり、所属する組織を代表するものではありません。
やったこと
当社の前回のアドカレに私が投稿した記事のなかで、
skit-learn に触って「ルーン文字」の手書き文字認識 を実装してみました。
一応作成はできたのですが、あれからDeepLearningの勉強をしたところ、
「画像認識をするなら、基本のニューラルネットワークではなく、
畳み込みニューラルネットワーク(CNN)を使うというもっといい方法がある!」と
いうことがわかったので、その実装と仕組みについてわかったことを共有します。
※引き続き、初学者の実践メモのため 今更感ある箇所もあるかと思いますが
同じくこれからKerasをこれから触ってみる人に手ごろな情報となれば幸いです。
なんでそもそもルーン文字なの?
ルーン文字、かっこいいですよね!

前回実施したことと問題点
前回やったこと
Pythonの機械学習用ライブラリであるscikit-learn を使って、
その中のMLPClassifierという「分類」を行うモデルを使って、手書きのルーン文字の分類を行いました。
データは自分で手書き文字の画像を準備し、それを「データの水増し(Data Augmentation)」で増やして学習に使いました。
結果と課題
結果として、だいたい80%くらいの精度で手書き文字の認識ができるモデルを作成することができました。
ただ以下のように、学習にあたって画像データを一次元の配列にしているところが気になっていました。
- データを読み込む部分の処理
# ディレクトリ内のファイルを読み込んで学習データのリストに追加する
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("L")
image = image.resize((image_size, image_size))
data = np.asarray(image).flatten() ## ★ここで画素の情報を一次元配列にしてしまっている
X.append(data)
# データを表示
np.set_printoptions(threshold=np.inf)
print(np.array(image2).flatten())
- 読み込んだ手書き文字画像
データの出力結果
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 15 94 34 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 160 253 135 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 91 244 229 243 229 72 17 1 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 38 181 253 123 162 225 242 192 144 84 64 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 142 241 138 0 31 62 125 169 250 247 212 210 62 31 5 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 63 231 225 50 0 0 1 0 19 46 176 211 244 247 193 166 107 80 0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 159 255 171 10 0 0 0 0 0 1 0 49 86 137 175 251 251 243 209 72 21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 48 218 247 71 0 0 0 0 0 0 0 0 0 0 0 12 59 165 180 216 253 119 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 133 248 173 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 111 224 240 113 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 30 245 246 51 0 0 0 0 0 0 0 0 0 0 0 0 0 2 40 244 253 94 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 147 251 177 23 0 0 0 0 0 0 0 0 0 0 0 0 0 103 228 222 117 14 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 43 204 244 102 0 0 0 0 0 0 0 0 0 0 0 0 0 31 179 251 152 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 93 248 228 0 0 0 0 0 0 0 0 0 0 0 0 0 21 159 255 250 43 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 191 251 88 0 0 0 0 0 0 0 0 0 0 0 0 0 35 219 225 105 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 74 216 199 25 0 0 0 0 0 0 0 0 0 0 0 0 35 158 252 148 33 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 96 251 135 0 0 0 0 0 0 0 0 0 0 0 0 0 97 239 228 10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 175 253 63 1 1 0 0 0 0 0 0 0 0 0 0 14 236 225 74 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 26 180 224 156 118 26 1 0 0 0 0 0 0 0 0 28 150 245 136 23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 29 103 254 255 255 234 90 72 19 20 0 0 0 0 0 92 220 205 30 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 94 171 207 249 239 219 224 170 107 13 23 0 11 198 253 42 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 0 44 67 109 150 252 240 254 228 152 135 203 245 166 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 42 104 135 183 235 246 249 251 190 26 17 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 25 41 253 255 238 251 219 153 108 46 14 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 212 231 138 128 179 243 239 217 179 87 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 112 246 174 0 7 26 36 165 244 249 252 197 87 48 12 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 26 228 236 84 0 0 0 0 0 54 111 167 204 255 207 150 64 30 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 101 243 185 29 0 0 0 0 0 0 3 15 53 83 191 246 250 165 107 34 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 11 169 241 115 0 0 0 0 0 0 0 0 0 0 4 14 75 159 224 231 199 125 65 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 50 232 225 0 0 0 0 0 0 0 0 0 0 0 0 0 2 11 35 133 255 253 209 150 24 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 117 242 122 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 33 134 164 87 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 18 160 225 62 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 24 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 235 186 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 110 249 109 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 168 240 106 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 35 185 220 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 169 97 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
上記のように、一次元配列の中に
画像の左上から右下までのピクセルの情報がフラットに入ってしまっているはずです。
これだと画像の縦横の情報は失われてしまいますよね…。
畳み込みニューラルネットワーク(CNN)の使用
これに対して、畳み込みニューラルネットワーク(CNN)というものを使うと
縦横の情報を保持したデータで学習できることを知りました!
以下、自分なりに整理した概要と実装方法を記載します。
概要
畳み込みニューラルネットワーク(Convolutional Neural Network:CNN)は
画像の処理分野で用いられるニューラルネットワークで、
画像をそのまま二次元で入力に用いることができます。
CNNの大本は、「人間が持つ視覚野の神経細胞のうごきを模してみよう」ということで
生み出された方法です。
CNNではフィルタ(カーネル)を使って画像から特徴を抽出します。
フィルタは元の画像より小さいものを使います。
フィルタを画像の左上から、順番に重ね合わせていき、
画像とフィルタの値をそれぞれかけ合わせたものの総和を取った値を求めていきます。
フィルタの数字をどうするかによって、画像から得られる特徴が変わっていくので、
フィルタをどういった値にすればいいかを学習します。
[参考] 以下サイトで、CNNの文字認識のプロセスを目で見ることができます!
https://www.cs.ryerson.ca/~aharley/vis/conv/
実装方法
以下2パターンの実装方法がありそうです!
1. Numpy を使って手組
CNNのフィルタ演算処理を手組で実装する方法です。
こちらの記事で実践されています。
https://qiita.com/ta-ka/items/1c588dd0559d1aad9921
2. Keras のライブラリを使用
Kerasという深層学習に特化したライブラリを使ってCNNを実装することもできます。
Kerasは,Pythonで書かれた,TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリです.
次のような場合で深層学習ライブラリが必要なら,Kerasを使用してください:
・CNNとRNNの両方,およびこれらの2つの組み合わせをサポート
今回は、2.Kerasのライブラリを使用してみることにします。
Keras の使用
今回の目的でKerasを使用しようとする際は以下の選択肢がありそうです。
- スタンドアローンのKeras を直接呼び出して使う
- TensorFlow に同梱されたKeras を使う
ただし、2020年5月より 公式のマニュアルで
「Kerasはtensorflow.kerasとして、TensorFlow 2.0と一緒に入ります。
Kerasを始めるには、シンプルにTensorFlow 2.0をインストールしてください」
と記載されるなど、「TensorFlowのKeras」に統一する流れとなっているようです。(以下記事から引用)
[参考] マルチバックエンドKerasの終焉、tf.kerasに一本化
https://www.atmarkit.co.jp/ait/articles/2005/13/news017.html
時代の流れに従い今回はTensorflowのKerasを使用してみます。
使用したもの
というわけで、使用したものは以下になります。
TensorFlowは、Kerasとの統合が強化された バージョン 2.0.0 を使用する必要がありました。
- Anaconda : (Python本体とよく使われるライブラリを含んだパッケージです)
- TensorFlow : 2.0.0
使用したデータ
一旦、前回作成した画像データ(24(文字)×18(枚))で学習させてみます。
実装
使用するパッケージのインポート
# 配列を扱うためのパッケージ
import numpy as np
# 画像データやファイルを扱うためのパッケージ
from PIL import Image
import os, glob
# tensorflow
import tensorflow as tf
# データの前処理をやってくれるKerasの便利パッケージ
from tensorflow.keras.preprocessing.image import array_to_img, img_to_array, load_img
from keras.utils import np_utils
# 学習データとテスト用データの分割に使用
from sklearn.model_selection import train_test_split
# 学習データの画像表示に使用
import matplotlib.pyplot as plt
# 学習結果のサマリ表示に使用
import pandas as pd
ファイルの読み込み
学習に使う画像とラベルのセットを準備します。
今回、KerasのCNNのモデルには、各データのラベルを数値で渡さなければいけないようです。
あらかじめ 各ルーン文字とラベル(数値)の対応表をDictionaryで作成しました。
ルーン文字・ラベル(数値)の対応表
runeCharDict = { 0 : 'ᚠ',
1 : 'ᚢ',
2 : 'ᚦ',
3 : 'ᚫ',
4 : 'ᚱ',
5 : 'ᚲ',
6 : 'ᚷ',
7 : 'ᚹ',
8 : 'ᚺ',
9 : 'ᚾ',
10 : 'ᛁ',
11 : 'ᛃ',
12 : 'ᛇ',
13 : 'ᛈ',
14 : 'ᛉ',
15 : 'ᛋ',
16 : 'ᛏ',
17 : 'ᛒ',
18 : 'ᛖ',
19 : 'ᛗ',
20 : 'ᛚ',
21 : 'ᛜ',
22 : 'ᛞ',
23 : 'ᛟ',
}
画像を読み込みます。
# ファイル読み込み
# 画像データを格納する配列
X = []
# 画像データに対応する文字(答え)を格納する配列
Y = []
# 学習データのディレクトリ・ファイル
dir = '[手書き文字の画像データが格納されているディレクトリ]'
files = glob.glob(dir + "\\*.png")
# 画像の縦横のサイズ(ピクセル)
image_size = 50
# ディレクトリ内のファイルを読み込んで学習データのリストに追加する
for i, file in enumerate(files):
temp_img = load_img(file, target_size=(image_size, image_size))
temp_img_array = img_to_array(temp_img)
X.append(temp_img_array)
moji = file.split("\\")[-1].split("_")[0]
label = list(runeCharDict.keys())[list(runeCharDict.values()).index(moji)]
Y.append(label)
X = np.asarray(X)
Y = np.asarray(Y)
# 画素値を0から1の範囲に変換
X = X.astype('float32')
X = X / 255.0
# クラスの形式を変換
Y = np_utils.to_categorical(Y, 24)
モデルを作成
学習させるモデルを作成します。
ここで「畳み込み層の設定(入力データの形状,フィルタの設定)」や「使用する活性化関数」を設定します。
各要素の詳細な説明はこちらの記事で大変詳しく記載されていますので
ご参照ください…!
# CNNのモデルを作成する
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(50, 50, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(24, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
学習
学習自体はfit()関数を呼び出すだけで実行できます。
# 学習データとテストデータを分離
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=111)
# 学習
model.fit(x_train, y_train, epochs=5)
実行すると、それぞれの学習のサマリが表示されます。
Epoch 1/5
246/246 [==============================] - 2s 9ms/sample - loss: 3.1595 - acc: 0.0935
Epoch 2/5
246/246 [==============================] - 2s 9ms/sample - loss: 2.8289 - acc: 0.2317
Epoch 3/5
246/246 [==============================] - 2s 8ms/sample - loss: 2.0306 - acc: 0.4593
Epoch 4/5
246/246 [==============================] - 2s 8ms/sample - loss: 1.0820 - acc: 0.7642
Epoch 5/5
246/246 [==============================] - 2s 9ms/sample - loss: 0.6330 - acc: 0.8333
右側の要素を確認すると、学習においてのモデルの正答率がわかります。
- loss:損失関数の評価値です(低いほど予測の精度が高い)。
- acc: 予測に対する正解率(accuracy)です。
1回目の学習では正解率(accuracy)は9%程度でしたが、5回目の学習では83%の精度が出せるようになっています!
モデルのテスト・結果の表示
モデルに検証データを予測させてみます。
# テストデータに適用
predict_classes = model.predict_classes(x_test)
mg_df = pd.DataFrame({'predict': predict_classes, 'class': np.argmax(y_test, axis=1)})
# 現在の最大表示列数の出力
pd.get_option("display.max_columns")
# 最大表示列数の指定(ここでは50列を指定)
pd.set_option('display.max_columns', 50)
# confusion matrix
pd.crosstab(mg_df['class'], mg_df['predict'])
テストデータの予測に対する正誤をとり、混同行列(confusion matrix)を作成します。
混合行列は、「実際の値\モデルの予測した値」の組み合わせ表です。
同じ数字の行・列が交差している箇所が、正解したデータの数です。
結果
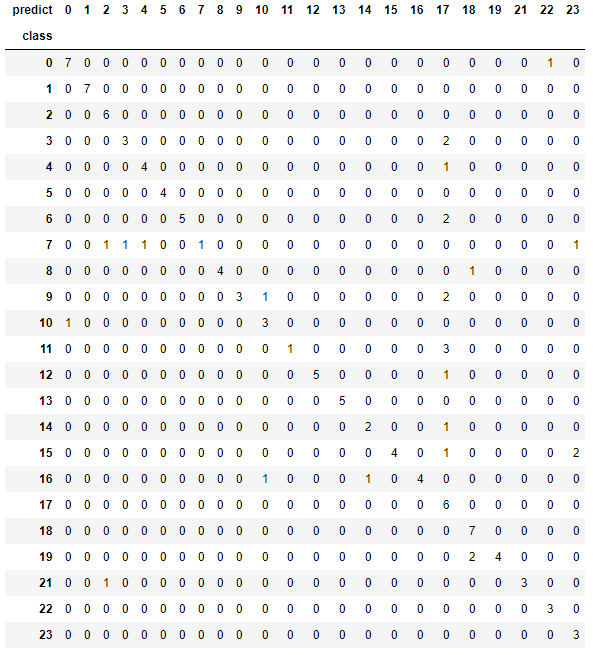
正解が多数を占めてます!
あとは、結果の表の17番にあたる「ᛒ」の文字で誤答が多いことなどもわかります。
実際にもっと正答率を上げたい場合は、「ᛒ」のデータを見直したり増やしたりすると良いのかもしれません。
データの水増し
ちょっと学習データが少ない気がするため、手書き文字画像を加工して学習データを増やします。
今回は、keras_preprocessing という前処理のパッケージで簡単に文字データの回転ができたので
そちらもデータに加えます。
# Kerasが裏で使っているkeras_preprocessing
from keras_preprocessing.image import apply_affine_transform
# ファイル読み込み
# 画像データを格納する配列
X = []
# 画像データに対応する文字(答え)を格納する配列
Y = []
# ファイル読み込み(前述)
# ディレクトリ内のファイルを読み込んで学習データのリストに追加する
for i, file in enumerate(files):
# オリジナルデータを登録(前述)
# データの水増
image = img_to_array(temp_img)
# 1.時計回りに10度回転 「theta=」で回転させる度数を指定
image1 = apply_affine_transform(image, channel_axis=2, theta=10, fill_mode="nearest", cval=0.)
X.append(image1)
Y.append(label)
# 2.反時計回りに10度回転
image2 = apply_affine_transform(image, channel_axis=2, theta=-10, fill_mode="nearest", cval=0.)
X.append(image2)
Y.append(label)
# # 3.時計回りに20度回転
image3 = apply_affine_transform(image, channel_axis=2, theta=20, fill_mode="nearest", cval=0.)
X.append(image3)
Y.append(label)
# 4.反時計回りに20度回転
image4 = apply_affine_transform(image, channel_axis=2, theta=-20, fill_mode="nearest", cval=0.)
X.append(image4)
Y.append(label)
とても簡単に済みました!!
特に、回転によって発生した余白に対して補完処理が入っているので、
背景が黒くなってしまうということがありません。ものすごく便利なのでは…?
学習結果
元画像を回転させて増やしたデータも加えて、再度学習させてみます。
Epoch 1/5
1232/1232 [==============================] - 7s 6ms/sample - loss: 23.2898 - accuracy: 0.1144
Epoch 2/5
1232/1232 [==============================] - 7s 6ms/sample - loss: 1.1991 - accuracy: 0.6396
Epoch 3/5
1232/1232 [==============================] - 7s 5ms/sample - loss: 0.3489 - accuracy: 0.8847
Epoch 4/5
1232/1232 [==============================] - 7s 5ms/sample - loss: 0.1527 - accuracy: 0.9456
Epoch 5/5
1232/1232 [==============================] - 6s 5ms/sample - loss: 0.0839 - accuracy: 0.9740
データ数が少ない時よりも、モデルが高い精度を出せるようになりました!(97%)
終わりに
以上、pythonでKerasを使って畳み込みニューラルネットワークを使用する流れを記載しました。
思ったこと
- 全く同じデータでの比較はできていませんが、CNNを使用することで、前回の基本のニューラルネットワークよりも高い精度が出せていることがわかりました。
- 全体的に、tensorflowとKerasのライブラリを使用することで 前処理や学習・予測結果の表示などにおいて、前回よりもコードをすっきり書ける箇所が多かったです!
- 今回フワッとした理解のまま実装箇所については改めて調べて理解していきたいです。
本記事が何かの参考になれば幸いです。
最後に、割と完全に遅刻してしまいすみませんでした!
夏のアドカレにも参加できてよかったです、ありがとうございました。