はじめに
みなさん、KPOP聴いてますか?僕はあまり聴いてません。
しかし、講師と仲が良いという経緯で東大KPOPゼミなるものをTAというか運営をしております。
これは前期教養課程の戦場である駒場キャンパスで開催しているので、参加者は理系、文系ともに存在(むしろ文系が多い)し、バックグラウンドも様々です。
ここで、KPOPを何も知らない僕に、運営ということで発表の機会が投げられました。KPOP分からないのに。
というわけで、いつもインターンでやっている テキストマイニング を、 KPOPの歌詞 に対して行ってみようかと思います。
ただし、 テキストマイニングは技術より解釈が難しいので 、 ゼミで議論できる前準備を温め、 ちゃんと整理された 結果をぶつけようと考えております。
恐らく実装を見たいエンジニア層と、結果発表を見たい一般層に読者が分かれていると思うので、
- 「手法・実装」の節
- 「結果・発表」の節
に分けます。
手法・実装
データ収集
まずは、データたる歌詞を集めます。
対象
対象となる歌詞の選定基準について、いろいろ考えましたが、 Spotifyのプレイリストなるもの を活用することにしました。
Spotifyは無料APIが公開されていて、プレイリストからデータを取得する流れを一度自動化すると、その後の作業が簡略化できるからですね。
「グローバル vs KPOP」「KPOP vs 特定アーティスト」という構図の分析をしたいので、
- グローバル:「Billboard」「Best」がついたプレイリスト
- KPOP: 「Best」がついたプレイリスト
- 特定アーティスト: 「All (アーティスト名)」
という基準で手動でプレイリストを選定しました。
SpotifyのAPI利用はspotipyライブラリが便利です。
"""
Fetch songs from Spotify list
"""
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
with open("spotify_api.txt", "r", encoding="utf-8") as file:
texts = file.read().split("\n")
client_id = texts[0]
client_secret = texts[1]
client_credentials_manager = SpotifyClientCredentials(client_id=client_id, client_secret=client_secret)
client = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
def fetch_tracks_from_list(spotify_list_id):
musics = []
items = _fetch_all_tracks(spotify_list_id)
for item in items:
track = item["track"]
track_name = track["name"]
track_id = track["id"]
musics.append((track_name, track_id))
return musics
def fetch_tracks_from_list_url(spotify_list_url):
last_domain = spotify_list_url.split("/")[-1]
# Remove query
list_id = last_domain.split("?")[0]
return fetch_tracks_from_list(list_id)
def _fetch_all_tracks(spotify_list_id):
results = client.playlist_items(spotify_list_id)
items = results['items']
while results['next']:
results = client.next(results)
items.extend(results['items'])
return items
if __name__ == "__main__":
musics = fetch_tracks_from_list_url("https://open.spotify.com/playlist/0quPSM9DiUpY9RZIzlc0w0")
for music in musics:
print(music)
print(len(musics))
歌詞収集
robots.txtとterms of serviceの両方を確認して、スクレイピングが問題ないと判断したサイトを対象にスクレイピングを行いました。
いつか禁止される可能性もあるので、スクリプトは公開しません。
前処理
同じ土俵で比較したいため、 全て英語 にしたいのですが、元から英語のものと、翻訳された英語のものをそのまま比較すると差異が生じる可能性を考慮し、 全てイタリア語に翻訳してから、英語へ翻訳 するようにしました。
別にイタリア語である必要はないのですがね。
大量翻訳はこちら: 金を払わず、自分の環境を汚さずに、大量の文書を翻訳する
分析処理
分析処理レポジトリ・ノートブックはこちら: GitHubレポジトリへ飛ぶ
TF-IDF; 特徴語を見る
ちゃんとした説明はこちら: TF-IDFの基本的な考え方と実装方法
TF-IDFは要するに、 単語がその歌詞を特徴づける度合いスコア という説明ができます。
例えば、こちらの記事に「羅生門」のTF-IDFを計算した結果があります。 数値が高い単語が「キーワード」になっていると解釈できます
重要な視点として、 何を母集団にするか があります。
例えば、
- イスラム教に関するWikipedia記事を集めたとき、「Budda」という単語はとてもレアで、もし「Budda」という単語が書かれている記事があれば その記事のキーワードになる
- 一方、上座部仏教のWikipedia記事を集めた時、「Budda」は割とどの記事にも出てくるので、レア度はかなり低く、 キーワードにはあまりならない
というように、母集団に対するその単語の レア度 が重要になります。
そのレア度はTF-IDFの IDF の部分です。レア度はしっかりと計算結果に出てくるので、我々は 何が母集団か を意識する必要があります。
そこで、二つの母集団として、
- グローバル母集団に対して
- KPOP母集団に対して
の二通りの分析処理を行いました。
そして、TFIDFは一つの歌詞について与えられるものですが、グループとしての傾向(例えば"Dynamite"単体ではなく、「BTS」全体のキーワード)を知りたいので、グループ内のTFIDFを集計しないといけません。
そこで、
- 各歌詞の単語のTFIDFが設定した閾値を超えた回数を数える
count
->どれだけ多く話題になっているかが分かる? - その単語のTFIDFの総和を求める
sum
-> (歌詞個別ではなく)グループ全体としてのその単語の特徴度が分かるはず。数式上も分配法則により足し算していいはず。
の二つの数値を出しました。
LDA; トピックを見つける
LDAという、ベイズ確率を使ったややこしい計算を通じて、 教師なし学習で トピック分類をする という手法があります。
ちゃんとした説明: LDAによるトピック解析 with Gensim
これをTFIDFと同様に、
二つの母集団
- グローバル母集団に対して
- KPOP母集団に対して
二つの指標
countsum
について算出しました。
NRC感情分析
カナダ国立研究評議会 (NRC = National Research Council Canada)から発表されている、単語->感情 対応データがあります。
この「感情」には
- "anger": 憤怒
- "anticipation": 不安
- "disgust": 不快
- "fear": 恐怖
- "joy": 喜び
- "sadness": 悲哀
- "surprise": 驚愕
- "trust": 信頼
が定義されています。
これはプルチックの感情分類に基づいています。
これを抽象化して、
- "negative"
- "positive"
もデータとして記録されています。
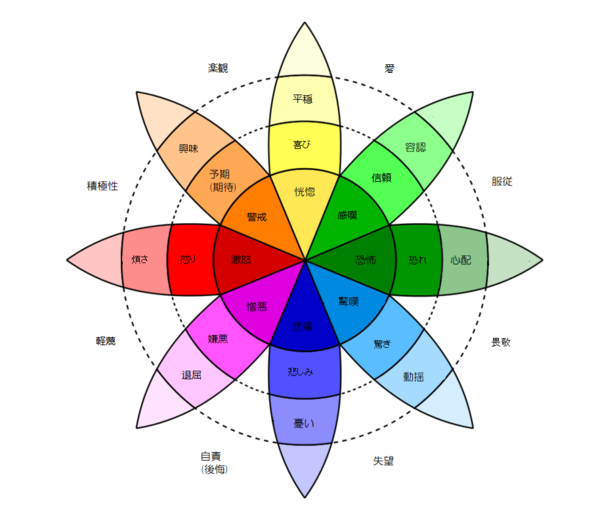
(プルチックの感情の輪; Wikipediaより引用)
NRCの感情分析の実装例を公開している日本語ソースが少ない、というか存在しなかったので、せっかくなのでこちらに記載します。
#ラベル一覧
labels = [
"anger",
"anticipation",
"disgust",
"fear",
"joy",
"sadness",
"surprise",
"trust",
"negative",
"positive",
]
emotions = [
"anger",
"anticipation",
"disgust",
"fear",
"joy",
"sadness",
"surprise",
"trust",
]
sentiments = [
"negative",
"positive",
]
#データの読み込み
df_nrc = pd.read_csv("NRC.txt", sep="\t", names=["word", "label", "amount"])
#元データは第3正規形なので、単語ごとのベクトルに変換する
words_to_labels = {}
for _, row in df_nrc.iterrows():
words_to_labels[row["word"]] = words_to_labels.get(row["word"], np.zeros((10, 1)))
words_to_labels[row["word"]][labels.index(row["label"])] = row["amount"]
前準備を終えて、歌詞にある全ての単語の感情ベクトルを加算して、歌詞全体の感情ベクトルを求めます。
#歌詞ごとに
for cnt in range(len(df)):
#歌詞のstring
lyrics = df["lyrics"][cnt]
if type(lyrics) != str:
continue
#この歌詞のベクトル(感情8, 極性2)
label_this = np.zeros((10, 1))
#加算
for word in lyrics.split():
if word in words_to_labels:
label_this += words_to_labels[word]
emotion_this = label_this[:8]
sentiment_this = label_this[8:]
#感情ベクトルを正規化する
if np.linalg.norm(emotion_this) != 0:
emotion_this /= np.linalg.norm(emotion_this)
#極性ベクトルを正規化する
if np.linalg.norm(sentiment_this) != 0:
sentiment_this /= np.linalg.norm(sentiment_this)
#記録
label_this = np.concatenate((emotion_this, sentiment_this), axis=None)
for label in labels:
df_label[label][cnt] = label_this[labels.index(label)]
感情・極性ベクトルを 正規化 (単位ベクトル化)しているのは、 歌詞の長さによって差異を出さないため です。
結果をまとめる
流石に分野外の皆さんにJupyter Notebookをそのまま見させるわけにはいきません。(分野外の方からすると、プログラムコード見なくてもいいよと言われても目に入って分かりづらいそうです)
細かい数値のお話なので、皆さんの端末で、ゆっくり眺めてほしいという気持ちがあり、オンライン上で、アクセスしやすいように... Webページにまとめます
フルスタックエンジニアの王、フルスタックエンジニアキングなので

レポジトリはこちら; https://github.com/konbraphat51/KpopLyrics
コンポーネント
Vue.jsのいいところで、HTMLをコンポーネントで抽象化すれば、for文で書けるので、記述は楽です。
これだけで
<IndividualAnalysis
v-for="group in groups"
:key="group"
:target="group"
:data="data"
/>
この5つのカタマリが作れます。
表の表示
縦にデカい表を表示したいですが、もちろんそのままではなく、ページめくりできた方が嬉しいですよね。
Tabulator.jsを使います。
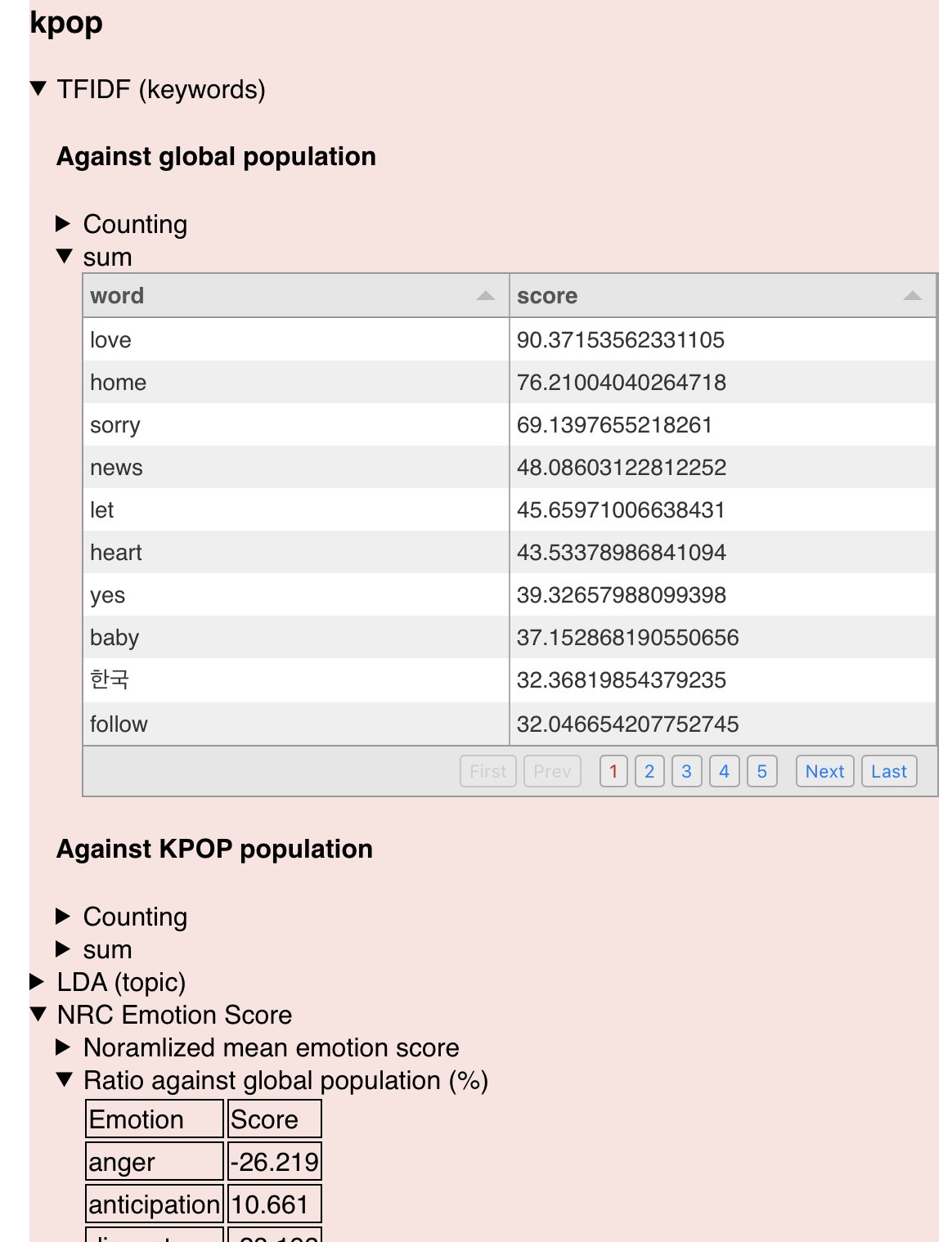
このようにCDNでインポートして
<link href="dist/css/tabulator.css" rel="stylesheet" />
<script type="text/javascript" src="dist/js/tabulator.js"></script>
こうしてdiv要素のidを参照してTabulatorインスタンスを作ることで表が作られます。
この時、表示するターゲットの配列は 連想配列の 配列 になっていないといけません。(普通の二次配列ではなく)
this.table = new Tabulator("#" + this.tableID, {
data: this.dataThis,
layout: "fitColumns",
pagination: "local",
paginationSize: 10,
columns: [
{title: "word", field: "word"},
{title: "score", field: "score"},
],
})
言語化
数値だけ見ても、(いくら東大生でも)しんどい方はしんどいでしょうから、論点をまとめたmarkdownをgistに投稿しました。
https://gist.github.com/konbraphat51/9ede89a4b5d768737f925ad761f44c56
結果・発表
東大KPOPゼミで、gistに書いた内容を、数値を見ながら説明しました。
筆者はKPOPを何も知らないので、ここで言っている洞察は 全てデタラメです
特徴語
TFIDFのお話です。
まず、 KPOP全体 について、 グローバル全体に対して 特徴的となっていることに
- love
- sorry
の3つが上位に来ています。
確かに少ない知識でもKPOPのどの曲もloveについて喋っている気はしているのでloveはわかります。
sorryは失恋の文脈かもしれません。
homeは機械翻訳のミス
データを見るとhomeが3位に来ています。
homeはなんでしょうねえ。そういう歌詞が多いのかなと思い、ゼミでそのまま聞いてみましたが、ゼミの方々も分かりませんでした。
後述しますが、グループ単体でhomeが筆頭に上がるものは「BTS」「SEVENTEEN」「TWICE」でした。
そのうち、「BTS」「SEVENTEEN」はともに「home」という曲があり、そこで多く使われたんだろうなあという予想はできますが、TWICEはありません。
そこで、ちゃんとデータを確認したところ
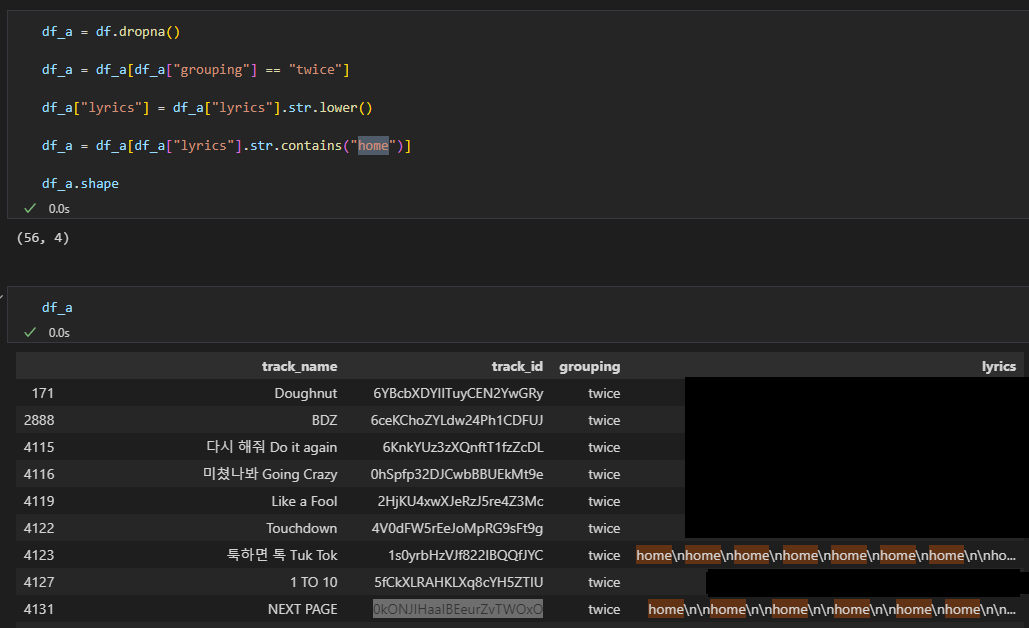
やけにhomeを連呼する歌詞が。
そういう歌詞かなと思って、 翻訳前 の歌詞データを見ると、なんと 韓国語の発音をカタカナ表記 しているものでした。
argostranslateが対応できず全部homeにしちゃったことが考えられます。
よって、 homeは気にしないでください
加えて
- home
- news
- chill
は同様に翻訳ミスが多く無視するべきです。
あまりスコープを広くしすぎても解釈が難しいだけなので、 アーティストグループごとに 見ていきます
KPOP業界に対して...
BTS
- 「love」「sorry」を特徴的としている。
恋愛と失恋が多いのですかね? - 「night」「universe」「world」などマクロ視点な自然描写が見られる
これは他のグループに見られなかった単語です。 - 「dream」「light」など「希望」を表す単語が見られる
以前のゼミでも、BTSは「俺たちはこんなに頑張って、みんなに応援してもらって、今がある」という表象が特徴的であることが取り扱われ、おそらくそのような文脈が読み取れるように思えます。 - 「girl」「best」「crazy」が他には見当たらない特徴度を示す
- 「girl」については、TWICEの「boy」と対照的で面白いですね。異性を語っているか、異性へ向けてメッセージを向けていることが考えられます。
SEVENTEEN
- こちらも「love」が有力
- 感嘆詞として?「baby」が多用されていることが伺える
- 作詞家の言葉遣いの傾向も
TF-IDFから読み取れますね。
- 作詞家の言葉遣いの傾向も
- 「happy」「dream」「smile」など、直接的にポジティブな表現が多く、ネガティブな表現は上位に見当たらない
- 「song」「music」という「曲そのもの」を表す単語が見られる
- どこかメタな視点から自分たちを語っている曲があるのでしょうかね。
TWICE
- こちらも「love」が有力
- 感嘆詞として?「baby」「honey」がかなり多用されていることが伺える
- 他にも「child」という、「幼さ」を示す単語が筆頭に現れる
childが検出されたTWICEの曲名は
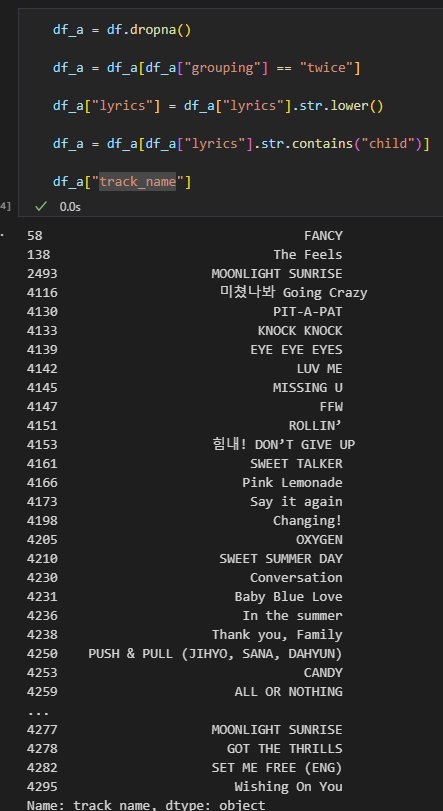
このとおりであり、無作為に3曲見てみると、2つが 「子供の頃~」のように過去の記憶を語る歌詞、1つが 「baby」が再翻訳の段階で「child」へ化けた ものでした。
- 「sweet」「eyes」「boy」が他には見当たらない特徴度を示す
- 「girl」が特徴的となるBTSとは性別的な対称性が見える
ITZY
- こちらも「love」が有力
- 「trust」「hot」がかなり強い
- 感嘆詞として「woo」が多用されている
- 「worry」「crazy」「shy」「bad」というような、精神的ネガティブさを表す単語が他グループより強く上がる
- 他3グループはいかにもハッピーな感じばかりでしたが、こちらは明確に 不穏な ワードが筆頭に上がりました。
トピックを見る
LDAのお話です。
結論から申し上げると、 失敗 しました;;
例えば、KPOP全体について、グローバルに対する人気トピック
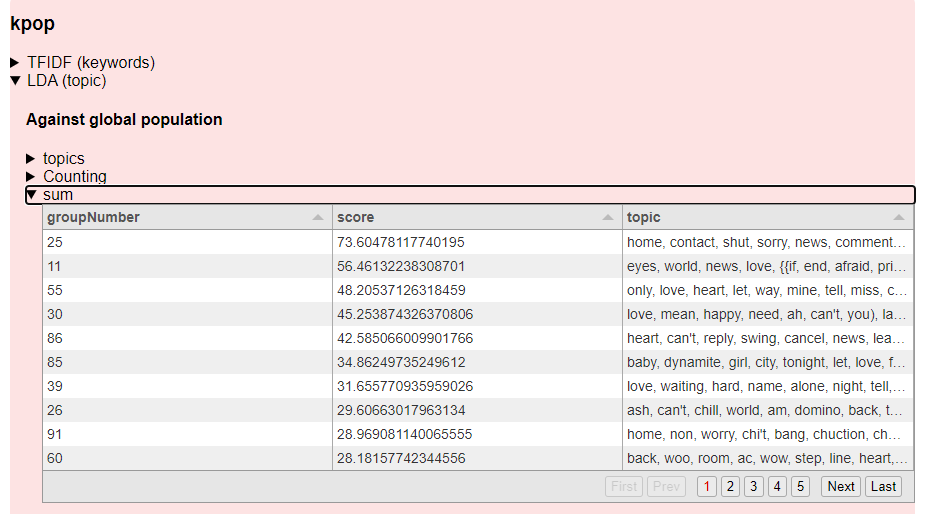
これを見ても、 それぞれのトピックが明確でなく、正直「このワードが人気なんだな」という上記TF-IDFと同じような情報しか得られませんでした。悲しい。
感情分析
NRCの感情ベクトルですね。
これは面白いです。
KPOP全体について
グローバル平均に対して
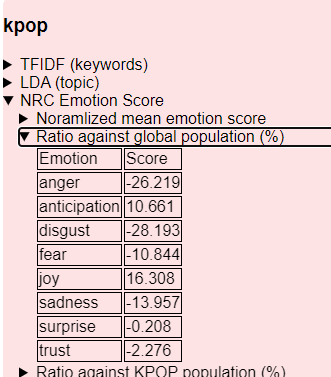
- 「怒り」「不快」「悲哀」が大幅に少なく、
- グローバルと比べてポジティブめ
であることがわかり、僕の「キラキラしてる~」という安易なイメージと合致しています。
また、
- 「anticipation = 予期」も高く、全体として「未来」を志向していることも読み取れるかもしれません。
anticipationの定義
anticipate は「期待」「不安」とポジティブ/ネガティブ双方に訳されることがありますが、プルチックの文脈では、 「驚き」の対極として位置づけ られています。
要するに、 「未来のことを考えている」というだけ の、けっこうニュートラルな感情として考えています。
KPOPに対して...
BTS

- 平均めではあるが...
- 「悲しみ」「恐怖」少し高め
- 「喜び」が少し低い
- 初期の反社会的な歌詞と最近のものが打ち消しあってる?
- 以前ゼミで扱った、初期のヒップホップ調の歌詞と、最近の清楚な歌詞のベクトルが打ち消しあっていことも考えられそう。
SEVENTEEN
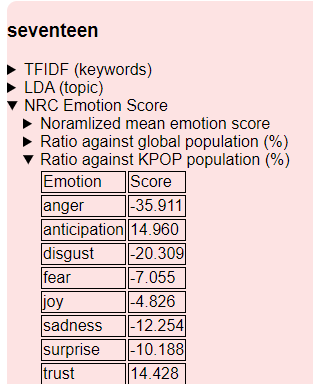
- 「怒り」「不快」が極めて低い
- 「信頼」「悲哀」も大幅に低い
- 「予期」「信頼」が高くなっている
「未来」の話に重点を置き、「(仲間・未来を)信じている」という文脈が考えられる?
TWICE
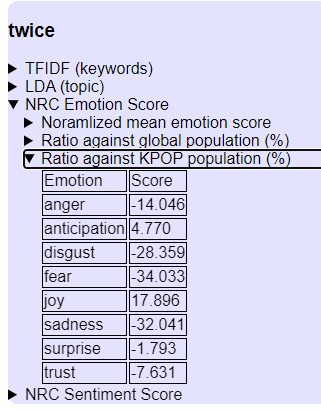
- 「恐怖」「不快」「悲哀」が極端に低く
- 「喜び」が大幅に高い
- あからさまにポジティブな歌詞
かなりハッピーなグループという安易なイメージがありますが、本当にそうなんでしょうね。
ITZY

- 「怒り」の比率がKPOP界の2倍ある
- 「悲哀」「不快」「恐怖」も大幅に高い
- 「喜び」は大幅に低い
けっこうアウトローな感じでびっくりしました。一番個性が出ているベクトルになっていますね。
筆者はITZYを全く知らないが(発表中に指摘されるまで読み方も知りませんでした)、けっこうダークな曲が書かれていることが想像しました。
angerが高い順に並べた上位10曲です。
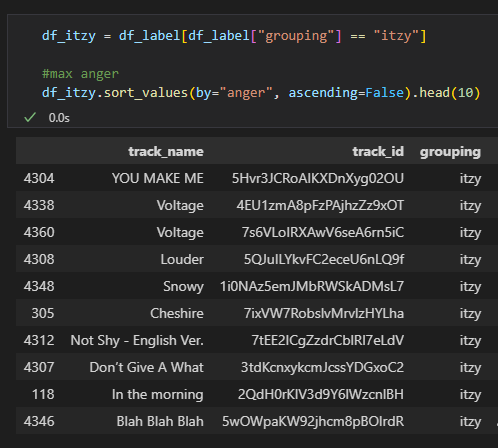
YOU MAKE MEは恋愛がらみでイライラしていそうな曲、
Voltageは単純に熱いパッションを強い言葉遣いでアピールしている曲ですね。
「ダーク」というよりも「パッションに溢れた」の方が適切かもしれません。
最後に
繰り返しになりますが、 テキストマイニングないしデータサイエンスは、分析よりも解釈が難しいです
読者の皆様は考察薄いな~と思われたかもしれませんが、 ドメイン知識がないと せいぜいデタラメ文脈のでっちあげしかできません。
なので、データサイエンスをやる場合、ただ分析技術のみならず、そのドメイン知識が一定以上必要になることがわかりますね。
あるいは、そちらの分野人の二人三脚で分析に取り掛かることもできますね。
そこで、 ドメイン知識がある人が何かつかめるように、分析結果を整理する ことが大事ではないでしょうか、ということを考えた取り組みでした。
いいね頂けると泣きながら喜びます><