はじめに
前回記事投稿した『OpenCVを用いてネコ検出器を作る』においてうまくいった例とうまくいかなかった例がいくつか出てきました。どうにかもっと精度あげられないかと調べているときにYOLOv3という手法を見つけて試しに行なってみました(要するに思っていた以上に精度が悪く悔しかったので...)。前回の記事でも記載した私が経験したハッカソンでもYOLOという単語は出ていましたが別タスクを私は任されたためYOLOには触れずにハッカソンが終わってしまったのでいい勉強になったので記事に書かせていただきます。
YOLOv3とは
YOLOとはYou Only Look Once(一度見るだけで)の略らしいです。面白いですね!NN(ニューラルネット)を一からモデルを構築しなくても、YOLOなら大丈夫でYOLOをダウンロードすれば構築ができているので通すだけでできました。また画像だけでなく、Webカメラなどとも連動できるので、リアルタイムの検出も可能ですので画像において色々な場面で活躍ができそうだと感じました。YOLOの公式サイト
実際にYOLOを使うとこのようなことができます。
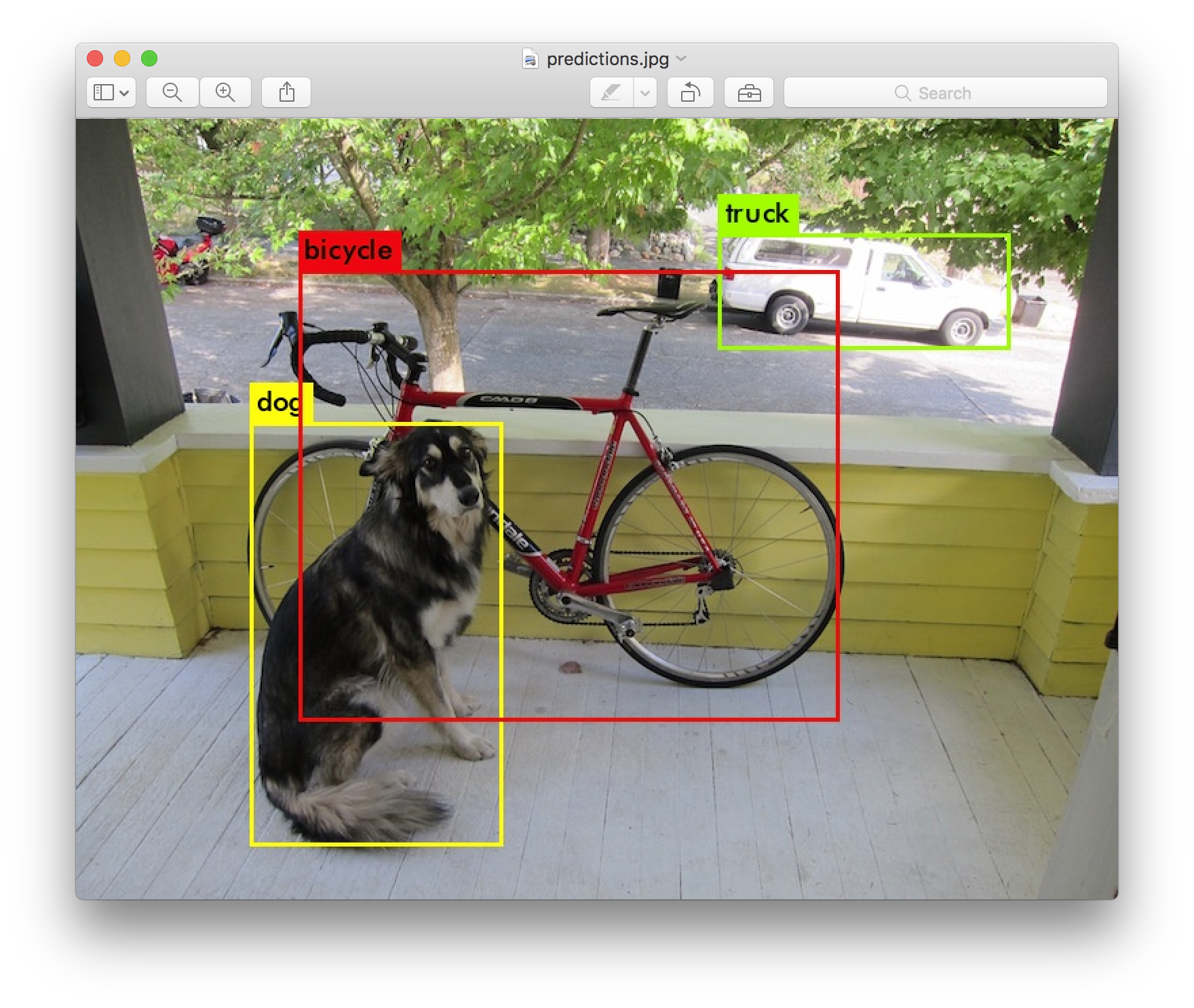
このように物体を検知して何かをラベリングすることが可能になっています。実際にネコ検出器でできなかった画像たちに試してみましょう!!
YOLOv3を使う
YOLOの導入にはこちらの記事を参考に行いました。(Macで物体検知アルゴリズムYOLO V3を動かす)
ターミナルを使います。
前提としanacondaを導入されているという状態で説明します。anacondaが導入されていないのであればまずは先に導入してください。
$ conda create -n yolo_v3 python=3.6 pip
$ source activate yolo_v3
これでPython仮想環境を作成できました。ここまで行うと
(yolo_v3) $
となると思います。
次に必要なパッケージをそのままインストールしていきます。
(yolo_v3) $ conda install pandas opencv
(yolo_v3) $ conda install pytorch torchvision -c pytorch
(yolo_v3) $ pip install matplotlib cython
上記の参考記事ではエラーがmatplotlibをインストールするときにエラーが出ると書かれていましたがエラーは私の場合はmacですが特にエラーは出なかったと思います。
ここまで終了したら'cd'で今回作業したいフォルダまで下がりgit cloneで次のファイルをインポートします。
新しいコマンドを立ち上げて下をコピペしてください。
$ git clone https://github.com/ayooshkathuria/pytorch-yolo-v3.git
また先ほどの(yolo_v3)となっている端末に戻り
(yolo_v3) $ cd ~~/pytorch-yolo-v3
(yolo_v3) $ wget https://pjreddie.com/media/files/yolov3.weights
~~/pytorch-yolo-v3は個々人該当のディレクトリで行なってください。
wgetを行うとモデルの構築が自動で行われます。少し待つとYOLOv3が使える状態になりました。
実際に試してみた
試す時も先ほどのコマンドプロンプトを用います。実行自体は下で示したコマンドでできますが、試したい画像をimagesというファイルに入れる必要があります。忘れずに入れてから実行してください。あたgithubをcloneしたときに何枚かサンプル画像はありましたのでそちらを試すでも良いと思います。
(yolo_v3) $ python detect.py --images imgs --det det
エラーが出た・・
私の場合は下のようなエラーが出てしまったのでまたまた調べて対処を見つけました。pytorch-yolo-v3のRuntimeErrorを解消できたよ
Traceback (most recent call last):
File "detect.py", line 234, in
output = torch.cat((output,prediction))
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 8 and 86 in dimension 1 at d:\build\pytorch\pytorch-1.0.1\aten\src\th\generic\thtensormoremath.cpp:1307
どうも"pytorch-yolo-v3/util.py"というファイルを消去し新たに下のリンクのutil.pyに差し替えることで動きました。
こちらのリンク
このutil.pyをPCに保存する方法は
1. リンクを開く
2. Rawを右クリック
3. リンク先を別名を保存をクリック(名前は変えずにutil.pyにしました)
4. "pytorch-yolo-v3/util.py"となるようにペーストする
結果
デフォルトであった画像で結果をまずは試してみました。


画像に写っているhorseをラベル化できています!スゴイですね笑
続いて


信号機(traffic light)だったりcar,truckなど識別ができています。
実際にうまくいかなかった画像で試してみた


前回は斜めを向いていて反応してくれなかったのですが今回はcatとラベリングしてくれました!!


前回はネコ3匹のうち1匹のみ検出できていましたがネコ3匹全て検出ができしかもcarまで検出ができていてとても良い精度だなと感じました。
それでもうまくいかなかった例
※検出した最終の結果のみ載せます。

"dog"と誤認識していました。。まぁ見えるけど。。。という感じですね。(写真が悪いかもですが・・・)

"bird"と誤認識していました。。遠いからですね、なるほど。
考察
写真が悪いものは誤認識されていますが、認識はとても精度がいいなと思いました。またYOLOはよく話で聞いていたのでやってみて精度がいいなと思いました。ネコ以外に渋谷ハロウィンのとても混み合っているニュースの写真で試してみてどれくらい遠い距離にいたり一部分のみしか写っていない写真でも精度は意外と良い印象を受けました。
考察ではないが、またハッカソンで吸収できなかったYOLOに関して結構調べて自分自身で結構吸収できたことがとてもよかったなぁと思った。
ハッカソンで扱った3つのモデルである顔認証・全身認証・歩容認証(骨格認証)のうち前回の記事で扱ったOpenCVでの顔認証・そして今回扱ったYOLOv3での全身認証がクリアしました。
次は骨格認証で使ったOpenPose・HumanPoseなどについて調べて実装してみて記事を書きたいなと思います!また研究室の人だったりフォローしていただいている方から機械学習で使う基本的な数学について記事欲しいと要望があったのでいつか(多分年末までに?)数学について書こうと思います!何について書こうかな・・・?まだ決めてませんがw
ここまで読んでいただきありがとうございました。
もしよければフォロー・LGTMよろしくお願いいたします。
参考
YOLOとかOpenCVとかで物体検知
Macで物体検知アルゴリズムYOLO V3を動かす
pytorch-yolo-v3のRuntimeErrorを解消できたよ
pytorch-yolo-v3