はじめに
この記事は私がある企業が主催した画像系のハッカソンに参加した時に使ったスクレイピングという技術をanacondaなど環境導入せずにPythonが動かせるGoogle Colaboratory(GC)で使えるように書き換えた記事です。記録として残したいのでQiitaに投稿しました。また近日中にこのハッカソンで勉強したことを元にOpenCVを用いたネコ検出器を作成しました。このネコ検出器の検出器のコードについては後日投稿予定です。この記事と投稿予定の2部構成ですので承知おきください。(20201214-2)
また以前投稿した自然言語処理を用いたデータの分類こちらも是非みて勉強していただければと思います!!(画像ではなく申し訳ございません。。)
背景
画像のAIを構築する時に、学習に必要な画像が精度を向上させるためには相当数画像が必要になります。自力で用意することは難しいという時にいくつか方法があります。代表的な方法として、OpenCVの関数に、画像のかさ増しする関数がありそちらを使うことも可能です。また「スクレイピング」という技術もよく使われています。今回は後者の「スクレイピング」を用いた画像AIを構築したので「スクレイピング」について重点的に取り上げたいと思います。
「スクレイピング」とは
「スクレイピング(scraping)」とは、Web上にあるデータで必要なデータを「検索」して取得してデータベースとして新たに格納したり記憶したりすることができる技術でデータ活用の前準備にかかる手間・時間は大幅に省略することができる技術です。(データ収集を大幅に効率化する「スクレイピング」とは? 手法やルール・注意点を解説!)
「Google Colaboratory」とは
Pythonを使うときはAnacondaをインストールしたりしないといけなく何かと時間がかかります。そのような時にGoogleから提供されているGoogleドライブ上で扱うことができるGoogle Colabratoryを使うことができとても便利です。またGCPに切り替えてGCPを使うこともできるのでとても機械学習を行いたい初学者にとってサクッと扱えるとても良いツールだと思いますのでぜひ使ってみてください!!
アイコンは下ようなアイコンです。

どう使うの??
※Googleアカウントが必要です!持っていない方は先に作りましょう。
1)Googleドライブにアクセスする
2)右クリックを押し「その他」をクリック
3)Google Colaboratryをクリックしたら立ち上がります。

立ち上がったら実際にコードを打っていく準備が整いました。
FlickrAPIを用いる
FlickrAPIを用いて今回は画像を取得してきます。FlickrAPIとはwebから該当の検索ワードとマッチしたデータを見つけることができるためとても便利なサイトです。使うためには最初にアカウント登録をする必要があります。アカウントにはmailアドレスとパスワードが必要です。
(flickr.com)
- アカウント登録できたらログインする。
- 「You」をクリック
- 一番下の「Developers」をクリックする(ない方はこちらからクリックで飛べます)
- 「API」をクリック
- 「Request an API key」をクリックする(こちらからでもokです)
1~5まで順にいくと上のような画面になると思います。
そしたら「Request an API Key」を押します。
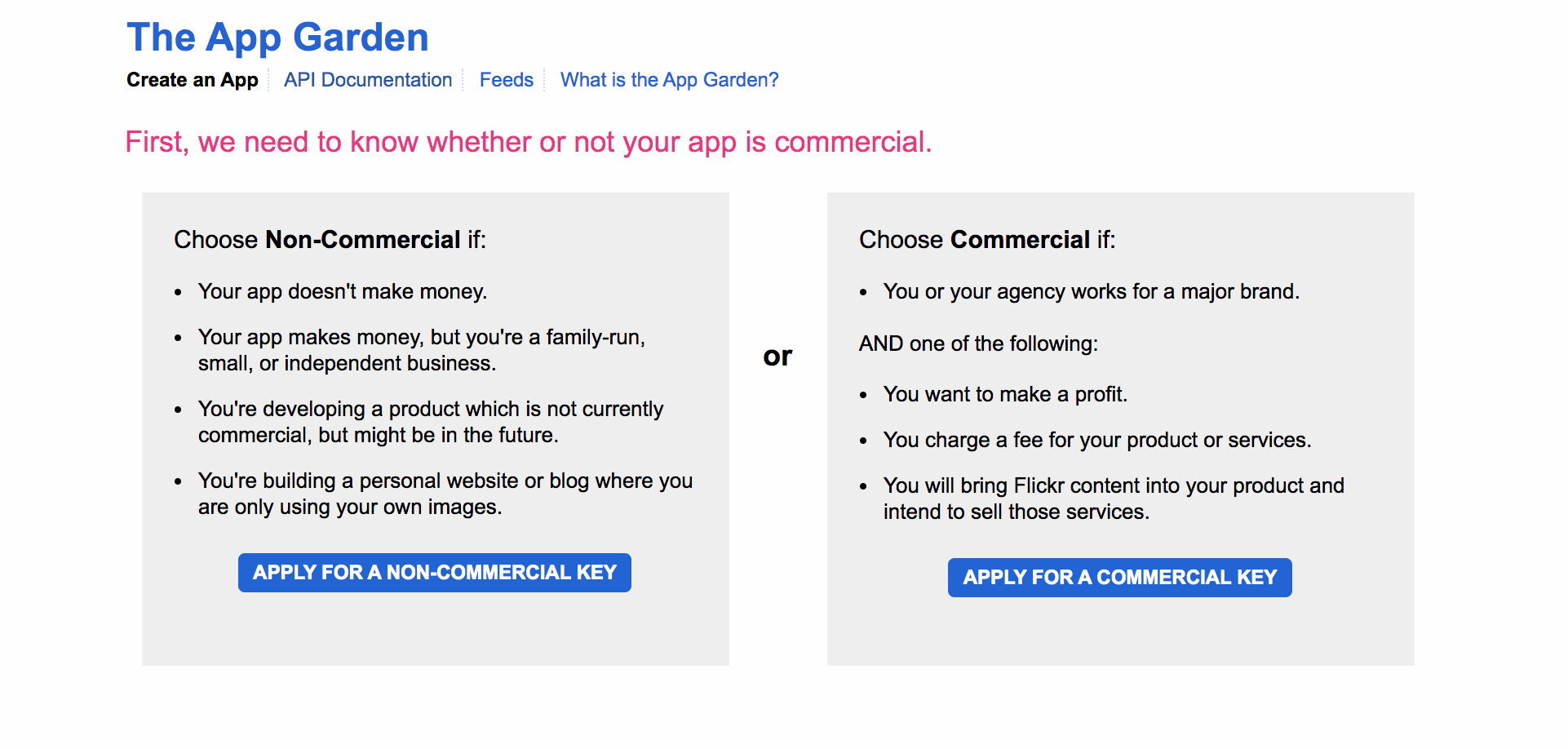
このような画面になると思います。こちらには簡単に略すと「商用/非商用どちらですか?」と聞かれています。非商用で今回は扱うため左側をクリックします。
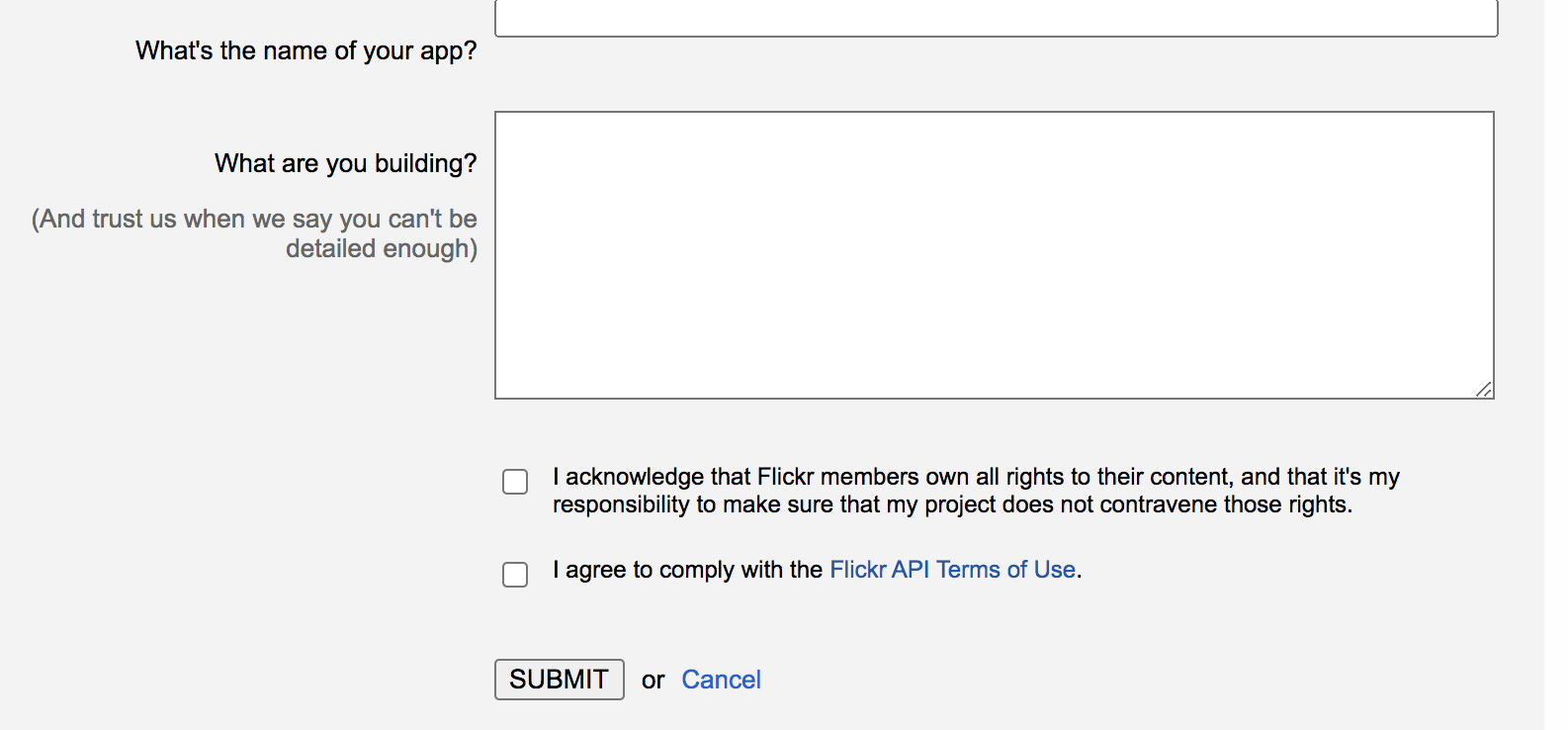
次にこのような画面に遷移すると思います。こちらではアプリの名前とどんなアプリか聞かれています。記入して下のチェックボックスにチェックを入れてSUBMITをクリックします。
次の画面で英語と数字で羅列された文字列が出てきたと思います。こちらが今回必要ですのでコピーしてメモ帳等に貼り付けておいてください。
上の文字列がAPI Keyで下の文字列がSecret Keyと呼びます。
この2種類を取得できたらいよいよコードを書いていきましょう!!
Google Colaboratoryで画像を取得してみる
- 必要なライブラリをインストールする
今回使うモジュールは以下になります。
# 必要なライブラリのインポート
import os, time, sys, math
from flickrapi import FlickrAPI
from urllib.request import urlretrieve
Pythonの経験がある方はこの作業は飛ばして大丈夫だと思います。おそらくですがFlickrAPIでエラーが出ると思います。エラーが出たら!pip installで入れなおしてください。
!pip install FlickrAPI
初めて扱う方は「おまじない」くらいでコピペで大丈夫です。FlickrAPI以外でエラーがでた場合は同じように!pip install モジュール名(importの次の単語)で入れ直してエラーが出なくなれば大丈夫です。
- APIキーの記述
先ほどメモ帳にコピーしたAPIを書きます。
key = "XXXXXXXXXXXXXXXXXXXXXX"
secret = "XXXXXXXXXXXXXXXXXXX"
wait_time = 1 # 待ち時間(1秒おきにDLを行う)
参考文献にwait_timeが1秒おきで行うと安定すると書いてあったので1で設定しています。
- 検索で欲しいワードを
classesに記載,par_pageで何枚画像を取得するかを指定する。
# ダウンロードしたい名前をclassesに記述
classes = ["cat"] #ここは日本語でも可能
per_page = 600 #600枚取得する
classesには何個入れても構いません。例えばネコ科で検索したいといった場合は
classes = ["cat", "ねこ",とら,ライオン,チーター,ジャガー]のように,で区切って格納しましょう。何個入れても構いませんがそのぶん多少時間がかかると認識しておいてください。
4)取得画像の保存方法の設定
こちらはそのまま使用で大丈夫かと思います。保存場所の変更したい方は適宜変更してみてください。
# 枚数によって場合分け
if per_page < 1000:
per_page = per_page
n_page = 1
else:
n_page = math.floor(per_page/1000) + 1
per_page = math.floor(per_page / n_page)
nb_photo = len(classes)
os.mkdir("./images")
%cd ./images
# 保存フォルダの作成:
for i in range(nb_photo):
dir_name = classes[i]
# 指定した名前のフォルダを作成する
dirpath = "./" + dir_name
os.mkdir(dirpath)
flickr = FlickrAPI(key, secret, format="parsed-json")
for i in range(n_page):
response = flickr.photos.search(
text = dir_name,
per_page = per_page,
page = i + 1,
media = "photos",
sort = "relevance", # 関連純
safe_search = 1,
extras = "url_q, licence"
)
photos = response["photos"] #
for i, photo in enumerate(photos["photo"]):
try:
url_q = photo["url_q"]
filepath = dirpath + "/" + photo["id"] + ".jpg"
if os.path.exists(filepath): continue
urlretrieve(url_q, filepath)
time.sleep(wait_time)
except:
continue
このプログラムではimagesというフォルダを作りそちらに取得した猫の画像を格納していくプログラムになっています。また1フォルダに全画像を入れるのでなく1000枚で1フォルダで1000枚以上の時は複数フォルダに入れて分割してフォルダに入れていくプログラムになっています。
また初学者はこのプログラム部分はあまり変更はいらないかと思います。何を行なっているかくらいは押さえると良いかと思います。
5)できたファイルを圧縮
# ファイルの圧縮
%cd ../
!zip -r images.zip images
zipファイルにしてできたファイルを圧縮します。
ここまでできるとGoogle Colaboratoryの左の部分のファイルを押すとimagesというフォルダが出来上がっていると思います。フォルダの中をみると検索してマッチした「ネコ」の画像が含まれていることが確認できると思います。私のPCではこのような画像になりました。合わせて参照していただければと思います。
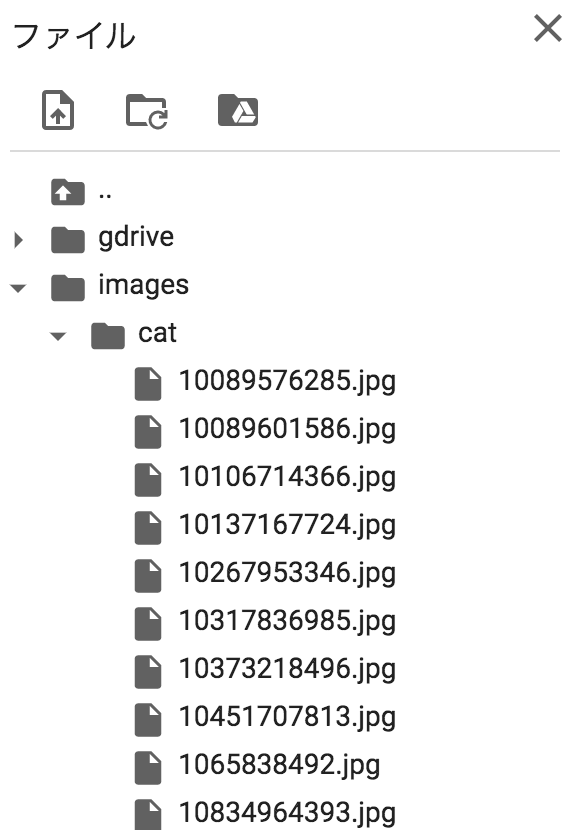

無事可愛らしいネコが取得できました。🐈
6)フォルダをzipファイルでダウンロードする
# imagesフォルダのダウンロード
import google.colab
google.colab.files.download("images.zip")
これでスクレイピングした画像ファイルを取得することができました。
この画像を用いて次はOpenCVを用いてネコ検出器を作りたいと思います。近日中に記事をuploadする予定ですので今しばらくお待ちくださいm(_ _)m
下記通しのコードをおいておきます。
# 必要なライブラリのインポート
import os, time, sys, math
from flickrapi import FlickrAPI
from urllib.request import urlretrieve
# APIキーの情報
key = "XXXXXXXXXXXXXXXXXXXXXX"
secret = "XXXXXXXXXXXXXXXXXXX"
wait_time = 1 # 待ち時間(1秒おきにDLを行う)
# --------- INPUT -------------------------------------------
# ダウンロードしたい名前をclassesに記述
classes = ["cat"] #日本語でも可能
# DLしたい枚数
per_page = 600
# -----------------------------------------------------------
# 枚数によって場合分け
if per_page < 1000:
per_page = per_page
n_page = 1
else:
n_page = math.floor(per_page/1000) + 1
per_page = math.floor(per_page / n_page)
nb_photo = len(classes)
os.mkdir("./images")
%cd ./images
# 保存フォルダの作成:
for i in range(nb_photo):
dir_name = classes[i]
# 指定した名前のフォルダを作成する
dirpath = "./" + dir_name
os.mkdir(dirpath)
flickr = FlickrAPI(key, secret, format="parsed-json")
for i in range(n_page):
response = flickr.photos.search(
text = dir_name,
per_page = per_page,
page = i + 1,
media = "photos",
sort = "relevance", # 関連純
safe_search = 1,
extras = "url_q, licence"
)
photos = response["photos"] #
for i, photo in enumerate(photos["photo"]):
try:
url_q = photo["url_q"]
filepath = dirpath + "/" + photo["id"] + ".jpg"
if os.path.exists(filepath): continue
urlretrieve(url_q, filepath)
time.sleep(wait_time)
except:
continue
# ファイルの圧縮
%cd ../
!zip -r images.zip images
# imagesフォルダのダウンロード
import google.colab
google.colab.files.download("images.zip")
参考になれたらと思います。
ここまで読んでいただきありがとうございます。よかったらフォロー・LGTMよろしくお願いいたします。
また質問やご指摘よろしくお願いいたします。まだまだ勉強中ですのでとても助かります。
参考
データ収集を大幅に効率化する「スクレイピング」とは? 手法やルール・注意点を解説!
python&FlickrAPIを使ってwebサイトの画像を収集する方法