はじめに
自然言語処理の記事を久しぶりに書こうと思います。
今回はWord2vecをwikipediaから.xmlファイルを取ってきて分かち書きを行い類似するワードを抽出したり応用して感情分析を行ったりをしてみました。また今回から機械学習用にUSBを購入しディレクトリをそちらに作成し行うということを行いました。外部ディスクに繋げてjupyter notebookを立ち上げるやり方も記録として残そうと思ってます!
今回参考にした記事は【Python】Word2Vecの使い方を参考にしました。
以前まで用いていたGoogle Colaboratoryでもできるように後日updateしようと思いますがまず先にlocalでのやり方について触れようと思います!
word2vecとは?
自然言語を少し触れたことあるとよくきくワードだと思いますが、word2vecとは単語をベクトル表現に変化させることを言います。またこのベクトル化した表現のことを分散表現と言ったりもします。
基本的には、「同じような意味や使われ方をする単語は同じような文脈の中に登場する」という考えのもと、単語をベクトル化しています。このため、同じような意味や使われ方をする単語同士はベクトル空間上で近い場所に存在、つまりコサイン類似度が高くなります。
コサイン類似度に関しては後で記事に書きたいコンテンツの一つと思っているので簡単に説明すると、ベクトルを考えた時にベクトルの大きさや重みを重視してより類似するかどうかのみにフォーカスを当てた測定方法がコサイン類似度と呼ばれています。大きさや重みを重視する測定方法は高校数学でおなじみのユークリッド距離になります。自然言語処理ではベクトルの長さはあまり関係がなくそれよりも単語が似ている単語なのかに関心があるためコサイン類似度を採用するケースが多いです。
Word2Vecは意味についてで考えることができるため単語の意味での足し算や引き算ができることが面白いと思う点です。例えば
- 「王様」ー「男性」+「女性」=「お姫様」
- 「日本」ー「東京」+「ソウル」=「韓国」
このように「王様」から「男性」要素を抜き「女性」要素を加えると「お姫様」や「女王」になると言ったようなことができることが面白いなと思います。
実際にやってみた
USBに適当にディレクトリを作成する
今回Word2Vecでファイルを作ったりコードを動かしたりしたい場所のフォルダを新規作成します。このフォルダにターミナルからアクセスする必要があります。
$ cd /Volumes/~USBや外付けハードの名前~
このように/Volumes/~~で指定することができます。簡単ですね!!これの汎用性としてとても重いデータを用いて学習させたりしたい時に外付けハードで行うことでPC本体を圧迫を回避しつつ学習させることができるためとてもいいなと思っています。
必要なデータのダウンロード(コーパスを用意する)
まずは、モデル作成に必要なコーパスを用意する必要があります。
今回は参考記事の通りに誰でも入手可能なWikipediaのデータを使用します。
日本語のWikipediaのデータはダンプ化されたものが用意されています。
https://dumps.wikimedia.org/jawiki/latest/
このサイトを見るとwikipediaのタイトルのみを集めたり、種類で集めたデータがあったりと用途によって変更することができるようになっています。
今回はWikipediaの記事本文が欲しいので、
$ curl https://dumps.wikimedia.org/jawiki/latest/jawiki-latest-pages-articles.xml.bz2 -o jawiki-latest-pages-articles.xml.bz2
こちらの.bz2というファイルは3G程度ありとても重いデータとなっているので私は外付けハードを用いたという経緯です。
落とすことができたらそのファイルをクリックすることで解凍することができます。解凍にも時間が結構かかりました。
仮想環境を作成
前回も出てきましたが仮想環境を作成しました。wikiという仮想環境でこれ以降行います。コマンドをうちうまくいくと(wiki) $といった感じでターミナルが変化すると思います。
$ conda create -n wiki python=3.7
$ conda activate wiki
WikiExtractorのインストールと実行。
以下のコマンドを打ちます。
$ pip install wikiextractor
$ python -m wikiextractor.WikiExtractor jawiki-latest-pages-articles.xml
このコマンドを打つと
textというフォルダが作成されてその中に「AA, AB, ...」フォルダが生成され、その下にテキストファイル「wiki_00〜wiki_99」が生成されます。(割と時間がかかりました。)
以下のコマンドで、テキストファイルを wiki.txt にまとめる。
上が終わったらまとめるコマンドを打ちます。
$ find text/ | grep wiki | awk '{system("cat "$0" >> wiki.txt")}'
wiki.txtは私の手元では3.6Gになりました。(大きなファイルですね。。wikiがどれほど大きなデータなのかがわかるかと思います。)
以下のコマンドで、docタグと空行を削除。(データ整形)
$ sed -i '' '/^<[^>]*>$/d' wiki.txt
$ sed -i '' '/^$/d' wiki.txt
データの先頭100行をターミナルで確認すればわかるのですが空白行やdocタグなどがあり削除してデータ整形を行いました。(参考資料には載っていないですが必要な気がしたので色々調べて行いました。)
$ head -n100 wiki.txt
このようにコマンドを打つことで先頭100行を出力して確認することができます!
wiki.txtの行数と文字数を確認する
興味があったので調べてコマンドを見つけました。(私の手元では確か1400万行,10億文字程度でした・・・)
$ wc -ml wiki.txt
これでモデル作成前の準備が終了しました。
モデル作成
gensimというライブラリを用いました。
$ pip install --upgrade gensim
gensimを使うために分かち書きが必要らしくMeCabを使ってわかち書きを施しました。以前の記事でもMeCabを使ったのでインストールのパートは割愛させていただきます。上記リンクよりインストールできます!
$ mecab -Owakati wiki.txt -o wiki_wakati.txt
わかち書きするのにもとても時間がかかりました。そしてwiki_wakati.txtと名付けましたがそのデータもとても重いデータです。。。
また今後の解析に支障がきたすためバイナリデータをutf-8に変換しました。以下のコードでできます。
$ nkf -w --overwrite wiki_wakati.txt
ここまでがターミナルで行うパードです。これからJupyter Notebookを使用していきます。Juppyter Notebookも外付けハード上で動かせることができました。本当に便利だなと思います!!
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus('./wiki_wakati.txt')
model = word2vec.Word2Vec(sentences, size=200, min_count=20, window=15,iter=3)
model.wv.save_word2vec_format("./wiki.vec.pt", binary=True)from gensim.models
wuki.vsc.ptというファイルに出力結果が格納れていきます。
活用事例
参考資料に載っていたプログラムを行なってみました。
from gensim.models import KeyedVectors
wv = KeyedVectors.load_word2vec_format('./wiki.vec.pt', binary=True)
results = wv.most_similar(positive=['講義'])
for result in results:
print(result)
このプログラムは'講義'に似た意味の単語を出力してくれるコードになっています。この'講義'の所に調べたいワードを組み込むことで調べることができました。私は趣味でHIPHOPが好きなためHIPHOPアーティストである「ZEEBRA」をキーワードに入れてみた結果
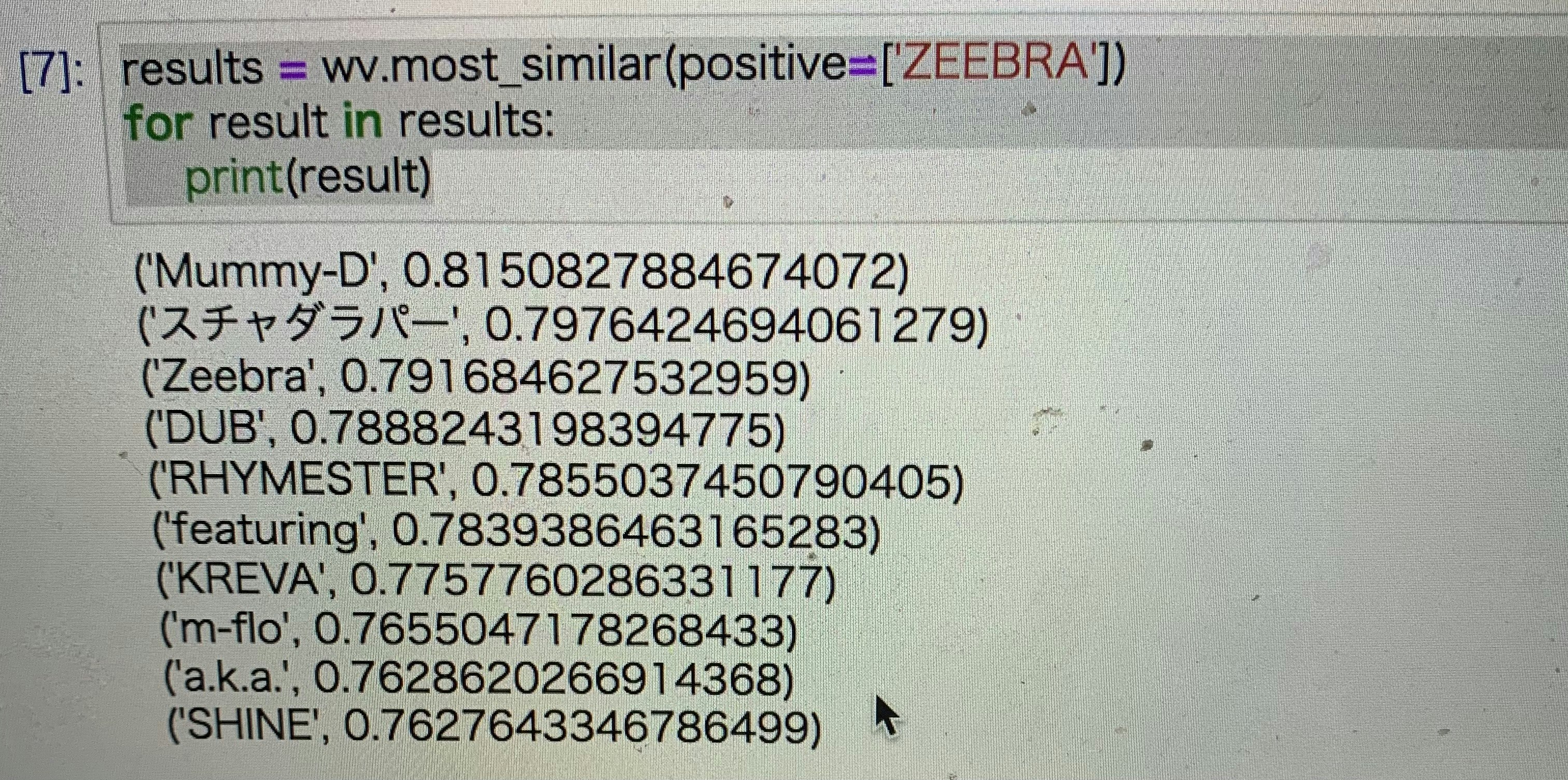
'Mummy-D'や'KREVA'など並んで実行結果が面白いなと思いましたww(伝わらない方はすみません・・)
またこの記事書いた日が12/24のため・・・
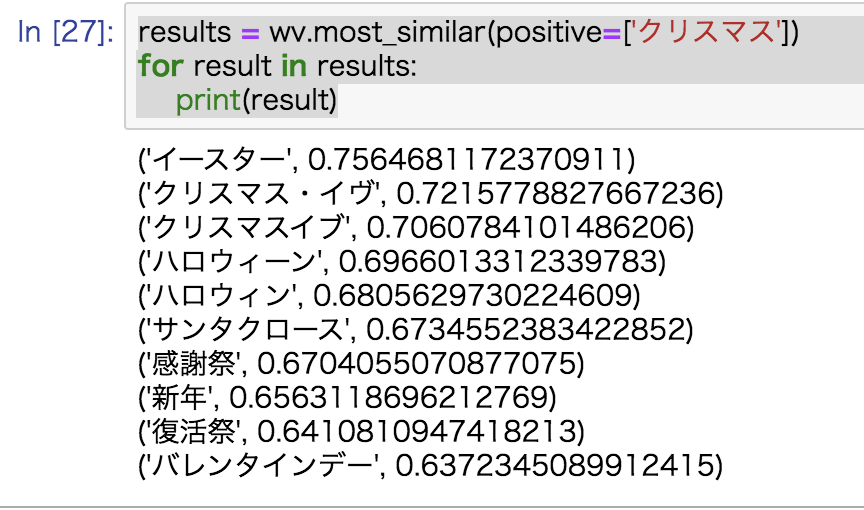
クリスマスだけでなく、ハロウィン・バレンタインデーなど並びましたw
ぜひ試してみてください!!
言葉の意味の足し算引き算やってみた
先ほど出した例の2つを行なった結果を下に載せます。
sim_do = wv.most_similar(positive = ["王様", "女性"], negative=["男性"], topn=5)
print(*[" ".join([v, str("{:.5f}".format(s))]) for v, s in sim_do], sep="\n")


このように出力することができました。
Word2Vecを使ってみてこのように一般的な言葉に対しては精度よく認識することができることがわかりました。例えば「ZEEBRA」は有名な方なので出てきましたがもっとアンダーグラウンドで活躍しているラッパーだったりアニメのキャラクターだったりといったマイナー(?)専門的(?)な固有名詞を使いたいときはWord2Vecに新規登録として辞書を追加することでできるそうです!いつかまた行なってみようと思います。
ここまで読んでいただきありがとうございます。
もしよければフォロー・LGTMよろしくお願いいたします!!また勉強している立場なので間違いやアドバイスなどご指摘よろしくお願いいたします。とてもためになります。
もし時間が許せるなら、他の記事も読んでみてください!!