はじめに
みなさんはじめまして、@kon2です。

この記事は機械学習の自動化プラットフォームDataRobotを使って楽しむ冬のイベント予測チャレンジ 【PR】 DataRobot Advent Calendar 2020の投稿記事です。
お題は「冬ならではのテーマで機械学習モデルを試そう」となります。
DataRobotならめちゃくちゃ簡単に機械学習が試せます、おすすめです!
冬と言えば……?
突然ですが、みなさんは冬と言えば何を思い出しますでしょうか。
クリスマス、お正月、初詣...??
確かにそうですね。でも大学生にはもっと大事なイベントがあります。
そう、卒論発表の時期です!!
いまとなっては懐かしい、私がまだ大学院の学生だった頃の話です。
私は卒論制作のため、顕微鏡の画像から粒子を数え上げる作業をしていました。

(画像はイメージです)
イメージ画像のように互いの粒子は重なり合っており、画像処理で粒子の個数を自動的に数え上げることは困難です。
そのため、私は粒子の数え上げを全て手作業で行いました。
しかも100枚以上の画像に対して!
めちゃくちゃ大変でした。
今考えれば、こんなのはヒトがやる作業じゃないですよね。
というわけで、AI(機械学習)に任せましょう!!!
機械学習のジレンマ
しかし、機械学習を使おうとすると、下のような問題にぶち当たります。
- データセットをそろえるのが大変
- モデルの選定 & ハイパーパラメータの調整が面倒
画像を用いた機械学習では少なくとも数百~数千以上の教師データが必要となり、結局、膨大な手作業が発生します。
AIを使って楽がしたいのに、結局は手作業で数え上げた方が楽なのでは……?
(とりあえず卒論を乗り切ればいいわけだし)
これではいけませんね。何とか解決していきましょう。
問題1の解決策:類似画像の自動生成
問題1を解決するために、例えば顕微鏡像に類似した画像を自動的に生成し、それを教師データとして用いるというアプローチがあります。
例えば下の論文では、3DCGソフトウェアのBlenderを使って走査型電子顕微鏡像に類似した画像を大量に生成して用いることを提案しています。
Image from DeCost, Brian L., and Elizabeth A. Holm. "A large dataset of synthetic SEM images of powder materials and their ground truth 3D structures." Data in brief 9 (2016): 727-731.
今回はより単純に、以下のような二値化画像を大量に自動生成して教師画像として用いることにしました。
(どんな画像かにもよりますが、顕微鏡像から下のような2値化画像を得るまでは比較的容易にできます)

ちなみにこの画像内には粒子が54個存在しますが、目視は当然のこと、画像処理でもこれを数え上げることは困難です。
問題2の解決策:AutoML(DataRobot)を使う
AutoMLとは自動化された機械学習(Automated Machine Learning)の略です。
その名の通り、機械学習を行う際に時間のかかるデータの前処理、学習モデルの設計、最適化を自動化するための手法です。これを使えばコードを一切書かずに一般的な機械学習手法を一通り試して、最も精度の高いモデルを探すことができます。
今回は、DataRobot社が提供する「DataRobot AI Platform」のトライアル版を使って、上記の二値化画像からの粒子数推定にチャレンジしてみます!
教師データの生成
教師データの自動生成にはPython(OpenCV)を使いました。サンプルコードを下に記します。
画像のサイズは128×128 px、粒子数は1 ~ 100、サイズは2 ~ 10 px としてランダムに描画しています。
また、同ディレクトリに、粒子数とその画像パスが入ったcsvファイルも出力されます。
import cv2
import numpy as np
import os
import random
import pandas as pd
# ------------------------------------------------
# create particle samples for machine learning
# ------------------------------------------------
# make dictionary for pandas
dic = {'Target':[],'Path':[]}
# make directory
os.makedirs('particles', exist_ok=True)
# parameters
samples = 1000
nuc_size = 118
ex_size = 128
diff = int((ex_size-nuc_size)/2)
for i in range(samples):
# randomize amount of nuclei
amo = np.random.randint(1,100)
img_gray = np.zeros((ex_size,ex_size))
img_th = np.zeros((ex_size,ex_size), dtype=np.uint8)
x = []
y = []
r = []
# create particle image
for j in range(int(amo)):
cx = np.random.randint(diff,diff+nuc_size-1)
cy = np.random.randint(diff,diff+nuc_size-1)
cr = np.random.randint(2,10)
x.append(cx)
y.append(cy)
r.append(cr)
if(int(cr) > 0):
img_gray = cv2.circle(img_gray, (cx, cy), int(cr), (1,1,1), -1)
img_th = cv2.circle(img_th, (cx, cy), int(cr), (255,255,255), -1)
# save image
cv2.imwrite('./particles/p'+str(i).zfill(4)+'.png', img_gray*255)
dic['Path'].append('p'+str(i).zfill(4)+'.png')
dic['Target'].append(amo)
# create csv
df = pd.DataFrame.from_dict(dic)
df.to_csv('./particles/all_data.csv', index=False)
また、このコードで生成された画像のサンプルを下に示します。
今回は試しに1000枚の教師画像を生成してみました。

上のコードを実行すると、同一ディレクトリの*/particle*というフォルダにすべての画像と、csvファイルが出力されます。
このファイルをzipに圧縮すれば、教師データの準備は完了です。簡単ですね!
DataRobotによる予測モデル作成
教師データが準備できたので、DataRobotによるモデル作成に移っていきましょう。
トライアル版の申し込みは以下のページを参考にしてください!!
【DataRobot】DataRobot AI Platformのトライアル申し込みから予測させるまで
データのアップロード
トライアル版の申し込みが終わったら、メインページ左上のメニューから「機械学習の開発」を選択します。

すると次のようなページに移動するので、ローカルファイルと書かれたボタンをクリックします。
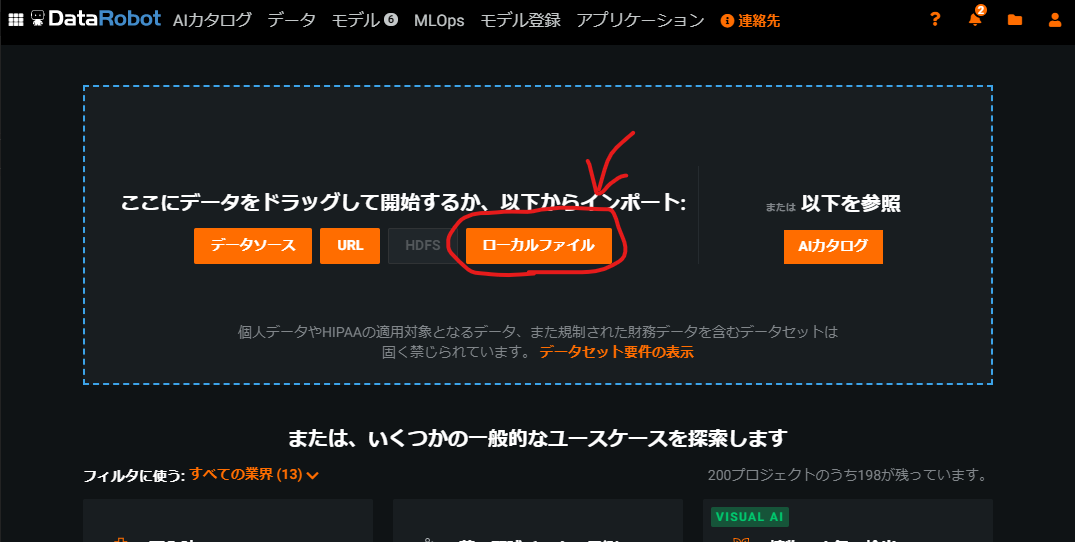
ここで先ほど作成したzipファイル(particle.zip)を選択することで、教師データがアップロードできます。
データの確認
データの読込が終わると、次のような画面に移ります。
いきなり「何を予測しますか?」と聞かれても……と思うかもしれません。
ここでは、入力したcsvファイルの中で予測したい変数の列名を入力します。
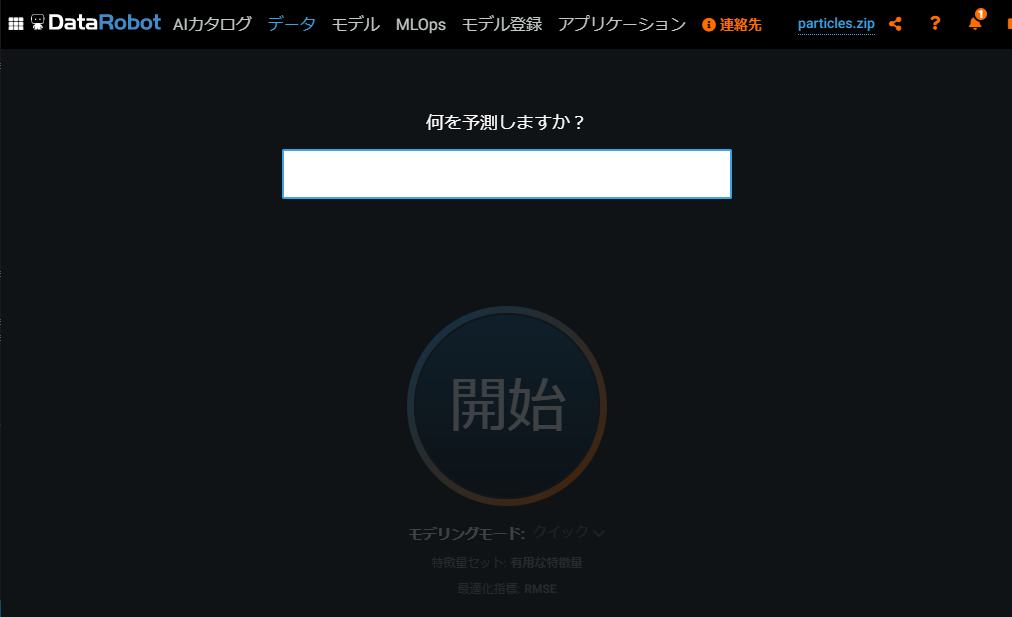
今回予測するパラメータはcsvファイルの"Target"という名前で入っているので、これを打ち込みましょう。
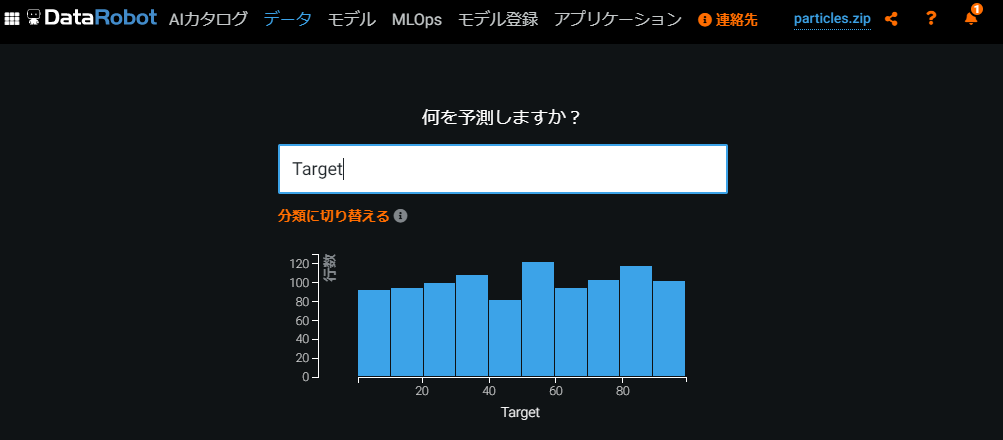
するとこのように、列名"Target"の値がヒストグラムとして表示されます。
狙い通り、1~100の間でランダムに分布していることが分かりますね。
また、下にスクロールしていくと、csvファイルに記入されたすべての値を確認することができます。
例えば"Path"をクリックすると、下のように対応した画像データを確認することもできます。
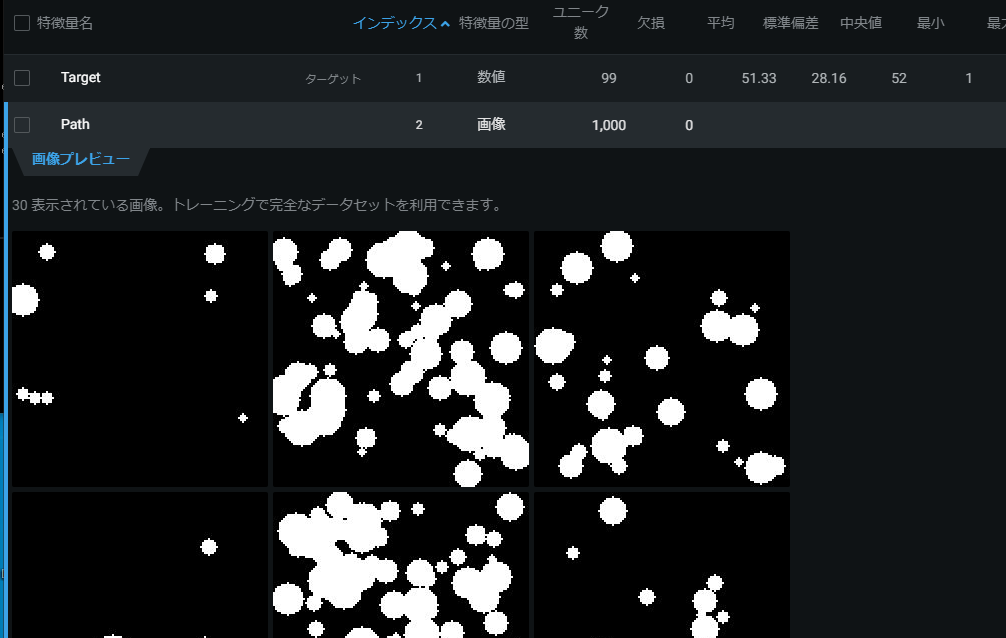
モデリングの実行
データの確認が終わったら、開始ボタンを押せばモデリングが行われます。
環境にもよると思いますが、自分はだいたい~10分ぐらいで終わりました。
色んなモデルの調整・検証を自動でやってくれるので、信じられないほどに楽です。
ちなみに進行状況は右側のタブで分かるようになっています。
予測モデルの確認
学習が終わったら、上部の「モデル」タブをクリックすることで作成した予測モデルを確認することができます。
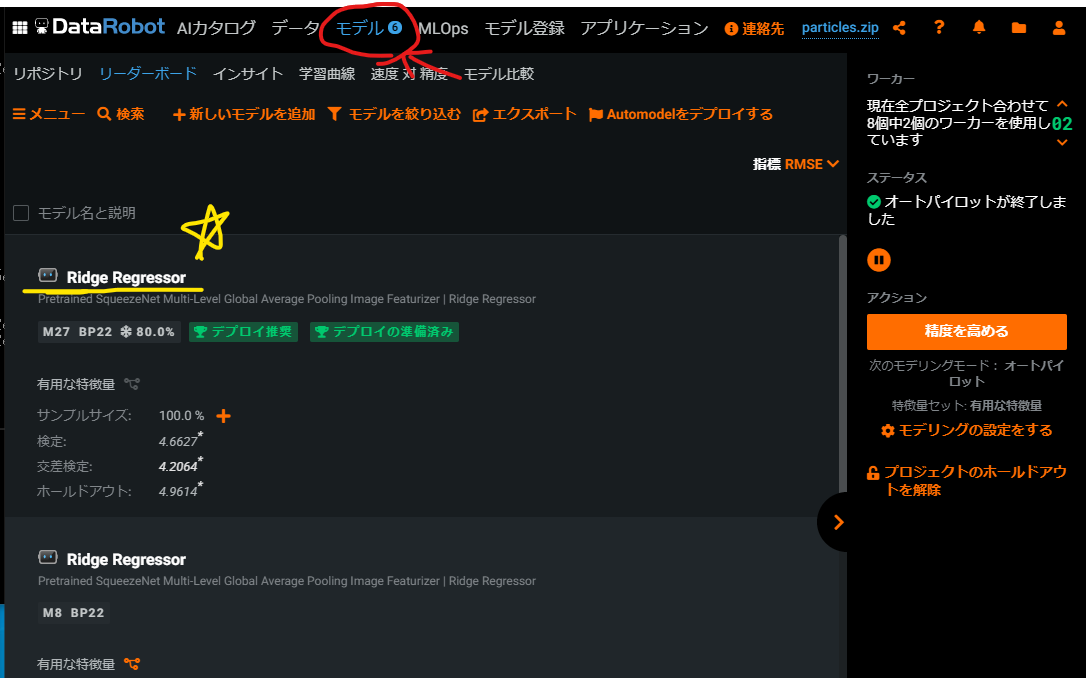
ここで、最も性能の良かった予測モデルがいちばん上に表示されています(図中☆マーク)。
では、クリックして中身を確認してみましょう!
モデルの説明
モデルの名前をクリックすると、まず「説明」タブが表示された状態になっていると思います。
ここでは、予測値を出力するまでのフローチャートが表示されています。
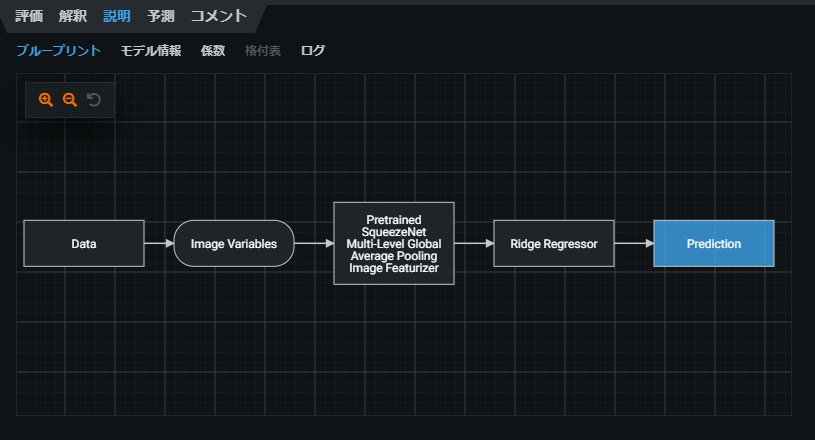
画像の特徴量の抽出にはSqueezeNetと呼ばれるCNNが、回帰にはリッジ回帰が使われているようです。
それぞれの項目をクリックすると、対応するドキュメントへの項目へ飛ぶリンクも表示されます。
超親切ですね。
モデルの性能
さて、気になる性能を見ていきましょう!
「評価」タブを選択することでモデルの精度を確認することができます。
まずはリフトチャートです。
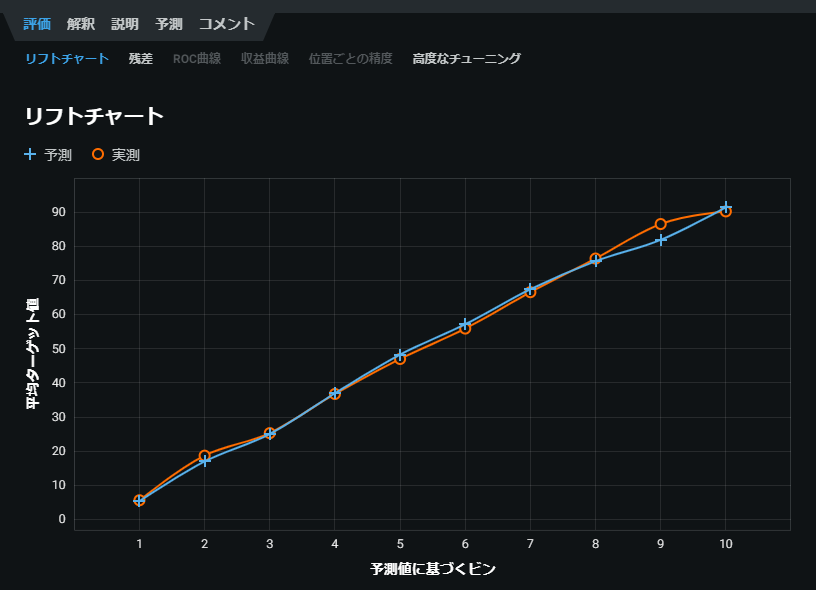
オレンジの線が実測値(真値)で、青色の線が予測値を示し、2つの線がぴったりくっついてるほど精度が高いモデルです。
いい感じですね。
では次はパリティプロット(予測分布)を見ていきましょう。
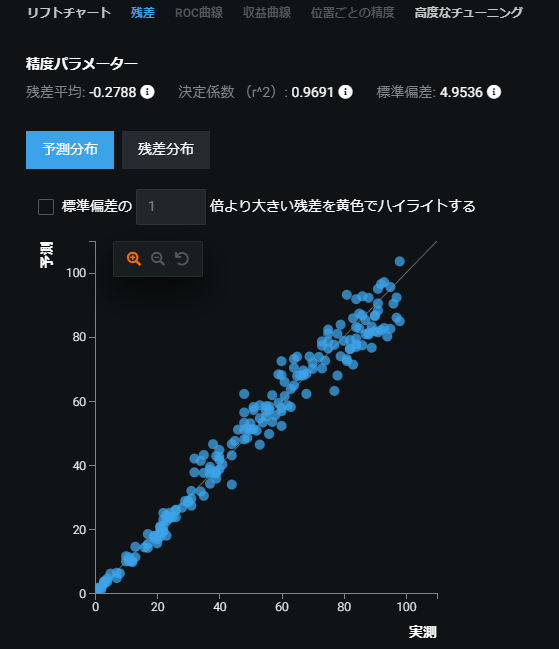
このプロットでは横軸が実測値(真値)、縦軸が予測値を示しています。
y = x の線にプロットが集まっているほどいい予測モデルであることを表します。
決定係数は0.9691となりました。(1に近いほど精度が高い)
つまり……いい感じ!!
ただ、粒子の数が多くなっていくと、予測精度がだんだん悪くなっている様子がわかります。
これは、粒子数が増えるほど互いに接触する粒子の数が増えていくのが原因でしょう。
よりデータ数を増やせばさらに精度は上がるでしょうか……?
また、今回生成した粒子は全て真円ですが、実際の粒子は歪んでいる場合も多くあります。
このモデルを実際に使用するためには、そのあたりも考慮して教師画像を生成する必要がありそうです。
まとめと感想
以上、DataRobotを使った2値化画像からの粒子推定モデルの作成でした。
いかがでしたでしょうか?
感想を言うと、あまりにも簡単すぎてびっくりしました。
この予測モデルは以前自分でも作ったことがありますが、それよりも明らかに速く精度も良いです。
機械学習の民主化はここまで進んでいるんですね……。
ここまで見てくださってありがとうございました。
面白いなと思っていただけたら、ぜひLGTMをおねがいします!
宣伝(バーチャル学会)
12/12(土)にClusterとVRChatという2大バーチャルSNSで開催されるバーチャル学会に参加します。
「機械学習を用いたClusterワールド検索手法の検討」というタイトルでポスター発表をする予定です。
こちらは画像処理ではなく、自然言語処理(検索アルゴリズム)に関する発表ですね!

学会と名はついているものの、だれでもどこからでも自由に参加可能な学会です!
今年は某ウイルスの問題でオンライン学会が増えましたが、VR空間にアバターで登壇するこの形式こそ、新時代の学会にふさわしい形式だと思っています。
私の発表のコアタイムは14:30~15:00です、ご興味のある方はVRChatで握手!
それでは~。