はじめに
いっちょ特許分析でもやってみっかと思ったので、やってみることにしました。
具体的に特許分析というと、例えば下のようなプロットがあります。
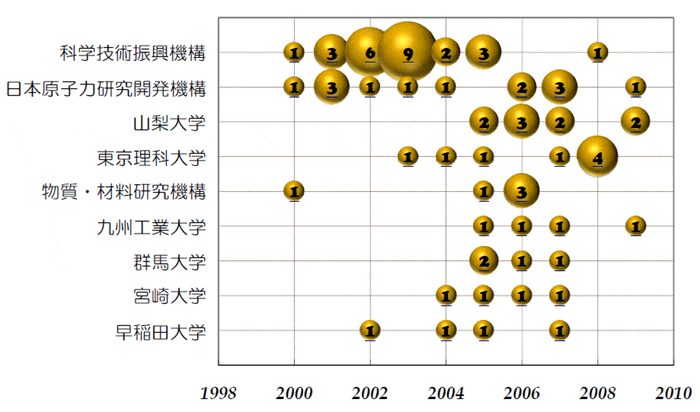
(図はJ-STOREマニュアルより引用)
縦軸が特許出願者を、横軸が特許が出た年を、円の大きさが特許の数を示しており、バブルチャートと呼ばれています。
世の中には有料でこのようなプロットを作ってくれるなにかが存在します。
今回は、無料で使える特許データベースのJ-PlatPatを使って特許文献を検索し、その結果をPythonで処理することでこんな感じのプロットを作っていきたいと思います。
J-PlatPatとは
wikipediaさん曰く、
特許情報プラットフォーム(とっきょじょうほうプラットフォーム、英: Japan Platform for Patent Information)は、独立行政法人工業所有権情報・研修館(INPIT)が運営する特許、実用新案、意匠及び商標等の産業財産権関連の工業所有権公報等を無料で検索・照会可能なデータベースである。
とのことです。
ここで重要なのは使用にお金がかからないということですが、無料なりに多くの制限があり、安易に手を出すと憤死する危険があります。
今回は、このプラットフォームの攻略法が半分、得られたデータの処理の解説が半分といった構成になっています。
データ収集
自分が興味があるのは電池、特に充放電可能ないわゆる二次電池なので、これを検索したいですね。
しかし、例えば普通に"電池"と検索した場合、太陽電池や燃料電池も検索に引っかかります。
ここまでは普通の検索でも起きることです。
Solar cellやFuel cellを"電池"と訳した人類への憎悪を募らせつつ、J-PlatPatの特許・実用新案検索=>論理式入力で以下のように入力します。
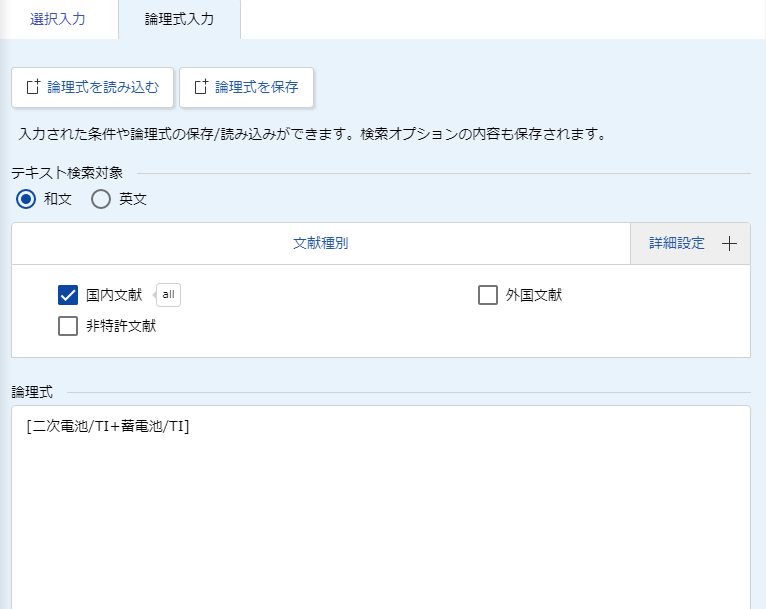
この/TIはタイトルを示していて、この場合は特許タイトルに'二次電池'あるいは'蓄電池'が含まれる特許が検索されます。
論理式を使えば、その他いろいろな指定ができるので世界が広がります。詳細はJ-PlatPatのヘルプを参照しましょう。
この指定では60459件の特許が引っ掛かります。
しかしながら、J-PlatPatの検索結果の表示数は最大3000件なので死にます。
なので発行日を指定して検索します。
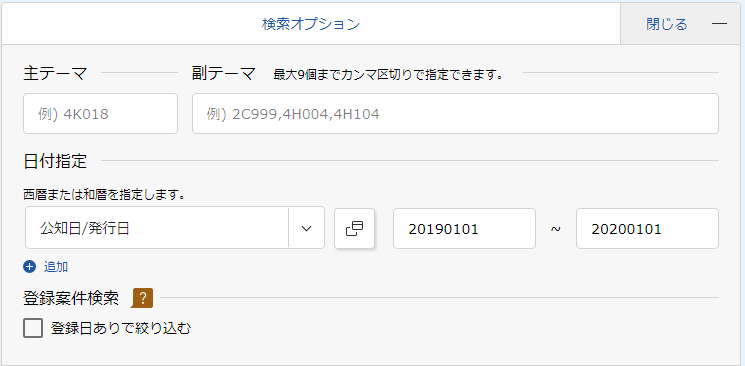
発行日の指定は論理式ではなく検索オプションから行います。
この場合は2019年1月1日から2020年1月1日までの1年間の間に出た特許が表示されます。
これで、以下のように1408件の特許が表示されます(2020/2/4現在)。

ここで1件ごとに特許内容をスクレイピングしたいのですが、それは禁じられています(注意事項参照)。決してやってはいけません。
一覧の"CSV出力"で勘弁してやるか……と思いますよね。では押しましょう。
CSV出力を行うには、100件以下に絞り込んでください。
はい死にました。この記事はこれで終わりです。
嘘です。焦らずに"一覧印刷"を押しましょう。
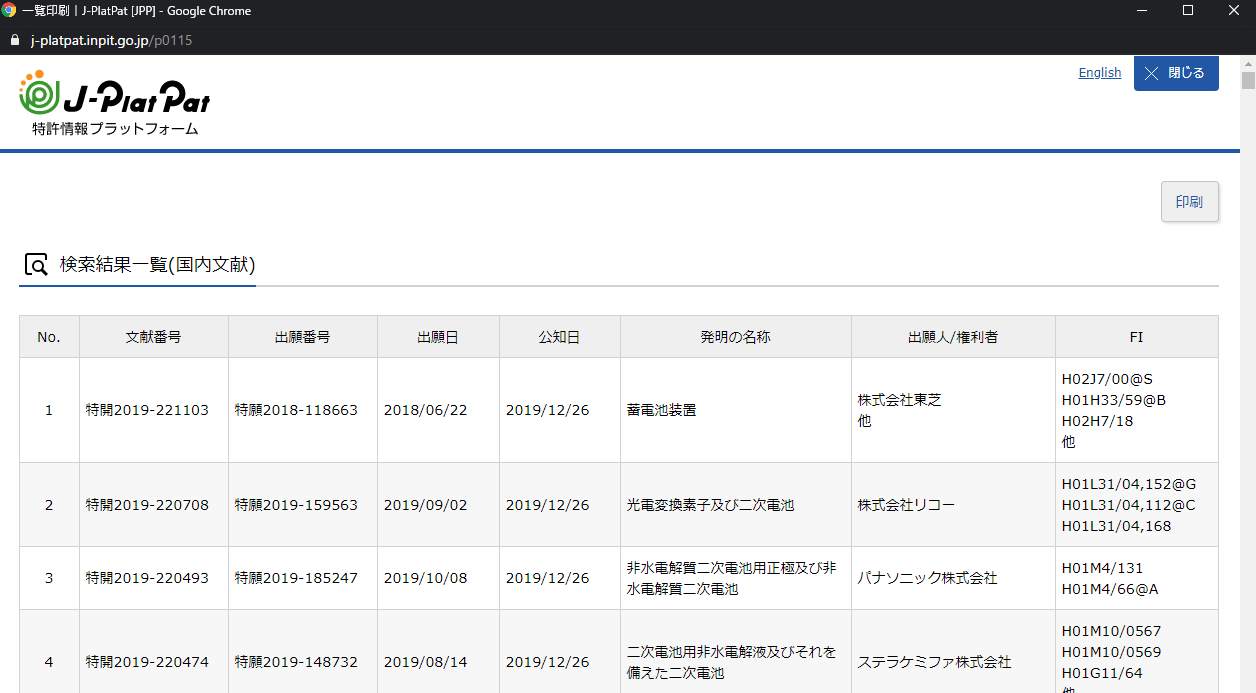
すると、上のように"一覧印刷|J-PlatPat[JPP]"というウィンドウがポップアップします。この画面には、1408件すべての特許が含まれています。
印刷ではなく、右クリックをしてHTMLファイルを保存します。
これで2019年の特許データ取得は完了です。
あとは適当に発行年度をずらしつつ、2018, 2017年...と特許一覧のHTMLを手動で取得していきます。
今回は2005~2019年の15年分のデータを取得しました。
虚無感を感じる作業ですが実際そんなに手間でもなく、10分ぐらいで終わります。
HTMLからCSVへの変換
PythonのBeautifulSoupを使えば、HTMLのテーブルの中身をCSVに変換するのは簡単です。
下のようにちょちょいっと。
HTMLファイルは./htmlから読み込み、CSVファイルを./csvに書き込みます。
from bs4 import BeautifulSoup
import re
import glob
import pandas as pd
path = glob.glob('./html/*.html')
for p in path:
name = p.replace('.html','').replace('./html\\','')
html = open(p,'r',encoding="utf-8_sig")
soup = BeautifulSoup(html,"html.parser")
tr = soup.find_all('tr')
columns = [i.text.replace('\n','') for i in tr[0].find_all('th')]
df = pd.DataFrame(index=[],columns=columns[1:])
for l in tr[1:]:
lines = [i.text for i in l.find_all('td')]
lines = [i.replace('\n','') if n != 6 else re.sub(r'[\n]+', ",", i) for n,i in enumerate(lines)]
lines = pd.Series(lines, index=df.columns)
df = df.append(lines,ignore_index=True)
df.to_csv('./csv/'+name+'.csv', encoding='utf_8_sig', index=False)
手動でローカルに保存したHTMLファイルの処理をしているだけなので、J-PlatPatには一切アクセスしません。セーフです。
得られたデータフレームの一部を以下に示します(patent2005.csv)
こんな感じのCSVが2005~2019年の15個保存されます。
J-PlatPatがCSVの全件出力に対応してくれれば必要ない作業です
| 文献番号 | 出願番号 | 出願日 | 公知日 | 発明の名称 | 出願人/権利者 | FI |
|---|---|---|---|---|---|---|
| 再表2005/124920 | 特願2006-514740 | 2005/06/14 | 2005/12/29 | 鉛蓄電池 | パナソニック株式会社 | ,C22C11/00,C22C11/02,C22C11/06,他, |
| 再表2005/124899 | 特願2006-514659 | 2005/03/09 | 2005/12/29 | 二次電池およびその製造方法 | パナソニック株式会社 | ,H01M2/16@M,H01M4/02@B,H01M4/02@Z,他, |
| 再表2005/124898 | 特願2006-514732 | 2005/06/13 | 2005/12/29 | リチウム二次電池用正極活物質粉末 | AGCセイミケミカル株式会社 | ,H01M4/02@C,H01M4/36@E,H01M4/36,他, |
| 再表2005/122318 | 特願2006-514434 | 2005/05/18 | 2005/12/22 | 非水電解液およびそれを用いたリチウム二次電池 | 宇部興産株式会社 | ,H01M4/02@C,H01M4/02@D,H01M4/36,他, |
| 特開2005-353584 | 特願2005-140521 | 2005/05/13 | 2005/12/22 | リチウムイオン二次電池とその製造法 | パナソニック株式会社 他 | ,H01M2/16@P,H01M4/02,101,H01M4/02,108,他, |
バブルチャートの作成
バブルチャートを作るうえで、対象の出願者(企業)をどのように選ぶかという問題があります。
今回は、それぞれの年度での特許出願数トップ10の企業を引っ張ってくると、ちょうど30社になったので、そのようにします。
以下のようにデータを整理します。
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import glob
import pandas as pd
import collections
import numpy as np
import seaborn as sns
path = glob.glob('./csv/*.csv')
app_top10_dic = {} #それぞれの年度のTOP10企業と出願数
app_total_dic = {} #それぞれの年度の全ての企業と出願数
app_all = [] #バブルチャートの対象となる企業のリスト
for p in path:
name = p.replace('.csv',' ').replace('./csv\\patent','').replace(' ','')
df = pd.read_csv(p)
app_list = df['出願人/権利者']
app_list = [i.rstrip('他').replace(' ','').replace('\u3000',' ') for i in app_list]
app_set = collections.Counter(app_list)
app_top10 = app_set.most_common()[:10]
app_all.extend([i[0] for i in app_top10])
app_top10_dic[name] = app_top10
app_total = app_set.most_common()
app_total_dic[name] = app_total
app_all = list(set(app_all))
列に出願者(企業)、行に出願年度を取った行列を作ります。
まずは以下のように空の行列(df)を作ってから、
years = list(app_top10_dic.keys())
df = pd.DataFrame(index=app_all,columns=years).fillna(0)
これに出願数を以下のように加えていきます。
for i in app_total_dic:
dic = app_total_dic[i]
for d in dic:
if(d[0] in app_all):
df[i][d[0]] += d[1]
最終的に、以下のような行列が得られます。
| 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 住友金属鉱山株式会社 | 6 | 14 | 7 | 13 | 2 | 7 | 15 | 18 | 16 | 25 | 35 | 54 | 56 | 60 | 61 |
| 古河電池株式会社 | 46 | 40 | 34 | 41 | 33 | 31 | 23 | 9 | 12 | 13 | 11 | 7 | 11 | 11 | 13 |
| 大日本印刷株式会社 | 4 | 14 | 12 | 0 | 5 | 9 | 29 | 59 | 5 | 9 | 2 | 1 | 5 | 0 | 0 |
| 三洋電機株式会社 | 181 | 137 | 155 | 120 | 96 | 102 | 120 | 110 | 104 | 180 | 73 | 65 | 26 | 59 | 45 |
| 三星エスディアイ株式会社 | 83 | 138 | 24 | 32 | 38 | 52 | 108 | 57 | 41 | 49 | 69 | 40 | 16 | 14 | 22 |
| : | : | : | : | : | : | : | : | : | : | : | : | : | : | : | : |
| 株式会社半導体エネルギー研究所 | 0 | 0 | 0 | 0 | 0 | 0 | 9 | 7 | 15 | 16 | 22 | 54 | 24 | 12 | 12 |
| 株式会社ジーエス・ユアサコーポレーション | 57 | 20 | 11 | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 株式会社GSユアサ | 43 | 16 | 38 | 40 | 39 | 44 | 56 | 76 | 79 | 75 | 99 | 72 | 83 | 41 | 31 |
| 日立マクセル株式会社 | 29 | 20 | 8 | 28 | 26 | 17 | 39 | 49 | 48 | 46 | 63 | 35 | 39 | 14 | 0 |
| 日本ゼオン株式会社 | 2 | 5 | 5 | 5 | 6 | 16 | 28 | 29 | 43 | 67 | 62 | 45 | 55 | 22 | 2 |
これはpandasのデータフレームとして得られているので、seabornを使えば簡単にヒートマップを作ることができます。
fig = plt.figure(figsize=(6,10),dpi=150)
sns.heatmap(df,square=True,cmap='Reds')
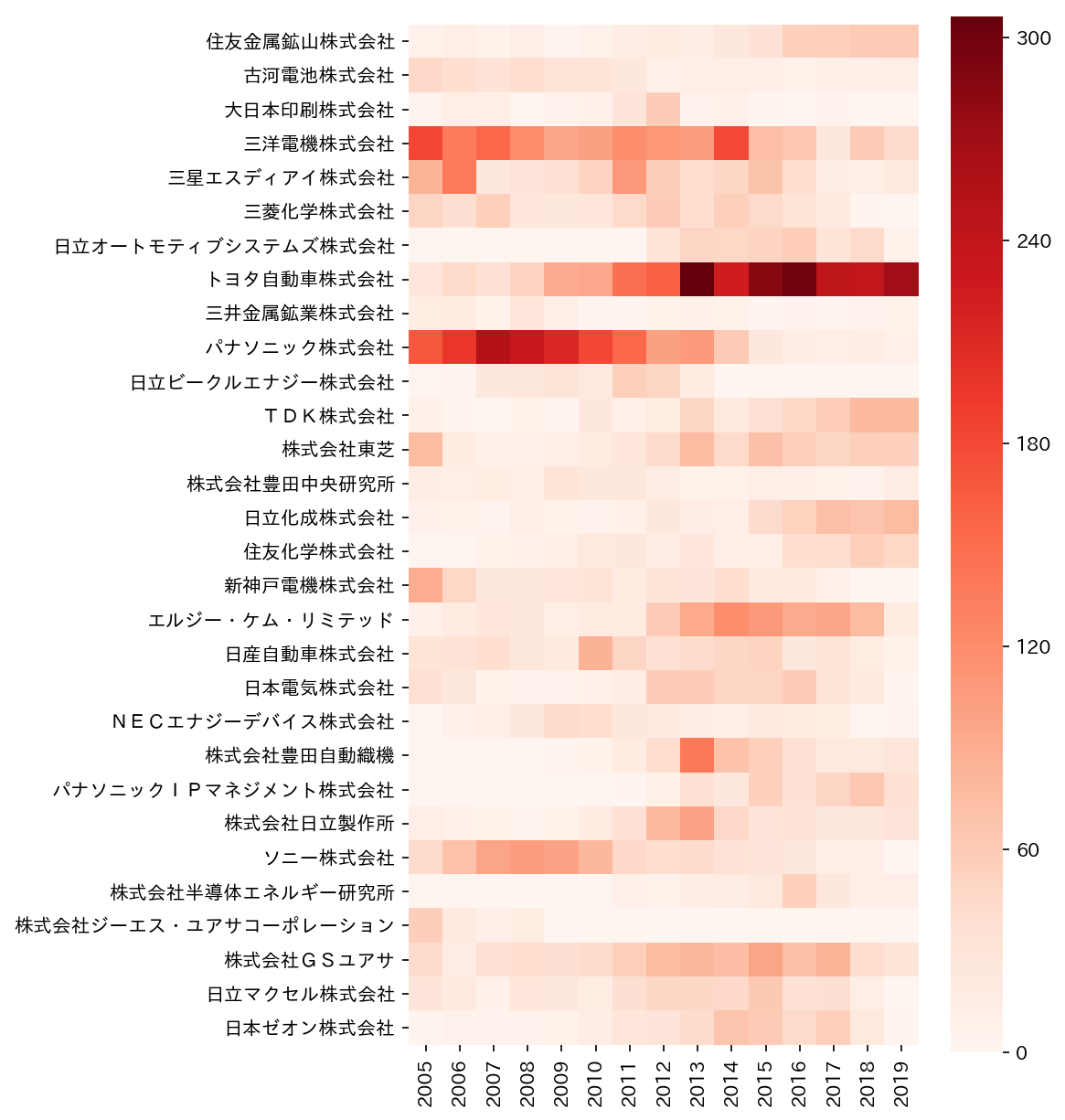
これで十分な気もしますが、バブルチャートも作ります。
これは一発では作れない(はず)なので、自分で頑張ります。
色気づいて凡例も入れます。
fig = plt.figure(figsize=(6,10),dpi=150)
for n,y in enumerate(years):
for m,x in enumerate(app_all[::-1]):
plt.scatter(y,x,s=int(df[y][x]))
size = [100,200,300]
for s in size:
plt.scatter(-100,-100,s=s,facecolor='white',edgecolor='black',label=str(s))
plt.legend(title='Patents', bbox_to_anchor=(1.03, 1),
loc='upper left',labelspacing=1,borderpad=1)
plt.xlim(-1,15)
plt.ylim(-1,30)
plt.xticks(rotation=45)
plt.show()

できました。
確かにヒートマップよりこっちの方が分かりやすい。
全体をざっと見てみると、2013年以降トヨタが強いという発見があります。
色々あった2017年以降も東芝がコンスタントに特許を出してるのは意外。すごいですね。
パナソニックの特許が減っていますが、パナソニックIPマネジメントや三洋電機(子会社)の出願を考慮すればそうでもない?
他にも日立の関連会社が多すぎとか、GSユアサとジーエス・ユアサコーポレーションは何が違うんだとかあるので、グループ企業は統合する必要がありそうですね。
まとめ
そんなわけで、Pythonを使って特許分析にちょっと触れてみました。
J-PlatPatの仕様に振り回されたりPandasの使い方を忘れていたりいろいろありましたが、とりあえずバブルチャートは作れたので目標達成です。
ただ、検索項目の指定が不十分なため、取りこぼした特許がある可能性があります。
この部分はいろいろと試行錯誤が必要そうな感じです。
特許本文まで手に入れば、自然言語解析でいろいろと面白いことができそうな感じですが……。
本文まで参照することを考えればGoogle Patent Public Datasetsを使った方がいいのかも?
とりあえず満足したのでここで終わり!
注意事項
J-PlatPat利用上のご案内の「大量アクセス・ロボットアクセス等に対する制限」には以下のように書かれています。
J-PlatPatは産業財産権情報に関して公共的に利用されるものです。したがって、一般の利用を妨げる可能性がある、データの単純な収集を目的とした大量データのダウンロードや、ロボットアクセス(プログラムによる定期的な自動データ収集)のような行為は禁止させていただいております。
そんなわけで、プログラムによる自動収集はNGです。
やってはいけません。気を付けましょう。
今回のデータ収集が"データの単純な収集を目的とした大量データのダウンロード"に値するかどうかは議論があると思いますが、実際のところ15個のファイルをダウンロードしただけなのでたぶん大丈夫だと思います。