私事ではありますが、2020年5月にコーギーという中型犬をお迎えしました。
愛犬のブログを運営してますので、見てもらえると嬉しいです。

「コーギー関連のツイートをwordcloudで可視化したい!」と思い立ち、以下の4項目を実施しました。
- TwitterAPIでツイートを取得 ← 今回
- 正規表現を用いてツイートを整形
- SudachiPyで形態素単位に分割
- WordCloudで可視化
今回は、「TwitterAPIでツイートを取得」に関して説明していきます。
2021年12月30日
コードを一部修正しました。
対象者
- TwitterAPIのsearch apiでツイートを取得するために、コードを書きたい人
- TwitterAPIで取得したツイートを、pandasのデータフレームに変換したい人
- TwitterAPIのsearch apiのリクエストの上限に困っている人
なお、consumer_key,consumer_secret,access_token,access_secret の4つは、すでに取得できている前提で話を進めます。
ざっくりとした要件定義
Input ... 「Twitter検索のためのクエリ」と「APIキー各種」
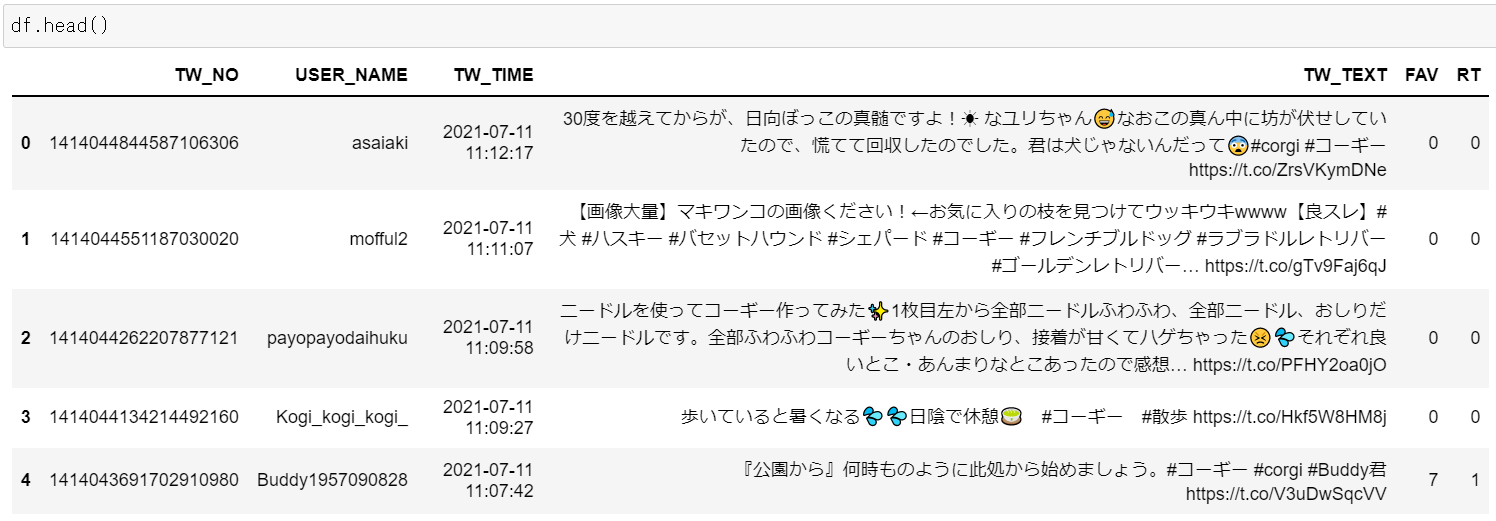
Output ... 以下の6つを列に含む、17,500ツイートのDataFrame
Outputに含まれる要素は、「ツイート番号」「ユーザーネーム」「ツイート時刻」「ツイートのテキスト」「いいねの数」「リツイートの数」になります。
コード
コード全体
import tweepy
import pandas as pd
import datetime
# Setting 280 characters in a column
pd.set_option("display.max_colwidth", 280)
def get_api_value(consumer_key,consumer_secret,access_token,access_secret):
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
return api
def collect_tweet_data(q, api):
'''
ツイッターAPIを使用してデータを収集し、リストを作成する関数
15分で180リクエストという制限があり、理論上は18,000ツイートが取得可能だが、
たまに180リクエストで18,000ツイート取得できずエラーが発生するため、
17500ツイートを取得するよう指定
'''
tweet_data = []
for tweet in tweepy.Cursor(api.search_tweets, q=q, result_type='recent', count=100).items(17500):
tweet_data.append([tweet.id_str,
tweet.user.screen_name,
tweet.created_at+datetime.timedelta(hours=9),
tweet.text.replace('\n',''),
tweet.favorite_count,tweet.retweet_count])
return tweet_data
def create_tweets_df(q,api):
tweet_data = collect_tweet_data(q=q,api=api)
# 取得する列名を定義する
columns_name=["TW_NO","USER_NAME","TW_TIME","TW_TEXT","FAV","RT"]
df=pd.DataFrame(tweet_data,columns=columns_name)
return df
# 自身で取得した値を代入してください。
consumer_key = 'xxxxxxxxxxxxx'
consumer_secret = 'xxxxxxxxxxxxxxx'
access_token = 'xxxxxxxxxxx'
access_secret = 'xxxxxxxxxxxxxx'
api=get_api_value(consumer_key,consumer_secret,access_token,access_secret)
q = f"#コーギー OR コーギー exclude:retweets -filter:replies"
df = create_tweets_df(q, api)
コードの解説
まず、事前に取得したキーから、apiにアクセスできるようにします。
def get_api_value(consumer_key,consumer_secret,access_token,access_secret):
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
return api
次に、リストでツイートのデータを取得します。
api.searchは15分間で180リクエストを送信することが可能です。
count=100とすることで1リクエストあたり100ツイートを取得できるため、最大で18,000ツイートを1度に取得できます。
しかし、18,000ツイート取得しようとすると180リクエストでは取得できずにエラーを吐いてしまうこともあるので、17,500ツイートの取得にしました。
また、api.searchではjsonフォイルを取得できるため、jsonファイルから必要な情報を抜き出し、リストに加えていきます。
def collect_tweet_data(q, api):
'''
ツイッターAPIを使用してデータを収集し、リストを作成する関数
15分で180リクエストという制限があり、理論上は18,000ツイートが取得可能だが、
たまに180リクエストで18,000ツイート取得できずエラーが発生するため、
17500ツイートを取得するよう指定
'''
tweet_data = []
for tweet in tweepy.Cursor(api.search_tweets, q=q, result_type='recent', count=100).items(17500):
tweet_data.append([tweet.id_str,
tweet.user.screen_name,
tweet.created_at+datetime.timedelta(hours=9),
tweet.text.replace('\n',''),
tweet.favorite_count,tweet.retweet_count])
return tweet_data
残りのリクエスト数が気になる場合は、こちらのコードで確認できます。
# input
print("API.search")
print(api.rate_limit_status()["resources"]["search"]["/search/tweets"])
# output
API.search
{'limit': 180, 'remaining': 170, 'reset': 1626095196}
これは、上限が180リクエストで、残りが170という意味になります。
最後に、リストのデータをDataFrameに格納します。
def create_tweets_df(q,api):
tweet_data = collect_tweet_data(q=q,api=api)
# 取得する列名を定義する
columns_name=["TW_NO","USER_NAME","TW_TIME","TW_TEXT","FAV","RT"]
df=pd.DataFrame(tweet_data,columns=columns_name)
return df
これら3つの関数を用いて各種apiキーとクエリを以下のように入力すると、ツイートの情報が含まれたDataFrameを取得できます。
# 自身で取得した値を代入してください。
consumer_key = 'xxxxxxxxxxxxx'
consumer_secret = 'xxxxxxxxxxxxxxx'
access_token = 'xxxxxxxxxxx'
access_secret = 'xxxxxxxxxxxxxx'
api=get_api_value(consumer_key,consumer_secret,access_token,access_secret)
q = f"#コーギー exclude:retweets -filter:replies"
df = create_tweets_df(q, api)
outputは以下の通りです。
まとめ
この記事では、TwitterAPIでツイートを取得するコードを見ていきました。
次は、正規表現を用いてツイートの形を整えたいと思います。
こちらの記事で説明してますので、興味があれば見てもらえると嬉しいです。

参考文献
twitterのデータ探索に関わるtweepyの基本機能の解説
【2021年7月執筆】Twitterでのsearch APIの制約について