私事ではありますが、2020年5月にコーギーという中型犬をお迎えしました。
愛犬のブログを運営してますので、見てもらえると嬉しいです。

「コーギー関連のツイートをwordcloudで可視化したい!」と思い立ち、以下の4項目を実施しました。
- TwitterAPIでツイートを取得
- 正規表現を用いてツイートを整形 ← 今回
- SudachiPyで形態素単位に分割
- WordCloudで可視化
今回は、「正規表現を用いてツイートを整える」に関して説明していきます。
対象者
- ツイートから不要な部分を取り除くために、コードを書きたい人
- 🐶のような絵文字を上手く取り除けず、困っている人
ざっくりとした要件定義
Input ... ツイート内容のDataFrame
Output ... 自然言語処理のために整形済みのツイート内容
Inputは、こちらの記事で取得したデータフレーム(以下)になります。
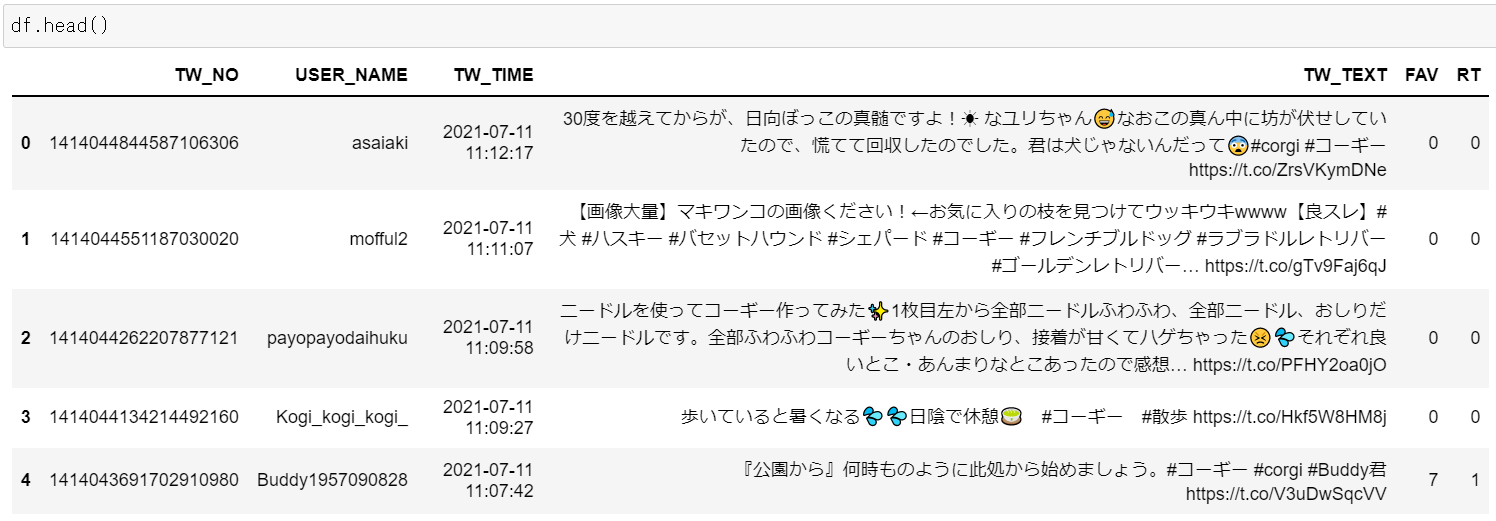
Outputは、テキスト内容を整形し、以下のようになります。

コード
コード全体
import pandas as pd
pd.set_option("display.max_colwidth", 280)
import emoji
def remove_emoji(text):
return emoji.get_emoji_regexp().sub(u'', text)
def format_df_text(text_col,df):
'''
ツイートを整形する
(形態素解析でsudachiを使用予定のため、textの修正が少ない)
'''
df['temp'] = df[text_col].replace(r'https?://[w/:%#$&?()~.=+-…]+', '', regex=True) #画像へのリンクを削除
df['temp'] = df['temp'].replace(r'@[w/:%#$&?()~.=+-…]+', '', regex=True) #'@'によるメンションを削除
df['temp'] = df['temp'].replace(r'#(\w+)', '', regex=True) #ハッシュタグ(半角)を削除
df['temp'] = df['temp'].replace(r'#(\w+)', '', regex=True) #ハッシュタグ(全角)を削除
df['temp'] = df['temp'].apply(lambda x: remove_emoji(x)) #🐶のような絵文字を削除
return df['temp']
df['TW_TEXT_mod'] = format_df_text('TW_TEXT',df)
コードの解説
まずは、🐶のような絵文字を削除します。
emojiライブラリをインストールし、絵文字を削除するためのremove_emoji関数を作成しました。
def remove_emoji(text):
return emoji.get_emoji_regexp().sub(u'', text)
なお、emojiライブラリはpipでインストールできます。
pip install emoji --upgrade
詳細はこちらになります。
最初はこの記事のようにencodeとdecodeで上手く処理しようと試みたのですが、絵文字だけでなく日本語テキストも削除されてしまいました。
「ライブラリをあまりインストールしたくない」と思うかもしれませんが、素直にemojiライブラリを使用することをおススメします。
次に、さきほどのremove_emoji関数を使用し、テキスト全体を整形する関数を作成します。
def format_df_text(text_col,df):
'''
ツイートを整形する
(形態素解析でsudachipyを使用予定のため、textの修正が少ない)
'''
df['temp'] = df[text_col].replace(r'https?://[w/:%#$&?()~.=+-…]+', '', regex=True) #画像へのリンクを削除
df['temp'] = df['temp'].replace(r'@[w/:%#$&?()~.=+-…]+', '', regex=True) #'@'によるメンションを削除
df['temp'] = df['temp'].replace(r'#(\w+)', '', regex=True) #ハッシュタグ(半角)を削除
df['temp'] = df['temp'].replace(r'#(\w+)', '', regex=True) #ハッシュタグ(全角)を削除
df['temp'] = df['temp'].apply(lambda x: remove_emoji(x)) #🐶のような絵文字を削除
return df['temp']
次の章でsudachipyという形態素解析器を使用しますが、sudachipyは自動で正規表記化(たとえば、'summer'という単語を「サマー」と認識)してくれるので、前処理は少なめにしています。
また、ハッシュタグを全角で記入しているケースもあったので、ハッシュタグの半角・全角ともに削除するようコードを書きました。
おそらくですが、ハッシュタグ関連のコードは1行にまとめられると思います。
(正規化が苦手なので諦めました。)
最後に、これらの関数を使用し、テキストを整形します。
df['TW_TEXT_mod'] = format_df_text('TW_TEXT',df)
まとめ
この記事では、正規表現を用いてツイートを整形するコードを見ていきました。
次は、形態素解析器を用いて、ツイートを単語に分割していきたいと思います。
こちらの記事で説明してますので、興味があれば見てもらえると嬉しいです。
